Redes Neurais
Processo de Aprendizagem ML
Prof. Jodavid Ferreira
UFPE
ML: Processo de Aprendizagem
![]()
Figure 1
Observe que o processo é iterativo, ou seja, é necessário voltar a etapas anteriores para ajustar o modelo.
ML: Processo de Aprendizagem
Organização dos dados
Dataset: designa amplamente os dados usados no aprendizado de máquina. Cada registro é nomeado de observação, exemplo, instância ou amostra (sample), a qual é formada por variáveis ou características (features). “Features” são partes relevantes para caracterizar as observações.
Conjunto de treinamento (training set): é o conjunto de dados usado para treinar o modelo (aprendizado). É formado por um conjunto de observações e suas respectivas saídas desejadas.
Conjunto de teste (test set): é o conjunto de dados usado para avaliar o modelo treinado. Simula a situação real, onde o modelo é aplicado a novos dados. É formado por um conjunto de observações de entrada.
ML: Processo de Aprendizagem
Exemplo de “dataset” (dados rotulados):
![]()
ML: Processo de Aprendizagem
Exemplo de “dataset” (dados rotulados):
![]()
ML: Processo de Aprendizagem
Importância dos Dados
Se os dados forem bons, não há como garantir que o modelo será bom
Se os dados não são bons, podemos garantir que o modelo será ruim
Etapas de Pré-processamento
Limpeza \(\rightarrow\) Remoção de dados duplicados, outliers, dados faltantes, evita incosisntências e erros na leitura dos dados;
Redução dimensional \(\rightarrow\) evitar explosão dimensional, reduzindo o número de variáveis;
Normalização \(\rightarrow\) padronização dos dados, evitando que variáveis com escalas diferentes influenciem o modelo, reduz ruídos e melhora a performance do modelo;
ML: Processo de Aprendizagem
O Processo começa pela limpeza dos dados, mas observe a divisão do trabalho relatada por cientistas de dados…
![]()
ML: Processo de Aprendizagem
Limpeza dos Dados
Geralmente, os modelos de aprendizado de máquina não funcionam bem com dados faltantes, duplicados ou inconsistentes.
É comum ter dados coletados que só podem ser usados após uma etapade preparação que pode incluir:
- Remoção de dados duplicados;
- Tratamento de dados faltantes;
- Tratamento de outliers;
- Normalização dos dados;
- Redução de dimensionalidade;
- Transformação de variáveis categóricas em numéricas;
- Balanceamento de classes;
ML: Processo de Aprendizagem
Exemplos de problemas vistos em dados brutos:
![]()
ML: Processo de Aprendizagem
Conversão de dados
ML: Processo de Aprendizagem
Conversão de dados
- Dados de imagens podem ser transformados…
- Espaço de cores;
- Escala de cinza;
- Histograma de cores;
- Transformada de Fourier;
- Feature Engineering: criação de novas variáveis a partir das variáveis originais.
- Normalização de características para igualar “range” de valores;
- Expansão de características: combinar ou converter variáveis para gerar novas características;
ML: Processo de Aprendizagem
Após limpeza e conversão…
Seleção de características (Feature Selection) \(\rightarrow\) Motivações
Geralmente, há um grande número de “features” nas bases de dados. Algumas podem ser rendundantes ou irrelevantes para a previsão que se deseja fazer, podendo ser desprezadas.
Essa etapa independe do algorito de aprendizagem de máquina.
Há quatro motivações para implementar a seleção de “features”.
![]()
ML: Processo de Aprendizagem
Seleção de características (Feature Selection) \(\rightarrow\) Métodos
Destacamos três conjuntos de métodos:
Filtros: métodos que selecionam “features” com base em métricas estatísticas, como correlação, entropia, etc.
Wrappers: métodos que selecionam “features” com base no desempenho de um modelo de aprendizado de máquina.
Embedded: métodos que selecionam “features” durante o treinamento do modelo.
ML: Processo de Aprendizagem
Seleção de características (Feature Selection) \(\rightarrow\) Filtro
![]()
Engloba técnicas baseadas na correlação entre as “features” e a variável alvo.
Geralmente, usam parâmetros estatísticos para selecionar as “features” mais relevantes, através de um limiar, ou seja, um “rank” das “features”.
ML: Processo de Aprendizagem
Seleção de características (Feature Selection) \(\rightarrow\) Filtro
Métodos Comuns:
- Correlação de Pearson: mede a relação linear entre duas variáveis contínuas.
- Correlação de Spearman: mede a relação monotônica entre duas variáveis contínuas ou ordinais.
- Correlação de Kendall: mede a relação ordinal entre duas variáveis ordinais.
- Informação Mútua: mede a dependência entre duas variáveis.
- Teste Qui-Quadrado: mede a relação entre duas variáveis categóricas.
Limitações:
- Não considera a relação entre as “features”;
- Não considera a relação não linear entre as “features” e a variável alvo;
- Não considera a relação entre as “features” e a variável alvo.
ML: Processo de Aprendizagem
Seleção de características (Feature Selection) \(\rightarrow\) Wrapper
![]()
Engloba técnicas que usam um modelo de aprendizado de máquina para avaliar a importância das “features”.
Geralmente, usam um modelo de aprendizado de máquina para avaliar a importância das “features” e selecionar as mais relevantes.
ML: Processo de Aprendizagem
Seleção de características (Feature Selection) \(\rightarrow\) Wrapper
Métodos Comuns:
- Seleção para Frente (Forward): começa com um modelo vazio e adiciona uma “feature” por vez, avaliando o desempenho do modelo a cada iteração.
- Seleção para Trás (Backward): começa com todas as “features” e remove uma “feature” por vez, avaliando o desempenho do modelo a cada iteração.
- Seleção para Frente e para Trás (Stepwise): combina as duas técnicas anteriores.
- Eliminação Recursiva de “Features” (RFE): remove “features” de acordo com a importância atribuída pelo modelo.
Limitações:
- Alto custo computacional;
- Pode ser sensível a ruídos;
- Pode ser sensível a overfitting.
ML: Processo de Aprendizagem
Seleção de características (Feature Selection) \(\rightarrow\) Embedded
![]()
ML: Processo de Aprendizagem
Seleção de características (Feature Selection) \(\rightarrow\) Embedded
Métodos Comuns:
- Lasso (Least Absolute Shrinkage and Selection Operator): adiciona um termo de penalização L1 à função de custo.
- Ridge: adiciona um termo de penalização L2 à função de custo.
- Elastic Net: combina os métodos Lasso e Ridge.
- Random Forest, XGBoost, LightGBM, CatBoost: avalia a importância das “features” com base na redução da impureza, ou seja, a importância das “features” é avaliada durante o treinamento do modelo.
Limitações:
- Pode ser sensível a overfitting;
- Pode ser sensível a ruídos.
ML: Processo de Aprendizagem
Seleção de características (Feature Selection) \(\rightarrow\) Embedded
![]()
ML: Processo de Aprendizagem
Resumo geral da construção de um Modelode 1 até 6… Observe 2!
![]()
ML: Processo de Aprendizagem
Um exemplo de Aprendizado Supervisionado \(\rightarrow\) Etapa de Aprendizado
![]()
ML: Processo de Aprendizagem
Um exemplo de Aprendizado Supervisionado \(\rightarrow\) Etapa de Aprendizado
![]()
ML: Processo de Aprendizagem
Um exemplo de Aprendizado Supervisionado \(\rightarrow\) Etapa de Previsão
![]()
ML: Processo de Aprendizagem
O que define um modelo como bom?
Quais são as perguntas certas?
- Precisão: o modelo está prevendo corretamente? ou seja, a acurácia do modelo é alta.
- Interpretabilidade: o modelo é compreensível? ou seja, é possível entender como o modelo chegou a uma determinada previsão.
- Robustez: o modelo é resistente a ruídos? isto é, o modelo é capaz de generalizar para novos dados.
- Escalabilidade: o modelo é escalável? isto é, o modelo é capaz de lidar com grandes volumes de dados.
- Generalização: o modelo é generalizável? isto é, o modelo é capaz de prever corretamente para novos dados.
- Eficiência: o modelo é eficiente? isto é, o modelo é capaz de prever em tempo hábil.
ML: Processo de Aprendizagem
Validade do Modelo - Definições
Capacidade de generalização: capacidade do modelo de prever corretamente para novos dados.
Erro: diferença entre o valor previsto e o valor real. Há dois tipos:
- Erro de treinamento: erro entre o valor previsto e o valor real no conjunto de treinamento.
- Erro de teste: erro entre o valor previsto e o valor real no conjunto de teste.
Capacidade do modelo: capacidade do modelo de se ajustar aos dados de treinamento e generalizar para novos dados.
ML: Processo de Aprendizagem
Validade do Modelo - Definições
Underfitting
- Ocorre quando o modelo é muito simples para capturar a complexidade dos dados.
- Ocorre quando o modelo ou algoritmo nao consegue encontrar uma relação entre as grandezas de entradae a saída.
- Os erros de treinamento e de generalizações tendem a ser altos.
- A capacidade do modelo é baixa.
![]()
ML: Processo de Aprendizagem
Validade do Modelo - Definições
Overfitting
- Ocorre quando o modelo ou algoritmo opera perfeitamente apenas nos dados de treino.
- Os erros de treinamento são baixos, mas os erros de generalização são altos.
- A capacidade do modelo pode ter sido excessiva, de modo que o modelo nãoé capaz de generalizar para novos dados.
![]()
ML: Processo de Aprendizagem
Validade do Modelo - Definições
![]()
ML: Processo de Aprendizagem
Variância e Tendência (Variance and Bias)
![]()
ML: Processo de Aprendizagem
O erro total de previsão depende da variância e do viés do modelo:
\[
\text{Erro Total} = \text{Erro de Viés} + \text{Erro de Variância} + \text{Erro Irredutível}
\]
- Erro de Viés: erro devido à simplificação do modelo, ou seja, o modelo não consegue capturar a complexidade dos dados.
- Erro de Variância: erro devido à complexidade do modelo, ou seja, o modelo é muito complexo e não consegue generalizar para novos dados.
- Erro Irredutível: erro devido ao ruído nos dados, ou seja, o modelo não consegue prever corretamente devido ao ruído nos dados.
- Erro Total: erro total de previsão, ou seja, a diferença entre o valor previsto e o valor real.
ML: Processo de Aprendizagem
Como regra geral:
- Modelo bom é aquele que tem baixo erro de viés e baixo erro de variância.
Por sua origem, os erros podem ser divididos em duas categorias:
- erros causados por variância;
- erros causados por viés;
ML: Processo de Aprendizagem
Variância e Tendência (Variance and Bias) \(\rightarrow\) Aprendizado de Máquina
Análise qualitativa:
- Variância alta significa que o modelo tem alta sensibilidade a pequenas variações no conjunto de treinamento.
Esse comportamento é compatível com overfitting!
- Viés está relacionada com a diferença entre a média das previsões e os valores corretos que desejamos prever.
Esse comportamento é compatível com underfitting!
ML: Processo de Aprendizagem
Capacidade do Modelo vs Erro de Previsão \(\rightarrow\) Baixa Complexidade
![]()
ML: Processo de Aprendizagem
Capacidade do Modelo vs Erro de Previsão \(\rightarrow\) Alta Complexidade
![]()
ML: Processo de Aprendizagem
Capacidade do Modelo vs Erro de Previsão \(\rightarrow\) Compromisso
![]()
ML: Processo de Aprendizagem
Como avaliar quantitativamente o desempenho do modelo?
- Problemas de Regressão:
- Erro absoluto médio (MAE): média das diferenças absolutas entre o valor previsto e o valor real.
\[MAE = \frac{1}{n} \sum_{i=1}^{n} |y_i - \hat{y}_i|\] em que, \(n\) é o número de observações, \(y_i\) é o valor real e \(\hat{y}_i\) é o valor previsto.
ML: Processo de Aprendizagem
Como avaliar quantitativamente o desempenho do modelo?
em que, \(n\) é o número de observações, \(y_i\) é o valor real e \(\hat{y}_i\) é o valor previsto.
ML: Processo de Aprendizagem
Como avaliar quantitativamente o desempenho do modelo?
Problemas de Regressão:
- Coeficiente de determinação (\(R^2\)): mede a proporção da variabilidade da variável dependente que é explicada pelo modelo.
\[R^2 = 1 - \frac{\sum_{i=1}^{n} (y_i - \hat{y}_i)^2}{\sum_{i=1}^{n} (y_i - \bar{y})^2}\] em que, \(n\) é o número de observações, \(y_i\) é o valor real, \(\hat{y}_i\) é o valor previsto e \(\bar{y}\) é a média dos valores reais.
ML: Processo de Aprendizagem
Como avaliar quantitativamente o desempenho do modelo?
ML: Processo de Aprendizagem
Como avaliar quantitativamente o desempenho do modelo?
ML: Processo de Aprendizagem
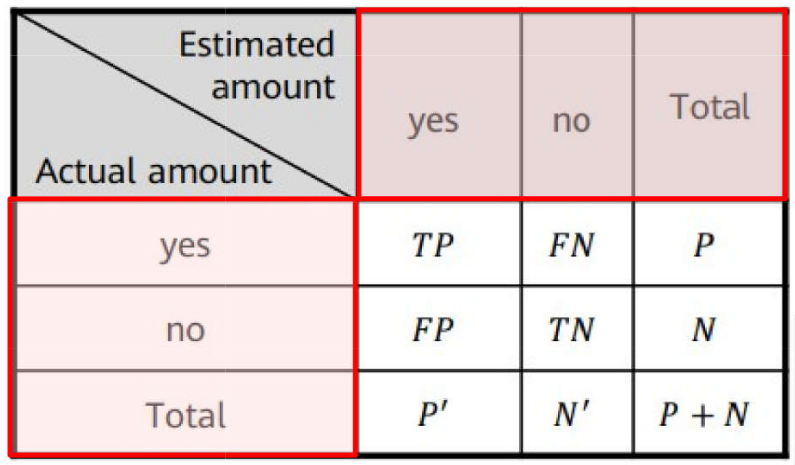
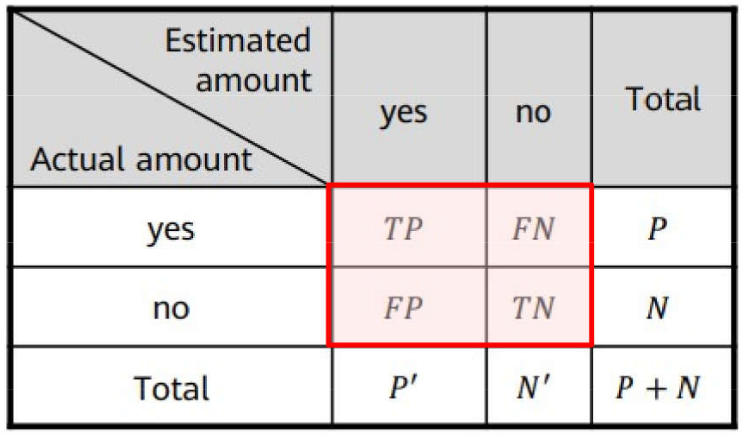
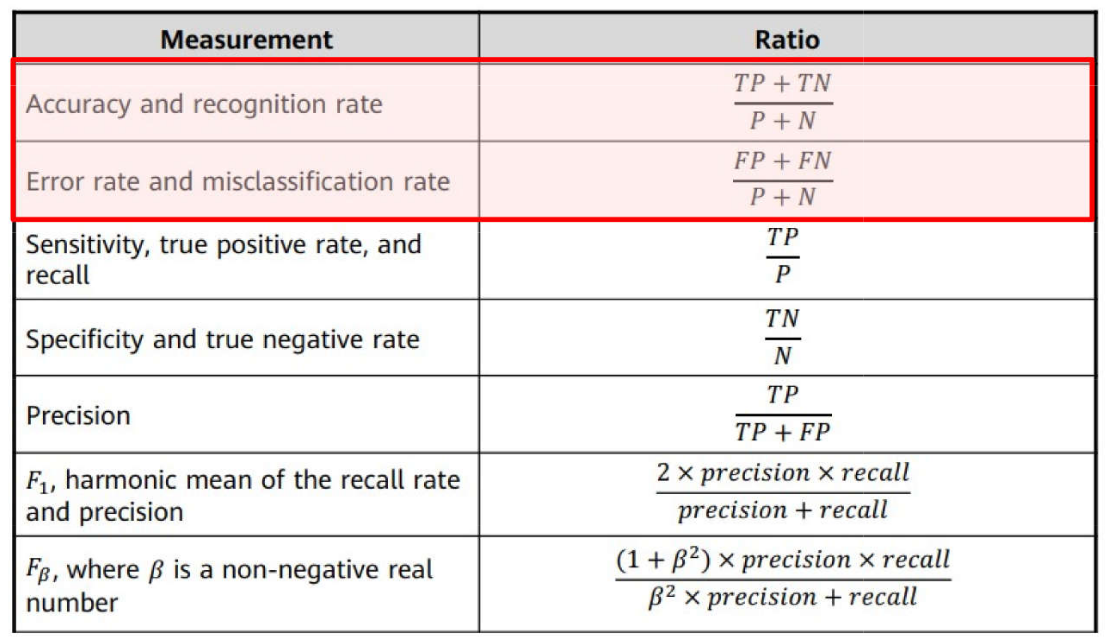
Problemas de Classificação \(\rightarrow\) Métricas: Acurácia e Taxa de Erro
ML: Processo de Aprendizagem
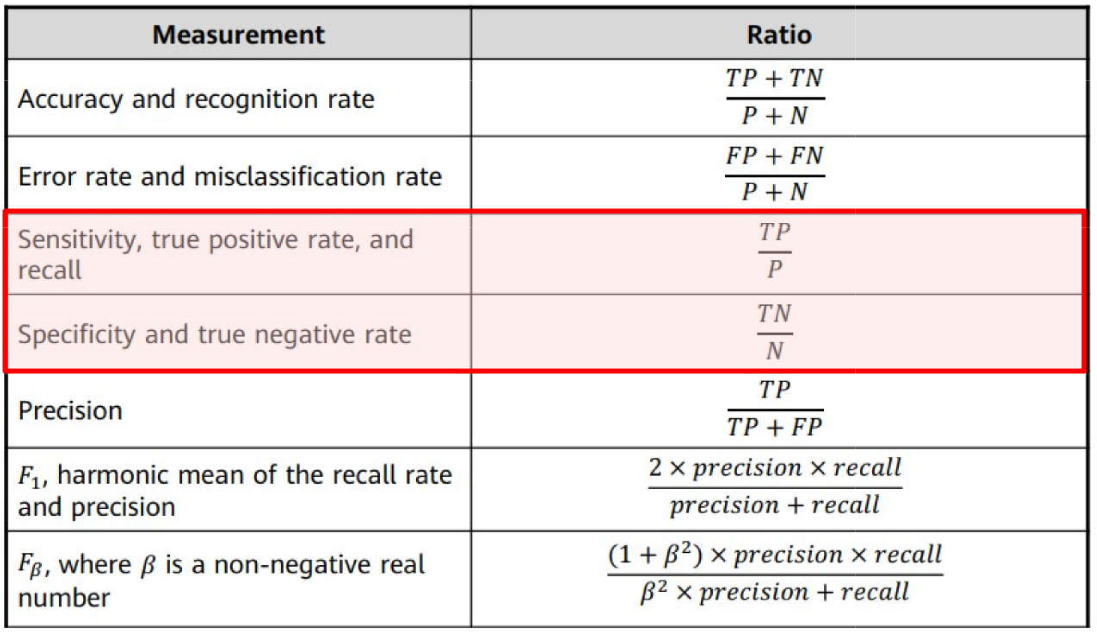
Problemas de Classificação \(\rightarrow\) Métricas: Sensibilidade e Especificidade
ML: Processo de Aprendizagem
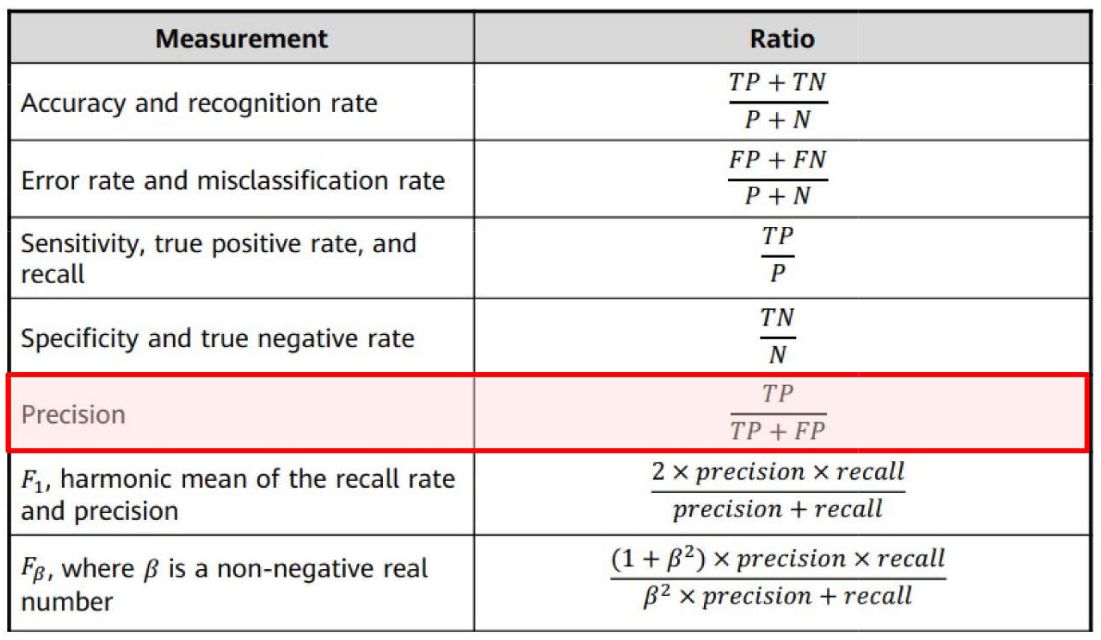
Problemas de Classificação \(\rightarrow\) Métricas: Precisão
ML: Processo de Aprendizagem
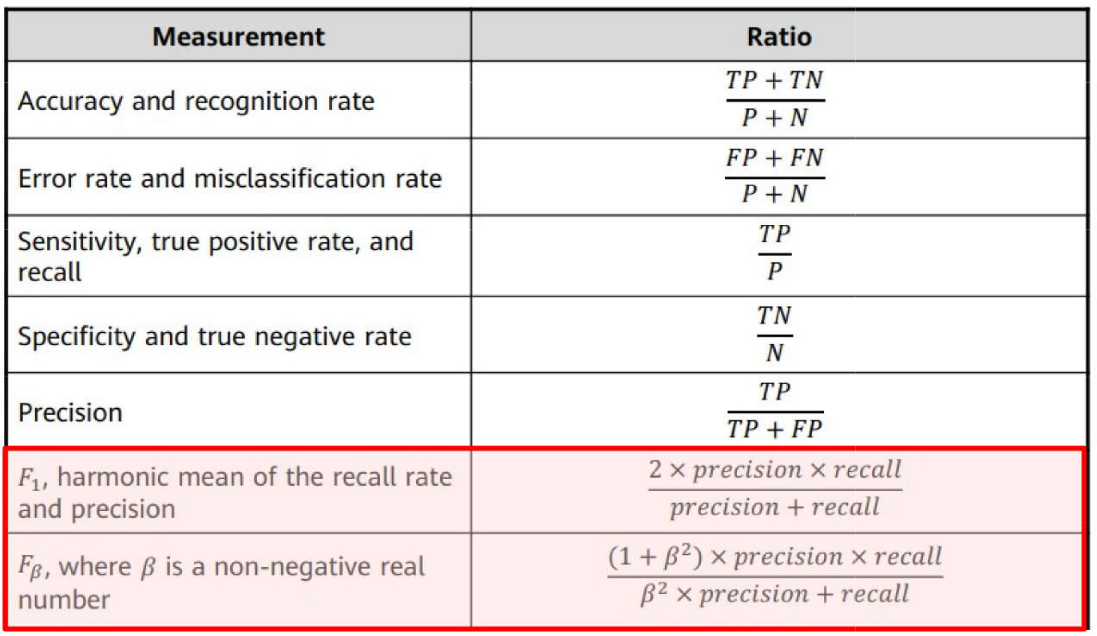
Problemas de Classificação \(\rightarrow\) Métricas: \(F_1\) Score e \(F_{\beta}\)
ML: Processo de Aprendizagem
Exemplo de avaliação de desempenho de um modelo de ML
Um modelo de ML foi treinado para identificar se o objeto presente em imagens é um gato. Foram usadas 200 imagens para avaliar o desempenho do modelo, tendo sido obtida a seguinte matriz de confusão:
![]()
Deseja-se calcular as métricas de precisão, sensibilidade e acurácia do modelo.
ML: Processo de Aprendizagem
Resposta
Qual o significado desses valores?
Referências para serem utilizadas
Imagens retiradas de um Curso de ML da Huawei.
The Elements of Statistical Learning: Data Mining, Inference and Prediction, Hastie, T., Tibshirani, R. and Friedman, J., 2nd ed., Springer-Verlag, 2009.
An Introduction to Statistical Learning: With Applications in R, James, G., Witten, D., Hastie, T. and Tibshirani, R., Springer-Verlag, 2013.
Aprendizado de máquina: uma abordagem estatística, Izbicki, R. and Santos, T. M., 2020.
Extras:
Morris, Meredith Ringel, et al. “Levels of AGI: Operationalizing Progress on the Path to AGI.” arXiv preprint arXiv:2311.02462 (2023).
Weijermars, Ruud, Umair bin Waheed, and Kanan Suleymanli. “Will ChatGPT and Related AI-tools Alter the Future of the Geosciences and Petroleum Engineering?.” First Break 41.6 (2023): 53-61.