import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation
model = Sequential ()
# Adiciona ao modelo uma camada densamente conectada
# com 6 unidades e forma de entrada 3 :
model.add(Dense(6, input_shape=(10,)))
# Adiciona outra camada com 8 unidades,
# cada uma conectada aos 6 outputs da camada anterior
model.add(Dense(8))
# Última camada com 3 unidades,
# cada uma conectada aos 3 outputs da camada anterior
model.add(Dense(3, activation='softmax'))Redes Neurais
Introdução ao TensorFlow e Keras
Prof. Jodavid Ferreira
UFPE
Frameworks de Redes Neurais

Qual utilizar? O que eles possuem em comum? E o que os diferencia?
Frameworks de Redes Neurais
Seguindo a ordem anterior:
TensorFlow: Desenvolvido pela Google no ano de 2015, é um dos mais populares e utilizados. Possui uma grande comunidade e é utilizado em diversos projetos de pesquisa e produção. Entretando para ser programado em python exige um pouco mais de conhecimento avançado na linguagem e profundade de conhecimento na biblioteca.
Keras: Desenvolvido por François Chollet no ano de 2015, é uma API de alto nível para redes neurais. É muito utilizado por sua simplicidade e facilidade de uso. Atualmente faz parte do TensorFlow. Utilizando o Keras, é possível criar redes neurais de forma muito mais simples e intuitiva.
MXNet: Desenvolvido pela Apache no ano de 20015, é um framework de deep learning que suporta diversas linguagens de programação, como Python, C++, R, Scala, Julia, Perl e Go. É muito utilizado em projetos de pesquisa e produção, entretanto não é mais utilizada no estado da arte, como TensorFlow e PyTorch.
Frameworks de Redes Neurais
PyTorch: Desenvolvido pelo Facebook no ano de 2016, é um dos frameworks mais utilizados atualmente. Possui uma grande comunidade e é utilizado em diversos projetos de pesquisa e produção. É muito utilizado por sua simplicidade e facilidade de uso, entretanto, ainda exige uma certa profundidade de conhecimento em programação maior que o Keras.
Caffe: Desenvolvido pela Berkeley Vision and Learning Center (BVLC) no ano de 2014, e é recomendado quando estamos no campo de sistemas embarcados, pois é mais leve que os outros frameworks. Em 2017/ 2018 foi lançado o Caffe2, que é uma versão mais atualizada e com mais recursos e atualmente ele está embutido no PyTorch.
Mindspore: Desenvolvido pela Huawei, é um framework de deep learning que suporta diversas linguagens de programação, como Python.
Theano: Desenvolvido pela Universidade de Montreal no ano de 2007, é um framework de deep learning que suporta diversas linguagens de programação, como Python. Entretanto, ele não é mais mantido e atualizado, sendo substituído pelo TensorFlow e PyTorch.
TensorFlow
![]()
TensorFlow
- Sistema de aprendizado de máquina de segunda geração do Google Brain
- Os cálculos são expressos como gráficos de fluxo de dados com estado
- Capacidades de diferenciação automática
- Algoritmos de otimização: baseados em gradiente e gradiente proximal
- Portabilidade de código (CPUs, GPUs, em desktops, servidores ou plataformas de computação móvel)
- A interface em Python é a preferida (também existem em Java, C e Go)
- Instalação através de: pip, Docker, Anaconda, a partir de fontes
- Licença de código aberto Apache 2.0
TensorFlow
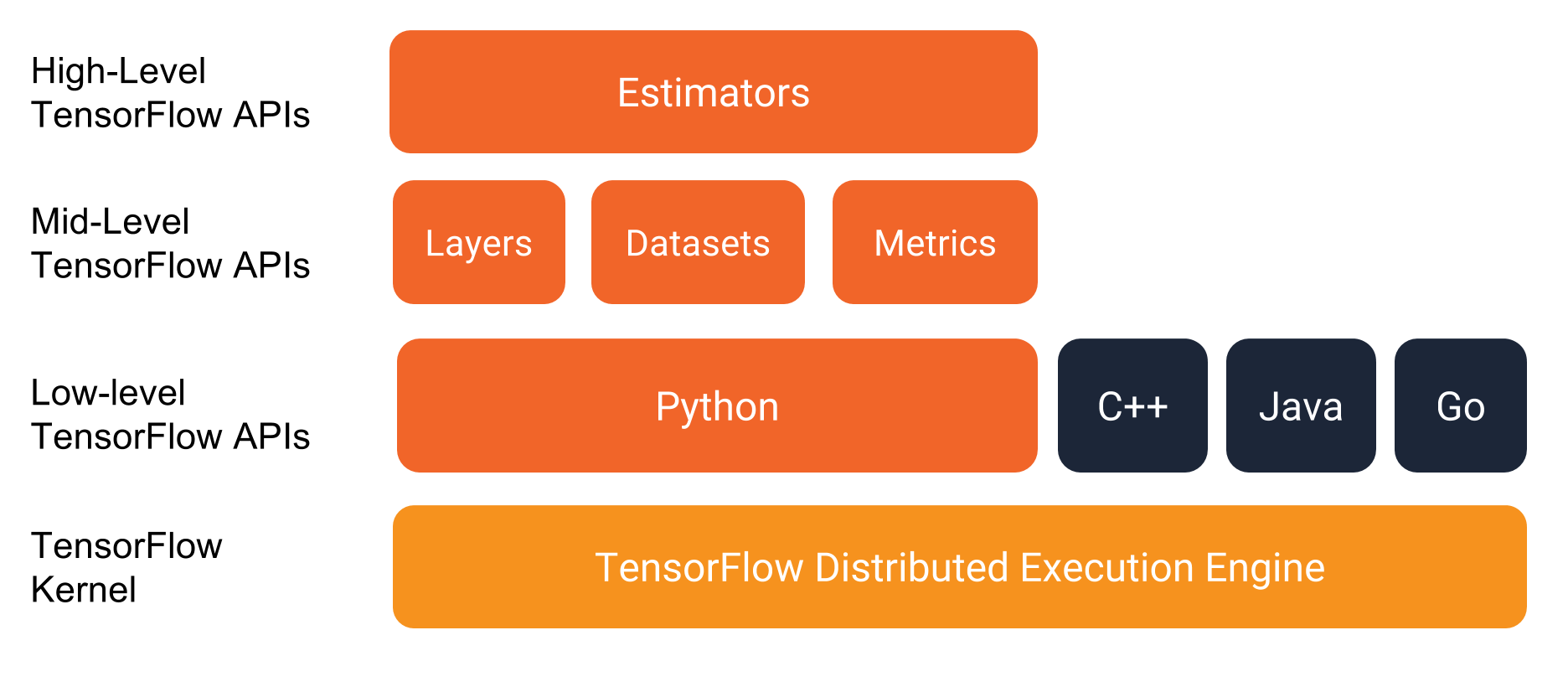
- Tensorflow é uma estrutura computacional para construir modelos de aprendizado de máquina
- API de alto nível e orientada a objetos (tf.estimator)
- Bibliotecas para componentes comuns de modelos (tf.layers/tf.losses/tf.metrics)
- APIs de baixo nível (TensorFlow)
TensorFlow
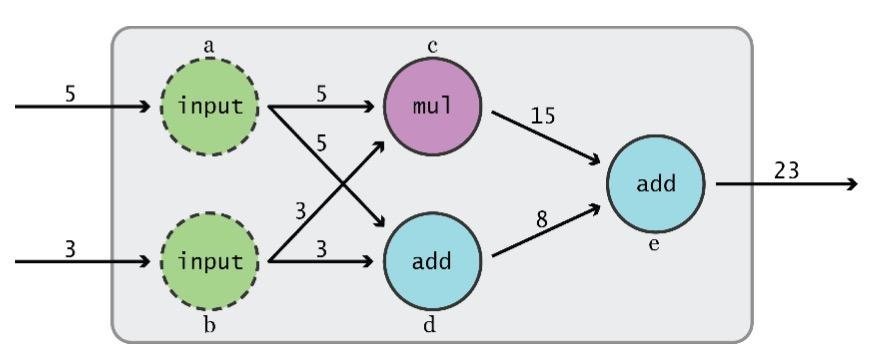
Gráfico de fluxo de dados TensorFlow
- TensorFlow 1 separa a definição dos cálculos de sua execução
Fase 1: montar um gráfico
Fase 2: usar uma sessão para executar operações no gráfico.
Isso não é verdade no “modo eager” (padrão no TensorFlow 2)
TensorFlow
O modo eager no TensorFlow 2 é um ambiente de execução que executa operações de TensorFlow imediatamente, sem a necessidade de construir grafos. Ele permite uma programação mais intuitiva e flexível, similar à forma como você escreveria em Python normal. Com o modo eager, cada operação retorna um resultado concreto, ao invés de um objeto gráfico que precisa ser avaliado em uma sessão separada. Isso facilita a depuração, a experimentação e o desenvolvimento interativo de modelos de aprendizado de máquina.
Essa abordagem é mais amigável, especialmente para usuários novos, pois elimina muita da complexidade associada com a construção e manipulação de grafos computacionais. Além disso, o modo eager suporta quase todas as operações disponíveis no modo gráfico do TensorFlow, tornando-o prático para a maioria das aplicações de aprendizado de máquina.
TensorFlow
Em resumo:
Herda do Theano (gráfico de fluxo de dados)
É uma biblioteca python / biblioteca C++
Funcionando em CPU ou GPU NVIDIA CUDA
Plataforma de ponta a ponta (end-2-end) para aprendizado de máquina/aprendizado profundo
Multiplataforma (desktop, web pelo TF.js, mobile pelo TF Lite)
Código aberto com manual do usuário (https://www.tensorflow.org/)
Keras
![]()
Keras
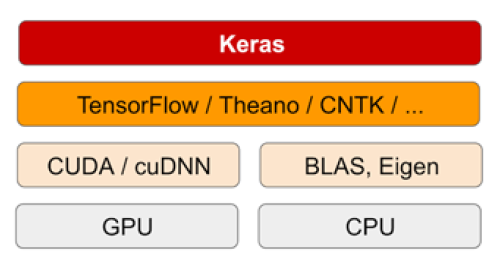
É uma biblioteca do Python
Funciona em cima do TensorFlow ou Theano (Descontinuado)
API de rede neural de alto nível
Funciona perfeitamente em CPU e GPU
Código aberto com manual do usuário (https://keras.io/)
Menos linhas de código necessárias para construir/executar um modelo
Keras
Keras é uma API de alto nível para redes neurais, escrita em Python, desenvolvida com foco em permitir experimentação rápida.
Keras oferece uma API consistente e simples, que minimiza o número de ações necessárias pelo usuário para casos de uso comuns e fornece um feedback claro e acionável em caso de erro do usuário.
Keras é capaz de rodar em cima de vários backends de aprendizado profundo como TensorFlow, CNTK ou Theano. Essa capacidade permite que os modelos Keras sejam portáteis entre todos esses backends.
Keras é uma das frameworks de Aprendizado Profundo mais utilizadas por pesquisadores e agora faz parte da API de Alto Nível oficial do TensorFlow como tf.keras.
Os modelos Keras podem ser treinados em CPUs, Xeon Phi, TPUs do Google e qualquer GPU ou dispositivo habilitado para GPU OpenCL.
Keras é a API de alto nível do TensorFlow para construir e treinar modelos de aprendizado profundo.
Keras
Keras
Vamos construir com Keras?!
Construindo modelos com Keras
A estrutura de dados central do Keras é o Modelo, que é basicamente um contêiner de uma ou mais Camadas.
Existem dois tipos principais de modelos disponíveis no Keras: o modelo Sequencial e a classe Modelo, sendo esta última usada para criar modelos avançados.
O tipo mais simples de modelo é o modelo Sequencial, que é uma pilha linear de camadas. Cada camada é adicionada ao modelo usando o método
.add()do objeto do modelo Sequencial.O modelo precisa saber qual forma de entrada ele deve esperar. A primeira camada em um modelo Sequencial (e somente a primeira) precisa receber informações sobre sua forma de entrada, especificando o argumento
input_shape. As camadas seguintes podem fazer inferência automática de forma a partir da forma da camada predecessora.
Construindo modelos com Keras
Construindo modelos com Keras
As funções Dense no Keras são usadas para adicionar camadas densamente conectadas (ou totalmente conectadas) a um modelo de rede neural. Em uma camada densa, cada unidade (ou neurônio) recebe entradas de todas as unidades da camada anterior, o que significa que os neurônios estão “densamente” conectados. Essas camadas aplicam operações que envolvem pesos lineares e um viés (bias), geralmente seguidos por uma função de ativação não linear.
Essencialmente, a camada Dense realiza a seguinte operação matemática:
\[ \text{output} = \text{activation}(\text{input} \cdot \text{weight} + \text{bias}) \]
Onde: - input é a entrada da camada, - weight é a matriz de pesos, - bias é o vetor de viés, - activation é a função de ativação.
Essas camadas são fundamentais em redes neurais para aprender padrões complexos nos dados, sendo amplamente utilizadas em problemas de classificação, regressão, entre outros.
Construindo modelos com Keras
Funções de Ativação
O argumento de ativação especifica a função de ativação para a camada atual. Por padrão, nenhuma ativação é aplicada.
A função de ativação softmax normaliza a saída para uma distribuição de probabilidade. É comumente usada na última camada de um modelo. Para selecionar uma única saída em um problema de classificação, a mais provável pode ser selecionada.
A ReLU (Unidade Linear Retificada), max(0, x), é comumente usada como função de ativação para as camadas ocultas.
Muitas outras funções de ativação estão disponíveis ou podem ser facilmente definidas, assim como tipos de camadas.
Construindo modelos com Keras
Compilação do Modelo
Uma vez que o modelo está construído, o processo de aprendizado é configurado chamando o método compile. A fase de compilação é necessária para configurar os seguintes elementos obrigatórios do modelo:
- otimizador: este objeto especifica o algoritmo de otimização que adapta os pesos das camadas durante o procedimento de treinamento;
- perda: este objeto especifica a função a ser minimizada durante a otimização;
- métricas: [opcional] estes objetos medem o desempenho do seu modelo e são usados para monitorar o treinamento.
Construindo modelos com Keras
Compilação do Modelo
Uma vez que o modelo está compilado, podemos verificar seu status usando o resumo e obter informações valiosas sobre a composição do modelo, conexões de camadas e número de parâmetros.
Model: "sequential_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━┩
│ dense_5 (Dense) │ (None, 6) │ 66 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_6 (Dense) │ (None, 8) │ 56 │
├──────────────────────────────────────┼─────────────────────────────┼─────────────────┤
│ dense_7 (Dense) │ (None, 3) │ 27 │
└──────────────────────────────────────┴─────────────────────────────┴─────────────────┘
Total params: 149 (596.00 B)
Trainable params: 149 (596.00 B)
Non-trainable params: 0 (0.00 B)
Construindo modelos com Keras
Treinamento do Modelo
- O método
.fittreina o modelo usando um conjunto de dados de treinamento e relata a perda e a precisão, úteis para monitorar o processo de treinamento.
Construindo modelos com Keras
Avaliação e Previsão do Modelo
- Uma vez que o processo de treinamento tenha sido concluído, o modelo pode ser avaliado contra o conjunto de dados de validação. O método
evaluateretorna o valor da perda e, se o modelo foi compilado também com um argumento de métricas, os valores das métricas.
- O método
predictpode finalmente ser usado para fazer inferências sobre novos dados.
Construindo modelos com Keras
Salvamento e Restauração do Modelo
Um modelo treinado pode ser salvo e armazenado em um arquivo para recuperação posterior. Isso permite que você crie um ponto de controle de um modelo e retome o treinamento mais tarde sem precisar reconstruir e treinar do zero.
Os arquivos são salvos no formato HDF5, com todos os valores de pesos, a configuração do modelo e até a configuração do otimizador.
Construindo modelos com Keras
Se pudermos priorizar algumas funções, são essas:
- Defina um modelo sequencial
model = Sequential()
model.add(Dense(32, input_dim=784))
model.add(Activation('relu'))
model.add(Dense(10))
model.add(Activation('softmax'))- Compilação
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])\(\Longrightarrow\)
- Treinamento
model = model.fit(data, one_hot_labels,
epoch=10, batch_size=32)- Previsão
Y = model.predict(X)Estudo de casos
Problema do XOR com TensorFlow
import numpy as np
import tensorflow as tf
# Preparar dados e rótulos
data = np.asarray([[0, 0, 0], [0, 1, 1], [1, 0, 1], [1, 1, 0]], dtype=np.float32)
# Construir o modelo
x = tf.compat.v1.placeholder(tf.float32, shape=[None, 2], name='x_in') # entrada
label = tf.compat.v1.placeholder(tf.float32, shape=[None, 1], name='label') # rótulo
hidden = tf.keras.layers.Dense(units=2, activation=tf.nn.tanh, use_bias=True,
kernel_initializer=tf.keras.initializers.RandomUniform(minval=-1, maxval=1))(x)
pred = tf.compat.v1.keras.layers.Dense(units=1, activation=tf.nn.sigmoid, use_bias=True,
kernel_initializer=tf.keras.initializers.RandomUniform(minval=-1, maxval=1))(hidden)
cost = tf.compat.v1.norm(tf.math.subtract(label, pred), ord=2, name='cost')
op = tf.compat.v1.train.GradientDescentOptimizer(learning_rate=0.1).minimize(cost)
training_epochs = 20000
# Configurar alocação de GPU
config = tf.compat.v1.ConfigProto(device_count={'GPU': 1})
config.gpu_options.per_process_gpu_memory_fraction = 0.5
# Iniciar uma sessão para treinar e testar
with tf.compat.v1.Session(config=config) as sess:
sess.run(tf.compat.v1.global_variables_initializer())
# Treinar
for epoch in range(training_epochs):
loss = 0
for d in data:
training_X, training_Y = np.asarray(d[0:2], dtype=np.float32), np.asarray(d[2], dtype=np.float32)
training_X, training_Y = np.expand_dims(training_X, axis=0), np.expand_dims([training_Y], axis=0)
sess.run(op, feed_dict={x: training_X, label: training_Y})
loss += sess.run(cost, feed_dict={x: training_X, label: training_Y})
if epoch % 100 == 0:
print(f"Época: {epoch}, Perda = {loss:.6f}")
# Testar
for d in data:
Y = sess.run(pred, feed_dict={x: np.expand_dims(np.asarray(d[0:2], dtype=np.float32), axis=0)})
print("d = ", d, "saída = ", Y)Estudo de casos
Problema do XOR com Keras
import numpy as np
# Importar pacotes ou APIs necessárias do keras
from keras.models import Sequential
from keras.layers import Dense
from keras.optimizers import SGD
from keras.initializers import RandomUniform
# Preparar dados e rótulos
X = np.asarray([[0, 0], [0, 1], [1, 0], [1, 1]], dtype=np.float32)
Y = np.asarray([[0], [1], [1], [0]], dtype=np.float32)
# Construir o modelo
model = Sequential()
model.add(Dense(units=2, activation='tanh', use_bias=True,
kernel_initializer=RandomUniform(minval=-1, maxval=1, seed=None),
input_dim=2))
model.add(Dense(units=1, activation='sigmoid', use_bias=True,
kernel_initializer=RandomUniform(minval=-1, maxval=1, seed=None)))
# Construir otimizador e compilar o modelo
op = SGD(learning_rate=0.01, momentum=0.0)
model.compile(optimizer=op,
loss='mse',
metrics=['accuracy'])
# Iniciar o treinamento
model.fit(x=X, y=Y, epochs=20000, batch_size=4, shuffle=True)
# Previsão
Y_pred = model.predict(X)
print("Y_pred = ", Y_pred)Em resumo
Como dois pacotes populares de aprendizado profundo:
- Keras
- Amigável ao usuário com APIs de alto nível
- Rápido para começar
- Menos linhas de código para construção/treinamento/teste de modelos de aprendizado de máquina
- Às vezes, a convergência do treinamento não é estável.
- TensorFlow
- Flexível para desenvolver novos modelos de aprendizado de máquina
- Multiplataforma
- Suporte da comunidade
- Não muito amigável para novos usuários devido às muitas APIs de baixo nível
OBRIGADO!
Slide produzido com quarto
Redes Neurais - Prof. Jodavid Ferreira