Redes Bayesianas no pacote FuzzyClass
UFPB - PPGMDS
Introdução
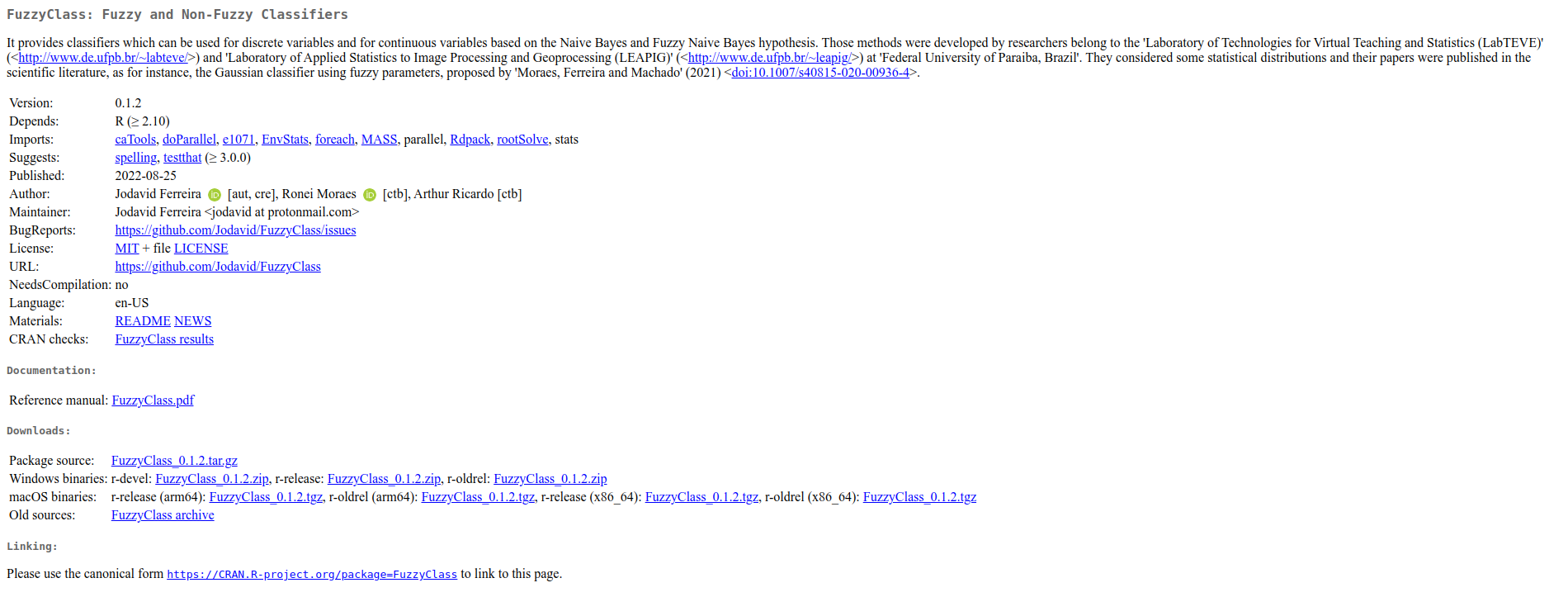
Página do FuzzyClass no CRAN.R
Introdução
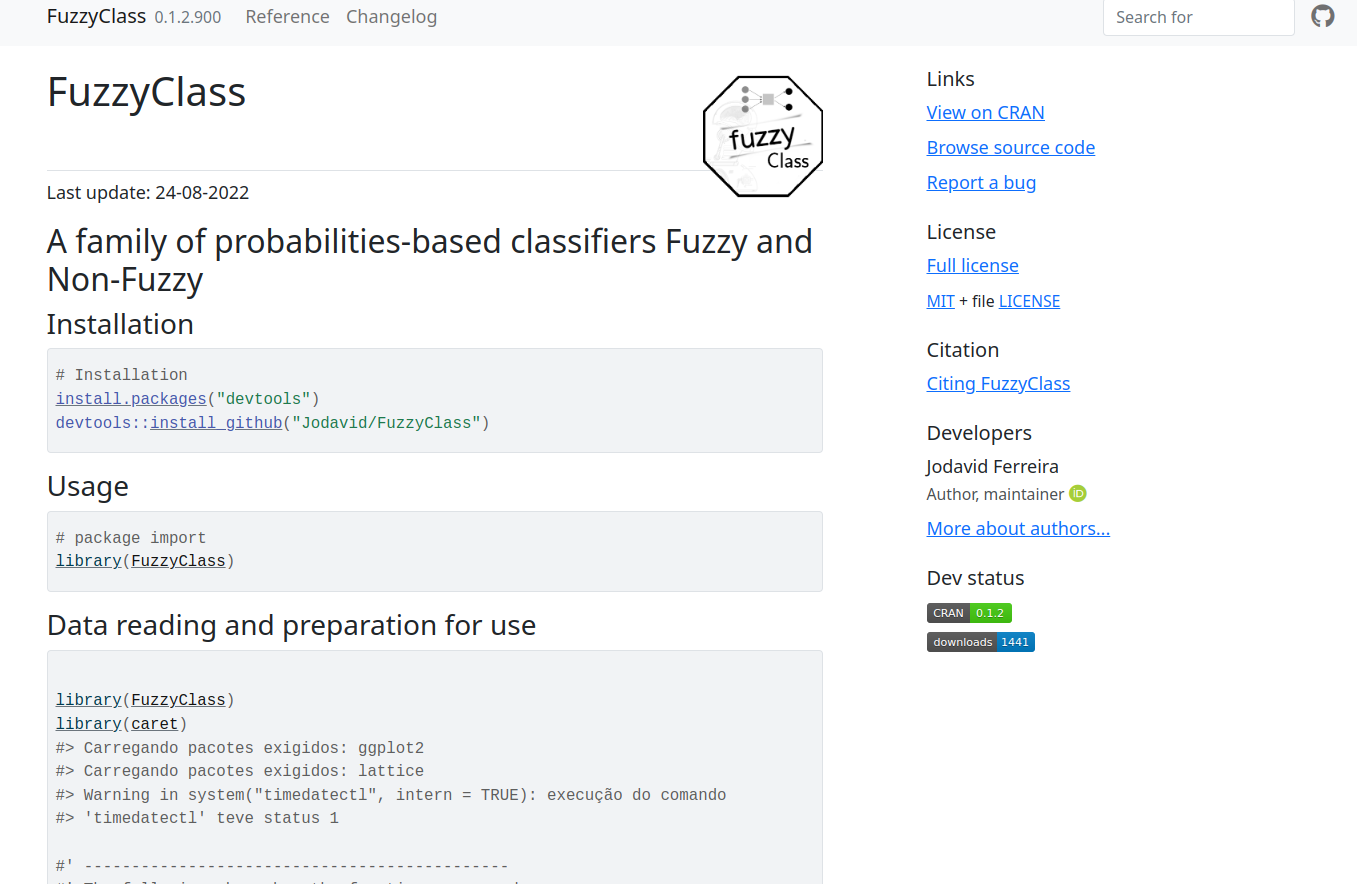
Página do FuzzyClass no GitHub
Compreensão da Problemática
- É preciso ter uma visão clara do problema de negócio a ser resolvido.
Métodos de Tomada de Decisão
- Métodos de tomada de decisão;
- Classificação;
- Metodos supervisionados;
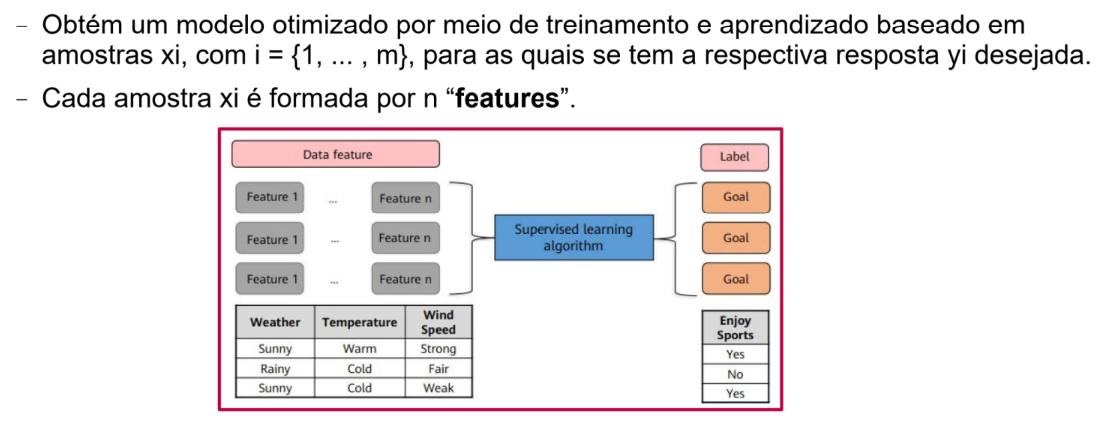
Dados Tabulados (Tidy Data)
Há três regras inter-relacionadas que tornam um conjunto de dados arrumados (tidy):
Cada
variáveldeve ter sua própria coluna.Cada
observaçãodeve ter sua própria linha.Cada
valordeve ter sua própria célula.

Exemplos no R?
R - Instalação do Pacote
- Forma 1:
- Forma 2:
R - Lendo as funções do Pacote
- Forma 1:
R - Base de dados
DataSet utilizado: iris
link: https://www.kaggle.com/datasets/saurabh00007/iriscsv
Problemática: Através dos comprimentos das Sépalas e Pétalas, classificar corretamente as flores.
R - Base de dados
DataSet utilizado: iris
O Banco é composto por 6 variáveis que são detalhados a seguir.
Variáveis Existentes:
- Id: Valor único por linha
- SepalLengthCm: Comprimento da Sépala em cm
- SepalWidthCm: Largura da Sépala em cm
- PetalLengthCm: Comprimento da Pétala em cm
- PetalWidthCm: Largura da Pétala em cm
- Species: Tipo da espécie da flor
R - Lendo a Base de dados
Se o arquivo estiver em .csv, é possível ler a base de dados da seguinte forma
# Lendo Base de dados
dados <- read.csv("dataset/iris.csv",sep = ",")
# Visualizando um cabeçalho dos dados
dados |>
head(n = 10) Id SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
1 1 5.1 3.5 1.4 0.2 Iris-setosa
2 2 4.9 3.0 1.4 0.2 Iris-setosa
3 3 4.7 3.2 1.3 0.2 Iris-setosa
4 4 4.6 3.1 1.5 0.2 Iris-setosa
5 5 5.0 3.6 1.4 0.2 Iris-setosa
6 6 5.4 3.9 1.7 0.4 Iris-setosa
7 7 4.6 3.4 1.4 0.3 Iris-setosa
8 8 5.0 3.4 1.5 0.2 Iris-setosa
9 9 4.4 2.9 1.4 0.2 Iris-setosa
10 10 4.9 3.1 1.5 0.1 Iris-setosaR - Tratamento das variáveis
Para facilitar, criar uma base em paralelo apenas com as variáveis que vai utilizar na aplicação do modelo.
Neste caso vamos retirar a primeira coluna de Id, ela não é necessária neste caso.
- Forma 1:
- Forma 2:
R - Classif. existentes no FuzzyClass
Abaixo são descritos os métodos de acordo com as abordagens de Zadeh e Buckley
| Fuzzy - Zadeh | Fuzzy Buckley |
|---|---|
| FuzzyBetaNaiveBayes | ExpNBFuzzyParam |
| FuzzyBinomialNaiveBayes | GauNBFuzzyParam |
| FuzzyExponentialNaiveBayes | PoiNBFuzzyParam |
| FuzzyGammaNaiveBayes | |
| FuzzyGaussianNaiveBayes | |
| FuzzyPoissonNaiveBayes | |
| FuzzyTrapezoidalNaiveBayes | |
| FuzzyTriangularNaiveBayes |
e o FuzzyNaiveBayes que trabalha com dados qualitativos de não assume dist. de probabilidade.
Help do Fuzzy Class
ou
Página do FuzzyClass no CRAN.R
R - Execução dos métodos
Vamos selecionar um método de Zadeh e um de Buckley para execução, pois o procedimento com os outros são iguais.
Vamos utilizar:
FuzzyTrapezoidalNaiveBayes;
e
FuzzyBetaNaiveBayes;
R -Divindo a base
R -Divindo a base
Fazendo transformação de dados para utilização da Beta
set.seed(2)
dados_editado_beta <- dados_editado
for(i in 1:(ncol(dados_editado)-1)) dados_editado_beta[,i] <- dados_editado_beta[,i]/ max(dados_editado_beta[,i])
# Separando entre treinamento e teste
split <- caTools::sample.split(t(dados_editado_beta[,1]), SplitRatio = 0.7) # 70% para o Treinamento
# -----
TrainB <- subset(dados_editado_beta, split == "TRUE")
TestB <- subset(dados_editado_beta, split == "FALSE")
# ---------------- SepalLengthCm SepalWidthCm PetalLengthCm PetalWidthCm Species
1 0.6455696 0.7954545 0.2028986 0.08 Iris-setosa
2 0.6202532 0.6818182 0.2028986 0.08 Iris-setosa
3 0.5949367 0.7272727 0.1884058 0.08 Iris-setosa[1] 150[1] 105[1] 45R - Aplicando o treinamento dos algoritmos
- Fuzzy Trapezoidal Naive Bayes Naive Bayes:
- Fuzzy Beta Naive Bayes:
R - Fazendo a predição dos dados
Criando uma nova variável sem a coluna verdadeira da classificação com a parte de Test
- Fuzzy Trapezoidal Naive Bayes:
- Fuzzy Beta Naive Bayes:
R - Verificando a matriz de confusão
Verificando a eficácia dos algoritmos utilizados nesse estudo
- Fuzzy Gamma Naive Bayes:
# --------------------------------------------------
# Fuzzy Trapezoidal Naive Bayes
caret::confusionMatrix(classificacao, factor(Test[,5]))Confusion Matrix and Statistics
Reference
Prediction Iris-setosa Iris-versicolor Iris-virginica
Iris-setosa 16 2 0
Iris-versicolor 0 11 1
Iris-virginica 0 1 14
Overall Statistics
Accuracy : 0.9111
95% CI : (0.7878, 0.9752)
No Information Rate : 0.3556
P-Value [Acc > NIR] : 1.048e-14
Kappa : 0.8661
Mcnemar's Test P-Value : NA
Statistics by Class:
Class: Iris-setosa Class: Iris-versicolor
Sensitivity 1.0000 0.7857
Specificity 0.9310 0.9677
Pos Pred Value 0.8889 0.9167
Neg Pred Value 1.0000 0.9091
Prevalence 0.3556 0.3111
Detection Rate 0.3556 0.2444
Detection Prevalence 0.4000 0.2667
Balanced Accuracy 0.9655 0.8767
Class: Iris-virginica
Sensitivity 0.9333
Specificity 0.9667
Pos Pred Value 0.9333
Neg Pred Value 0.9667
Prevalence 0.3333
Detection Rate 0.3111
Detection Prevalence 0.3333
Balanced Accuracy 0.9500R - Verificando a matriz de confusão
- Fuzzy Gaussian Naive Bayes with Fuzzy Parameters:
# --------------------------------------------------
# Fuzzy Beta Naive Bayes
caret::confusionMatrix(classificacao_Beta, factor(TestB[,5]))Confusion Matrix and Statistics
Reference
Prediction Iris-setosa Iris-versicolor Iris-virginica
Iris-setosa 16 0 0
Iris-versicolor 0 11 2
Iris-virginica 0 3 13
Overall Statistics
Accuracy : 0.8889
95% CI : (0.7595, 0.9629)
No Information Rate : 0.3556
P-Value [Acc > NIR] : 1.581e-13
Kappa : 0.833
Mcnemar's Test P-Value : NA
Statistics by Class:
Class: Iris-setosa Class: Iris-versicolor
Sensitivity 1.0000 0.7857
Specificity 1.0000 0.9355
Pos Pred Value 1.0000 0.8462
Neg Pred Value 1.0000 0.9062
Prevalence 0.3556 0.3111
Detection Rate 0.3556 0.2444
Detection Prevalence 0.3556 0.2889
Balanced Accuracy 1.0000 0.8606
Class: Iris-virginica
Sensitivity 0.8667
Specificity 0.9000
Pos Pred Value 0.8125
Neg Pred Value 0.9310
Prevalence 0.3333
Detection Rate 0.2889
Detection Prevalence 0.3556
Balanced Accuracy 0.8833Conclusões
O que podemos concluir de forma breve até esse momento com o estudo:
- Pelo pacote FuzzyClass é possível fazer classificação de dados, utilizando várias abordagens propostas;
- Existem abordagens de classificação utilizando probabilidades fuzzy na na proposta de Zadeh e de Buckley;
- O pacote encontra-se disponível no CRAN para toda a comunidade utilizar;
- É possível fazer estimação dos parâmetros, assim como predição das classes para novas observações.
OBRIGADO!
Slide produzido com quarto
Utilização do Pacote FuzzyClass - FuzzyClass