Redes Neurais
Básico de LLM (Large Language Models) e o Modelo Estatístico
Prof. Jodavid Ferreira
UFPE
Cronologia Específica dos LLMs
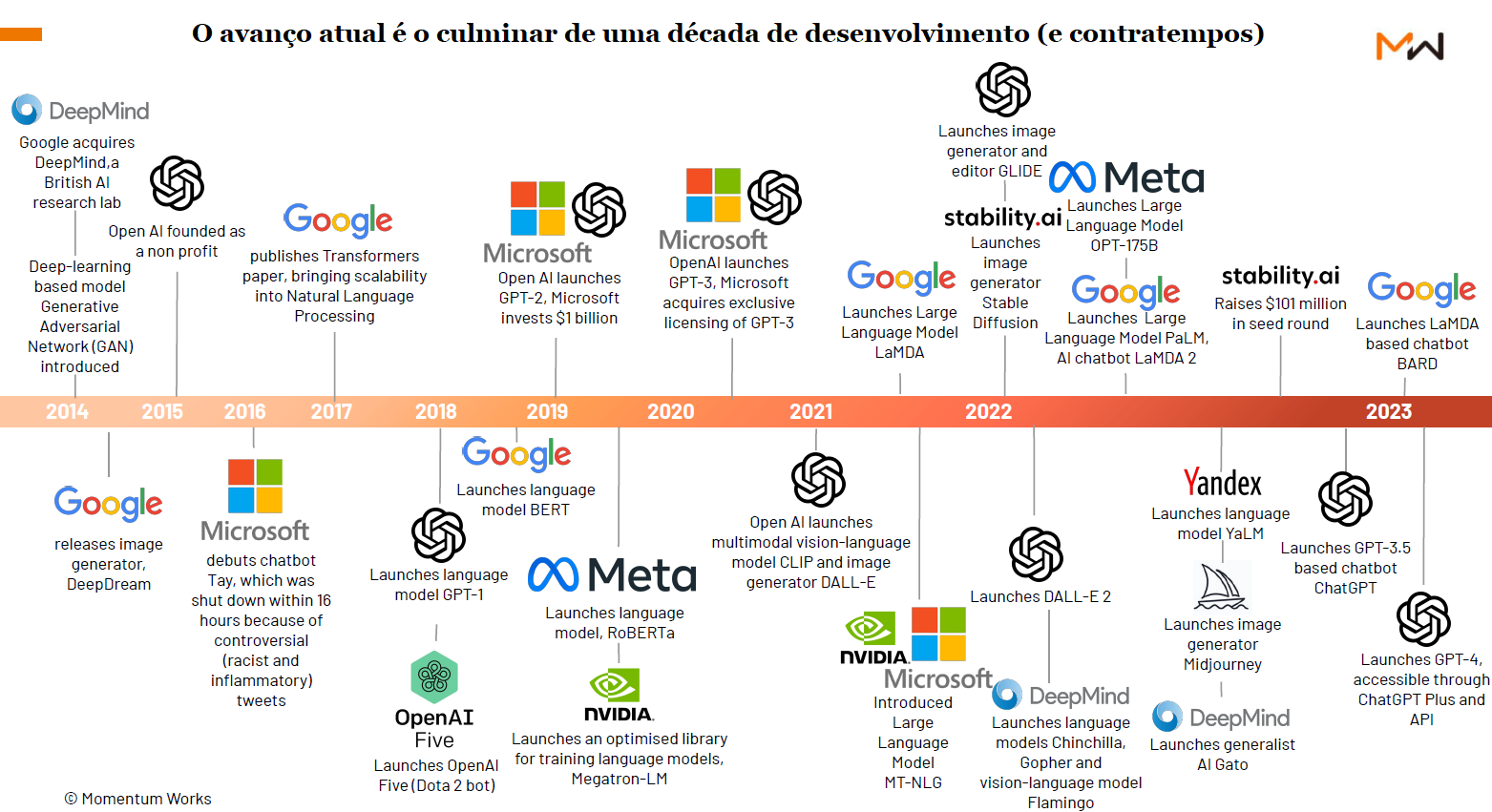
Expandindo a linha do tempo para Modelos de Linguagem (Patriota, 2024):
- 1966: Chatbot Eliza (Baseado em regras: “se X, então Y”).
- 1993: Modelos de linguagem baseados em frequências simples (n-grams).
- 2013: Embeddings (Representação vetorial de palavras - Word2Vec).
- 2017: Transformers (O mecanismo de atenção - “Attention is all you need”).
- 2018-19: GPT-1 e GPT-2 (Generative Pretrained models).
- 2020-Atual: GPT-3, GPT-4, Llama, Gemini, Grok (Modelos reflexivos, multimodais).
Inteligência Artificial
![]()
(fonte: AI Experience - Google)
Inteligência Artificial
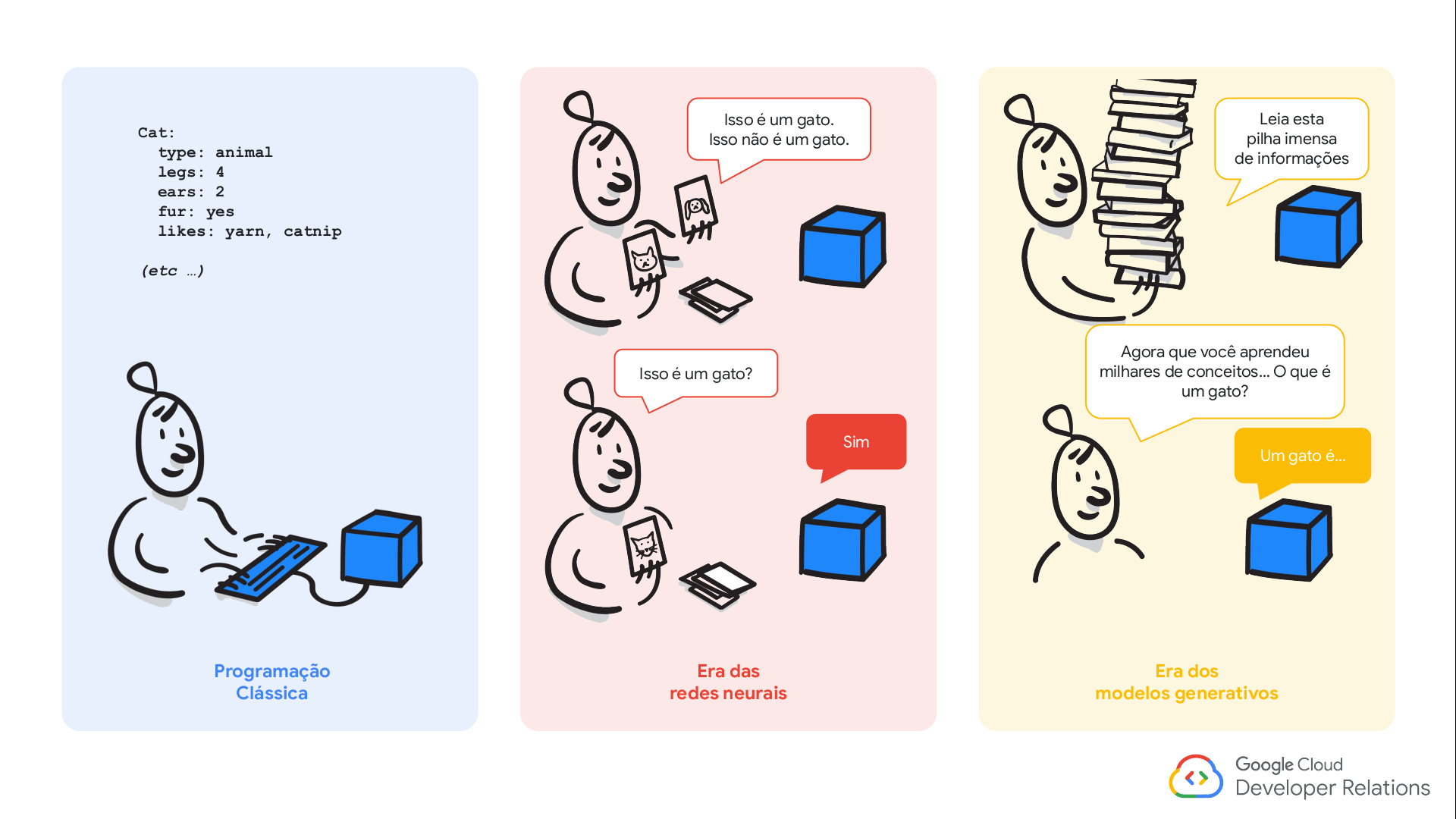
Mas o que estão por trás da IA Generativa?
LLMs - Large Language Models
- inicialmente foram definidos como modelos projetados para compreender e gerar linguagem natural;
- atualmente são treinados em grandes quantidades de dados, como livros, imagens, vídeos;
- o “large”“ em LLM refere-se ao número de parâmetros que o modelo possui, geralmente na casa dos bilhões. Geralmente utilizados em soluções que necessitam ter contexto similar a interação entre humanos.
SLMs - Small Language Models
- são modelos menores, no sentido que posuem menos parâmetros, geralmente na faixa de milhões;
- continuam utilizando grandes quantidades de dados como textos, imagens e vídeos;
- necessitam de menos recursos computacionais para treinamento e inferência, logo, são mais viáveis para uso em dispositivos com recursos limitados, como:
- smartphones e sistemas embarcados.
Estatisticamente, um modelo de linguagem é uma função que estima a distribuição de probabilidade condicional do próximo elemento da sequência, dado o histórico.
Entrada (Contexto): O histórico observado (uma sequência de tokens \(w_1, \dots, w_t\)). Saída: Um vetor de probabilidades sob parâmetros \(\boldsymbol{\theta}\) para a próxima ‘palavra’ (token \(w_{t+1}\)), dado o contexto.
\[
f(w_1, \dots, w_t; \boldsymbol{\theta}) = \boldsymbol{p}_\theta(w_1, \ldots, w_t) = \begin{pmatrix} P(w_{t+1} = v_1 | w_1, \dots, w_t; \boldsymbol{\theta}) \\ \vdots \\ P(w_{t+1} = v_V | w_1, \dots, w_t; \boldsymbol{\theta}) \end{pmatrix}
\]
Onde \(\mathcal{V} = \{v_1, \dots, v_V\}\) é o conjunto do vocabulário de tamanho \(V\).
Inteligência Artificial
Alguns dos modelos em alta do momento?
OpenAI:
- DALL-E - modelo de geração de imagens;
- ChatGPT - modelo de linguagem natural - multimodal;
- SORA - modelo de texto-para-vídeo;
- Whisper - modelo de audio-para-texto;
Meta:
- Llama3.1 - modelo de linguagem natural;
Google:
- GEMINI - modelo multimodal;
Maritaca:
- Sabiá 31 - modelo de linguagem natural;
- Sabiá 2 - modelo de linguagem natural;
Introdução à Inteligência Artificial
Algumas informações sobre os modelos:
![]()
Legenda:
![]()
Link: https://docs.google.com/spreadsheets/d/1kc262HZSMAWI6FVsh0zJwbB-ooYvzhCHaHcNUiA0_hY/edit?gid=484905095#gid=484905095
Os “dados de treinamento especial” são conjuntos de dados de alta qualidade, cuidadosamente selecionados e organizados. Eles podem incluir dados diversificados e representativos, dados enriquecidos com anotações ou metadados, dados sintéticos, e dados privados ou proprietários. Esses dados são valiosos para criar modelos mais precisos e especializados, capazes de entender nuances e aplicar conhecimento em contextos específicos, como saúde, direito, ou finanças.
Introdução à Inteligência Artificial
Detalhando as duas arquiteturas dos modelos de LLMs, temos:
Arquitetura Dense
é uma arquitetura onde cada neurônio em uma camada é conectado aos demais neurônios na camada seguinte. Essa conectividade total é também conhecida como fully connected.
Arquitetura MoE
é uma arquitetura de rede neural onde o modelo é dividido em vários “experts” (sub-modelos) especializados em diferentes partes do espaço de entrada. Possui uma camada denominada gating que determina quais experts serão ativados para uma dada entrada.
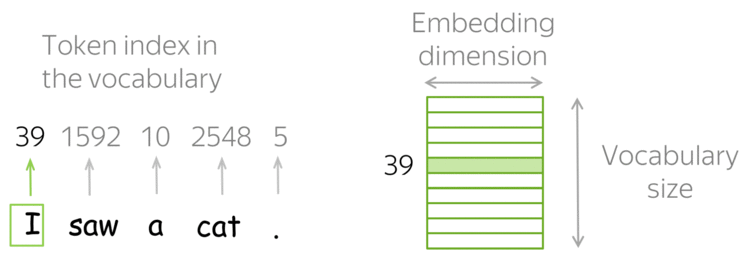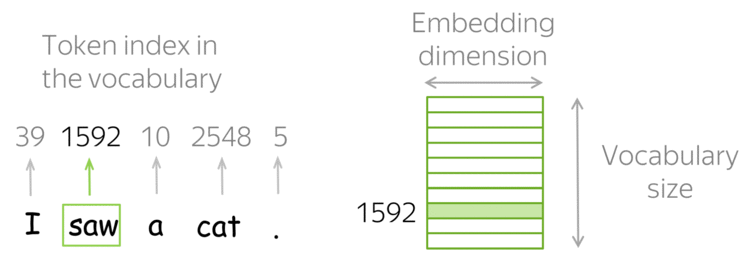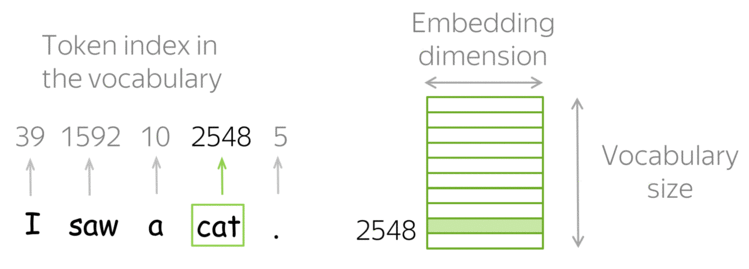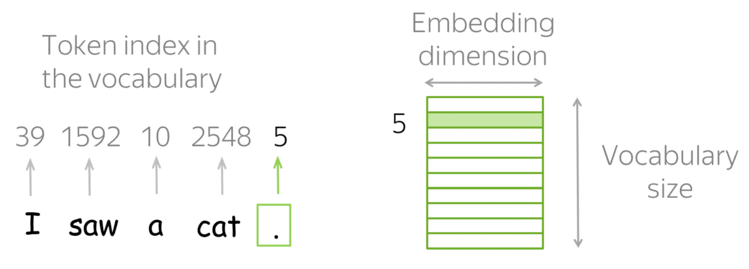
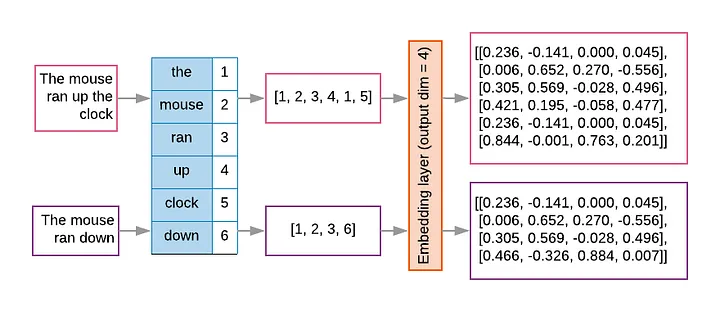
Tokens e Embeddings
- Tokens e Embeddings são a base dos modelos de LLMs.
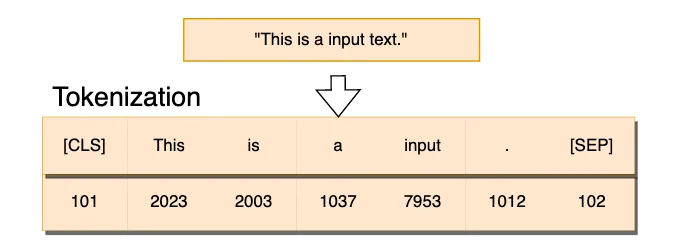
A tokenização é o processo de pegar o texto e transformar as sequências de entrada para números.
- O texto pode ser representado por caracteres ou subpalavras (tokens).
- Exemplo (Subpalavras): “João”, “\(\,\)”, “é”, “\(\,\)”, “pro”, “fessor”.
- Com os tokens, formamos um Vocabulário de tamanho \(V\) (e.g., \(V=50.257\) no GPT-2).
- Tokens especiais:
<PAD>, <UNK>, <EOS> (End of Sentence).
Representação One-Hot
Para o tratamento estatístico multivariado, representamos cada token categórico via codificação One-Hot (vetor indicadora). Cada token torna-se um vetor de zeros com um 1 na posição correspondente à palavra no vocabulário.
Para um vocabulário \(\{A, B, C, D\}\), a sequência \(A, A, B\) vira uma sequência de vetores \(\dot{\mathbf{x}}_1, \dot{\mathbf{x}}_2, \dot{\mathbf{x}}_3\):
\[
\dot{\mathbf{x}}_1 = \begin{pmatrix} 1 \\ 0 \\ 0 \\ 0 \end{pmatrix}_A, \quad \dot{\mathbf{x}}_2 = \begin{pmatrix} 1 \\ 0 \\ 0 \\ 0 \end{pmatrix}_A, \quad \dot{\mathbf{x}}_3 = \begin{pmatrix} 0 \\ 1 \\ 0 \\ 0 \end{pmatrix}_B
\]
Em probabilidade, tratamos o próximo token como uma variável aleatória multivariada (vetor aleatório) \(\mathbf{x}\) e as observações passadas como valores fixos \(\dot{\mathbf{x}}\).
Tokens e Embeddings
![]()
Apesar da referência, palavras grandes podem ser divididas em subtokens menores, sendo assim, em 1.000 tokens de palavras em português correspondem aproximadamente a 700 a 750 palavras do nosso idioma.
O Modelo Estatístico
Distribuição Multinomial
Com tokens One-Hot, a variável aleatória do próximo token \(\mathbf{x}_{t+1}\) condicionada ao contexto histórico \(\dot{\mathbf{x}}_{1:t}\) segue uma distribuição Multinomial com tamanho de amostra \(n=1\):
\[
\mathbf{x}_{t+1} | \dot{\mathbf{x}}_{1:t} \sim \text{Multinomial}\left(1, \, \boldsymbol{p}_\theta(\dot{\mathbf{x}}_{1:t})\right)
\]
em que \(\boldsymbol{p}_\theta(\dot{\mathbf{x}}_{1:t})\) é o vetor de probabilidades condicionais estimado pelo modelo (a rede neural), ou seja, dado que reescrevemos \(w_i\) como one-hot’s \(\dot{\mathbf{x}}_i\) (Slide 8), temos:
\[
f(w_1, \dots, w_t; \boldsymbol{\theta}) = \boldsymbol{p}_\theta(w_1, \ldots, w_t) \rightarrow f(x_1, \dots, x_t; \boldsymbol{\theta}) = \boldsymbol{p}_\theta(\dot{\mathbf{x}}_{1:t})
\]
Estimação
Função de Verossimilhança
Treinar o LLM nada mais é do que a estimação dos parâmetros \(\boldsymbol{\theta}\) da rede neural via Máxima Verossimilhança. Para uma sequência de \(T\) tokens, a função de verossimilhança é o produto das densidades multinomiais:
\[
L(\boldsymbol{\theta}) = \prod_{t=1}^{T-1} \prod_{j=1}^{V} \left[ p_{\theta, j}(\dot{\mathbf{x}}_{1:t}) \right]^{x_{j, t+1}}
\]
onde \(x_{j, t+1} \in \{0, 1\}\) é o componente \(j\) do token one-hot verdadeiro no tempo \(t+1\).
Estimação
Função de Verossimilhança
Na prática, é minimizado a log-verossimilhança negativa, que também pode ser chamada de Função de Perda de Entropia Cruzada (Cross-Entropy Loss): \[
\ell(\boldsymbol{\theta}) = - \sum_{t=1}^{T-1} \sum_{j=1}^{V} x_{j, t+1} \log p_{\theta, j}(\dot{\mathbf{x}}_{1:t})
\]
- Otimizadores: Variações do Gradiente Descendente Estocástico (SGD, Adam, AdamW).
- As derivadas são obtidas por Backpropagation e AutoGrad.
Tokens e Embeddings
Embeddings são vetores numéricos obtidos dos tokens e representam palavras, frases ou documentos.
- No modelo estatístico, cada token do vocabulário é mapeado para um vetor numérico em um espaço de dimensão \(m\).
- GPT-2: \(m = 768\)
- GPT-3: \(m = 12.288\)
- Os embeddings fazem uma representação mais rica do relacionamento entre os tokens.
- O número de parâmetros apenas na camada de embedding pode ser gigante (Ex: \(V=50.257 \times m=768 \approx 39\) milhões de parâmetros).
Tokens e Embeddings
![]()
Tokens e Embeddings
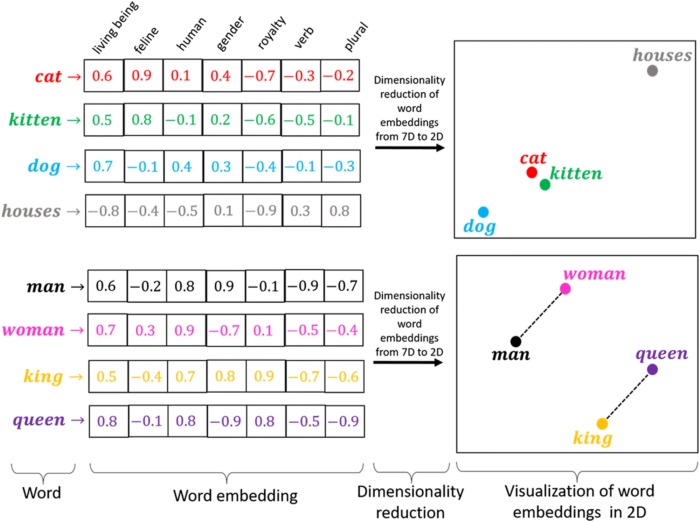
As word embeddings transformam os valores inteiros únicos obtidos a partir do tokenizador em um array \(n\)-dimensional.
Por exemplo, a palavra ‘gato’ pode ter o valor ‘20’ a partir do tokenizador, mas a camada de embedding utilizará todas as palavras no seu vocabulário associadas a ‘gato’ para construir o vetor de embeddings. Ela encontra “dimensões” ou características, como “ser vivo”, “felino”, “humano”, “gênero”, etc.
Assim, a palavra ‘gato’ terá valores diferentes para cada dimensão/característica.
Tokens e Embeddings
Vamos ver um exemplo em python!1
Detalhes importantes:
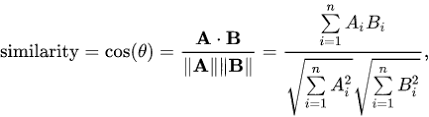
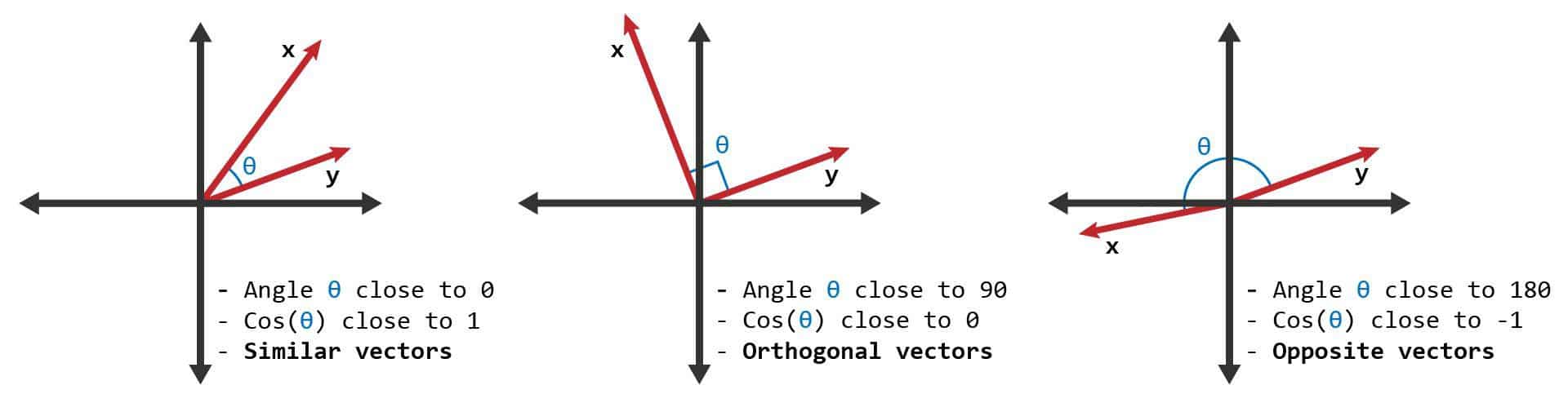
Similaridade do Cosseno (\(Sim_{cos}\)):
- Maior valor (próximo de 1): Maior similaridade.
- Menor valor (próximo de -1): Maior dissimilaridade.
Distância do Cosseno (\(D_{cos} = 1 - Sim_{cos}\)):
- Maior valor (próximo de 2): Maior dissimilaridade.
- Menor valor (próximo de 0): Maior similaridade.
Q, K e V?
Dada a sequência de tokens em formato One-Hot no contexto \(\mathbf{x}_1, \mathbf{x}_2, \dots, \mathbf{x}_t\):
- Mapeamos cada token para seu embedding denso inicial usando a matriz de pesos de embedding \(W_{emb}\): \[\mathbf{e}_i = W_{emb} \dot{\mathbf{x}}_i \quad \text{para } i = 1, \dots, t\]
- O modelo utiliza matrizes de projeção aprendidas (\(W^Q, W^K, W^V\)) para calcular a Query, as Keys e os Values:
- Para o token na posição atual \(t\), geramos a Query \(\mathbf{q}_t\): \[\mathbf{q}_t = W^Q \mathbf{e}_t\]
- Para todos os tokens do contexto (posições \(i = 1, \dots, t\)), geramos as Keys \(\mathbf{k}_i\) e os Values \(\mathbf{v}_i\): \[\mathbf{k}_i = W^K \mathbf{e}_i \quad \text{e} \quad \mathbf{v}_i = W^V \mathbf{e}_i\]
Atenção
O Paralelo com Suavização de Núcleo
O estimador não-paramétrico de Nadaraya-Watson estima a relação \(m(x) = \mathbb{E}[Y|X=x]\) a partir de observações históricas \((x_i, y_i)_{i=1}^t\):
\[
\hat{m}(x) = \sum_{i=1}^t w_i(x) y_i \quad \text{onde } \quad w_i(x) = \frac{K(x, x_i)}{\sum_{j=1}^t K(x, x_j)}
\] sendo \(K(\cdot, \cdot)\) uma função de Kernel de similaridade.
No mecanismo de Atenção, a nova representação do token atual \(\mathbf{h}_t\) é a média ponderada dos valores \(\mathbf{v}_i\) e utilizado o Kernel Exponencial:
\[
\mathbf{h}_t = \sum_{i=1}^t w_i(\mathbf{q}_t) \mathbf{v}_i \quad \text{onde } \quad w_i(\mathbf{q}_t) = \frac{\exp\left(\frac{\mathbf{q}_t^\top \mathbf{k}_i}{\sqrt{d_k}}\right)}{\sum_{j=1}^t \exp\left(\frac{\mathbf{q}_t^\top \mathbf{k}_j}{\sqrt{d_k}}\right)}
\]
Atenção: Mapeamento de Conceitos
A equivalência matemática entre a Estatística e o Deep Learning é direta:
| Ponto de Avaliação (\(x\)) |
Query atual (\(\mathbf{q}_t\)) |
Representação do token na posição \(t\) que busca contexto |
| Covariável de Histórico (\(x_i\)) |
Keys passadas (\(\mathbf{k}_i\)) |
Representação dos tokens do contexto (\(i \le t\)) para busca |
| Resposta Observada (\(y_i\)) |
Values passados (\(\mathbf{v}_i\)) |
Conteúdo informacional dos tokens do contexto (\(i \le t\)) |
| Função de Kernel \(K(x, x_i)\) |
Kernel Exponencial \(\exp\left(\frac{\mathbf{q}_t^\top \mathbf{k}_i}{\sqrt{d_k}}\right)\) |
Medida de similaridade/associação |
| Média Ponderada \(\hat{m}(x)\) |
Vetor de Saída \(\mathbf{h}_t\) |
Nova representação contextualizada do token na posição \(t\) |
Desse modo, a Atenção nada mais é do que uma Suavização de Núcleo (Kernel Smoothing) Multivariada parametrizada e adaptada a representações vetoriais.
O Modelo
como Regressão Logística Sofisticada
O Transformer atua como um enorme extrator de características (feature extractor). Se olharmos a última camada, ela é uma Regressão Logística Multinomial:
- A arquitetura passa os dados por várias transformações não-lineares até um embedding contextual final \(\mathbf{h}_t \in \mathbb{R}^d\).
- Uma transformação linear (com matriz de pesos \(W_U \in \mathbb{R}^{V \times d}\)) projeta \(\mathbf{h}_t\) para os Logits do vocabulário (tamanho \(V\)).
- A função de ligação é a Softmax:
\[
\boldsymbol{p}_\theta(\dot{\mathbf{x}}_{1:t}) = \text{softmax}(W_U \mathbf{h}_t + \mathbf{b})
\]
Dessa forma, a rede neural profunda (“deep learning”) apenas constrói as covariáveis perfeitas \(\mathbf{h}_t\) para que a tradicional Regressão Logística Multinomial preveja a próxima palavra.
Parâmetros e Geração: Quem é quem?
Para consolidar o fluxo do modelo probabilístico:
- As Matrizes de Pesos \(W\) (\(W_{emb}, W^Q, W^K, W^V, W_U\), etc.) são os parâmetros estimáveis do modelo (\(\boldsymbol{\theta}\)). Eles são reais, estáticos após o treino, e estimados via Máxima Verossimilhança (minimizando a entropia cruzada).
- O Retorno para a Softmax ocorre projetando o vetor de características contextualizado \(\mathbf{h}_t \in \mathbb{R}^d\) de volta ao vocabulário via \(W_U \in \mathbb{R}^{V \times d}\), gerando os logits \(\mathbf{z}_t = W_U \mathbf{h}_t + \mathbf{b} \in \mathbb{R}^V\). A função Softmax atua como a função de ligação, normalizando esses logits em probabilidade para cada uma das \(V\) palavras.
- Quem é \(\dot{\mathbf{x}}_{t+1}\)? É o token na posição \(t+1\) codificado em One-Hot:
- No Treinamento: É o token real e fixo do corpus de treino (usado para calcular a perda).
- Na Inferência: É a realização amostrada da distribuição \(\dot{\mathbf{x}}_{t+1} | \dot{\mathbf{x}}_{1:t} \sim \text{Multinomial}(1,(\boldsymbol{p}_\theta(\dot{\mathbf{x}}_{1:t}))\). Uma vez selecionado, \(\dot{\mathbf{x}}_{t+1}\) é anexado ao histórico \(\dot{\mathbf{x}}_{1:t+1}\) para prever o próximo.
Inteligência Artificial - LLMs
Alguns conceitos importantes quando se trabalha com algoritmos de LLMs, são:
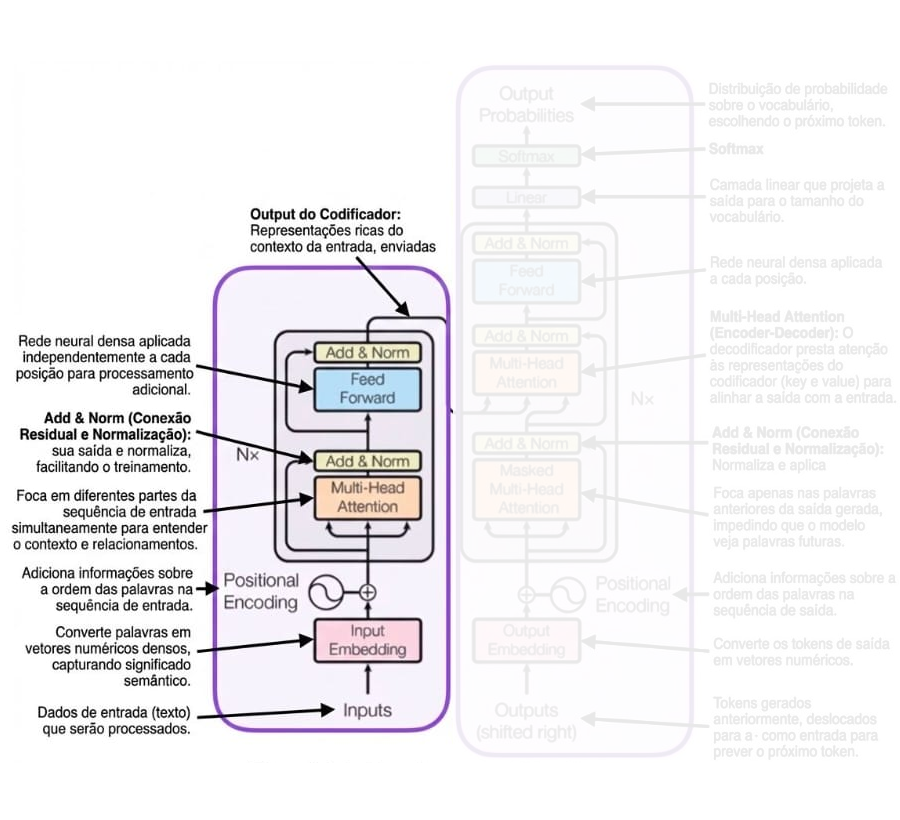
Tokenização: Os dados de entrada são divididos em tokens;
Embedding: cada token é transformado em um vetor denso;
Camadas de Encoder: processam e refinam os embeddings;
Self-Attention Mechanism: Cada token avalia a importância de todos os outros.
Saída do Encoder: Conjunto de embeddings contextuais.
Inteligência Artificial - LLMs
Alguns conceitos importantes quando se trabalha com algoritmos de LLMs, são:
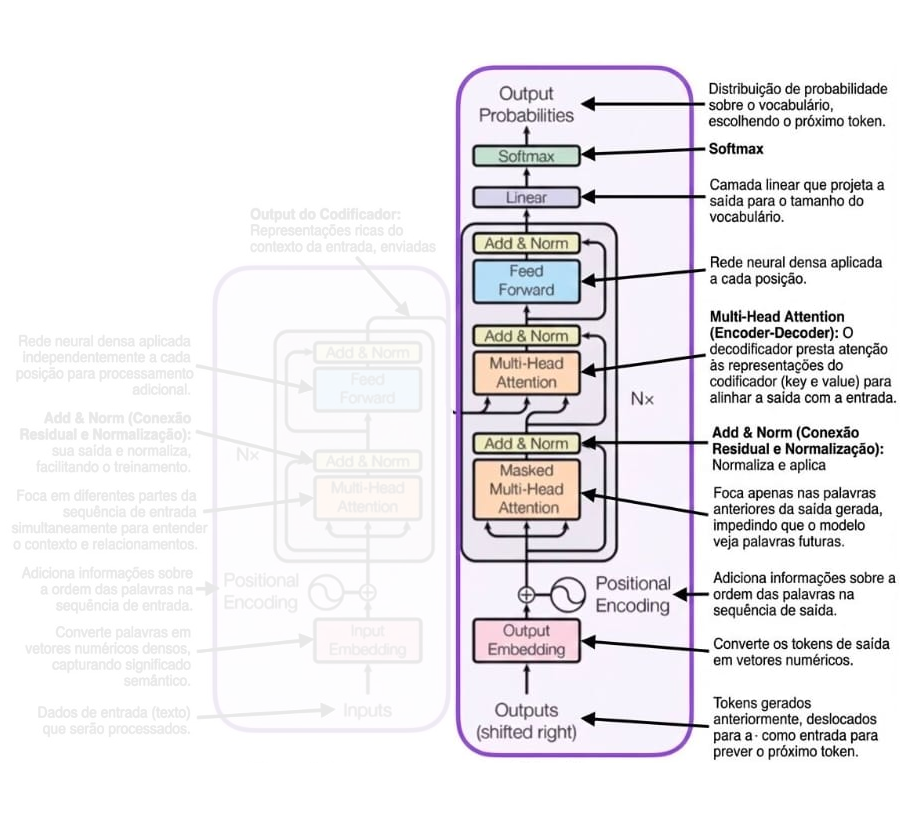
Preparação da Entrada do Decoder: A entrada do decoder é preparada os embeddings contextuais do encoder;
Camada de Self-Attention do Decoder: Semelhante ao encoder, o decoder usa múltiplas cabeças de atenção para capturar diferentes aspectos da relação entre tokens, mas respeitando a ordem causal;
Camada de Atenção Encoder-Decoder: A camada de atenção encoder-decoder permite que o decoder se concentre em diferentes partes da entrada do encoder, dependendo do token que está sendo gerado.
Saída do Decoder: O resultado do decoder é um conjunto de embeddings contextuais finais, que são usados para prever o próximo token na sequência de saída.
Predição do Próximo Token: O modelo prediz o próximo token na sequência de saída com base nos embeddings contextuais finais.
Geração Autoregressiva de Texto
Após estimar os parâmetros, o texto é gerado de forma autoregressiva. O token gerado é inserido no contexto e o processo é repetido até gerar o token <EOS>.
\[
f(x_1, \dots, x_k) \to x_{k+1}
\] \[
f(x_1, \dots, x_k, x_{k+1}) \to x_{k+2}
\] \[
\vdots
\]
Para escolher o próximo token a partir das probabilidades, usamos técnicas como top-k e top-p.
Inteligência Artificial - LLMs
Entretanto, vamos falar primeiramente definições de Top-k e Top-p e depois detalharemos sobre a Temperatura.
- Top-k
O parâmetro top-k limita as previsões do modelo aos k tokens mais prováveis em cada etapa da geração. Ao definir um valor para k, você está instruindo o modelo a considerar apenas os k tokens mais prováveis. Isso pode ajudar a ajustar a saída gerada e garantir que ela siga padrões ou restrições específicas.
Inteligência Artificial - LLMs
- Top-p, também conhecido como amostragem por núcleo (nucleus sampling), controla a probabilidade cumulativa dos tokens gerados. O modelo gera tokens até que a probabilidade cumulativa exceda o limite escolhido (p). Essa abordagem permite um controle mais dinâmico sobre o comprimento do texto gerado e incentiva a diversidade na saída, incluindo tokens menos prováveis quando necessário.
O top-k proporciona uma aleatoriedade controlada ao considerar um número fixo de tokens mais prováveis, enquanto o top-p permite um controle dinâmico sobre o número de tokens considerados, resultando em diferentes níveis de diversidade no texto gerado.
Inteligência Artificial - LLMs
A probabilidade cumulativa refere-se ao somatório das probabilidades de um conjunto de eventos ou opções, somadas em ordem decrescente de probabilidade até que um certo limite seja atingido
Exemplo:
Suponha que o modelo tenha os seguintes tokens candidatos, com suas probabilidades associadas:
| Token A |
0,40 |
| Token B |
0,30 |
| Token C |
0,15 |
| Token D |
0,10 |
| Token E |
0,05 |
Inteligência Artificial - LLMs
Agora, se você definir top-p = 0,85, o modelo irá selecionar tokens até que a probabilidade cumulativa atinja 0,85.
- Token A: 0,40 (probabilidade cumulativa = 0,40)
- Token B: 0,30 (probabilidade cumulativa = 0,40 + 0,30 = 0,70)
- Token C: 0,15 (probabilidade cumulativa = 0,70 + 0,15 = 0,85)
Assim, apenas os tokens A, B e C serão considerados, pois a soma de suas probabilidades atinge 0,85. Tokens com probabilidade mais baixa (como D e E) serão excluídos da escolha, a menos que top-p seja aumentado.
Inteligência Artificial - LLMs
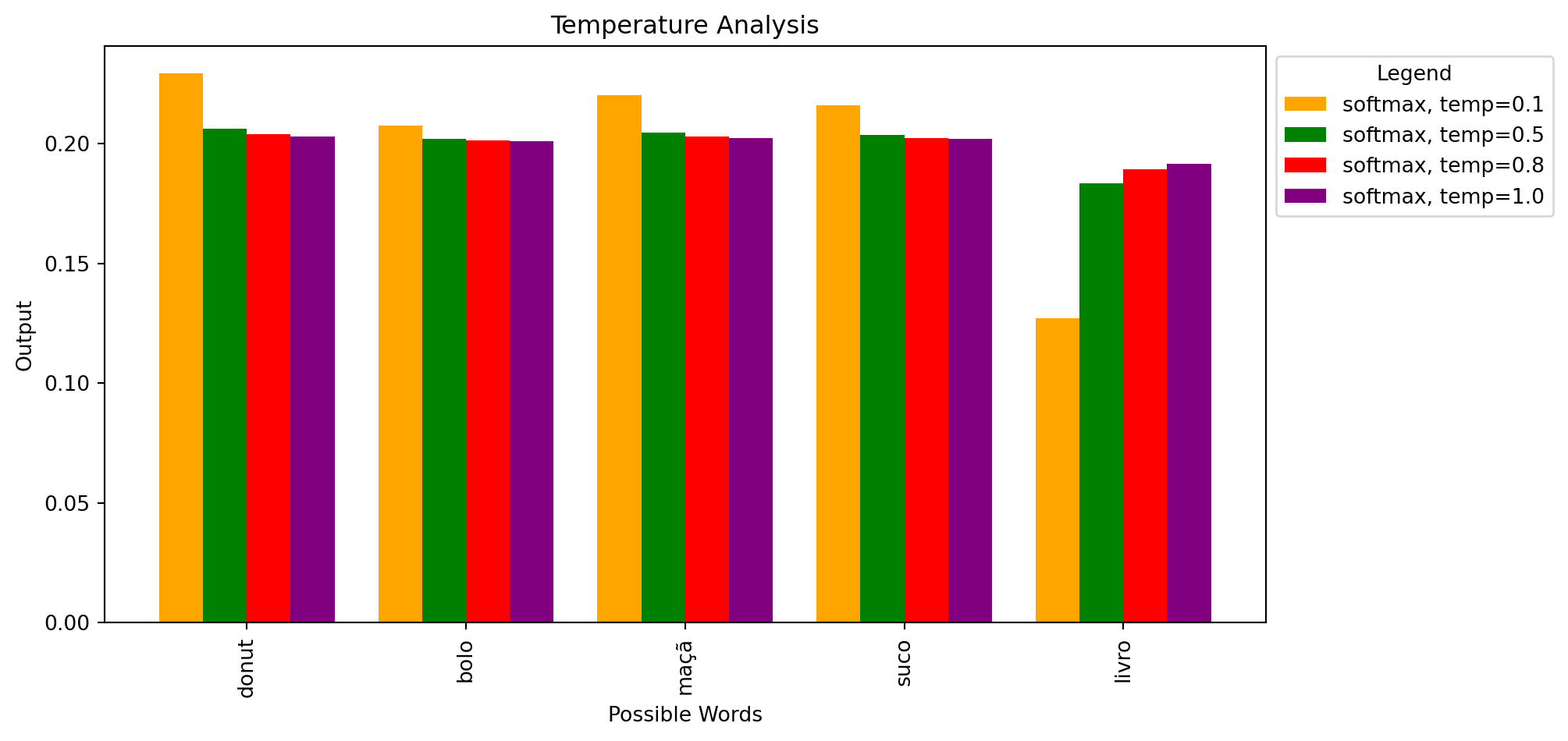
- Temperatura: em geral é aplicada primeiro. Ela ajusta as probabilidades de todos os tokens candidatos, “suavizando” ou “acentuando” a distribuição de probabilidade.
- Com uma temperatura baixa (próxima de 0), as probabilidades mais altas se destacam, e o modelo tende a ser mais conservador, escolhendo sempre os tokens mais prováveis. Com uma temperatura alta (próxima de 1), a distribuição fica mais uniforme, permitindo maior aleatoriedade.
Função de Ativação softmax:
\[softmax(z_i) = \frac{e^{z_i}}{\sum_{j=1}^V e^{z_j}},\]
em que \(z_i\) é o logit do token \(i\) e \(V\) é o tamanho do vocabulário.
Inteligência Artificial - LLMs
O parâmetro de temperatura é aplicado diretamente à função softmax.
\[softmax(z_i, T) = \frac{e^{\frac{z_i}{T}}}{\sum_{j=1}^V e^{\frac{z_j}{T}}},\]
onde \(T\) é a temperatura.
Efeito da Temperatura
À medida que a temperatura se aproxima de 0, as probabilidades de saída se tornam mais “agudas”. Uma das probabilidades ficará próxima de 1.
Conforme a temperatura aumenta, as probabilidades de saída se tornam mais “planas” ou “uniformes”, reduzindo a diferença entre as probabilidades dos diferentes elementos.
O intervalo do parâmetro de temperatura é definido entre 0 e 1 na documentação da OpenAI. No contexto da Cohere, os valores de temperatura estão dentro do intervalo de 0 a 5.
Inteligência Artificial - LLMs
- Artigo para ver sobre temperatura1.
Capacidades e Limitações
(Visão Moderna)
O que esses modelos modernos podem fazer?
- Continuar texto mantendo coerência em diversas línguas.
- Ajudar a provar teoremas (guiados por especialistas).
- Escrever códigos (R, Python, C, etc.).
- Explicar teorias, resolver quebra-cabeças, corrigir gramática.
Problemas:
Inteligência Artificial - LLMs
Em termos práticos, alguns problemas que temos com LLMs (SLMs) são:
- Alucinações: o modelo gera informações que não estão presentes nos dados de treinamento;
- Viés: o modelo pode reproduzir e amplificar preconceitos e estereótipos presentes nos dados de treinamento;
- Insegurança: o modelo pode fornecer respostas incorretas ou enganosas, sem indicar que não tem certeza sobre a resposta;
- Incapacidade de generalização: o modelo pode ter dificuldade em lidar com situações fora do conjunto de dados de treinamento.
Inteligência Artificial - LLMs
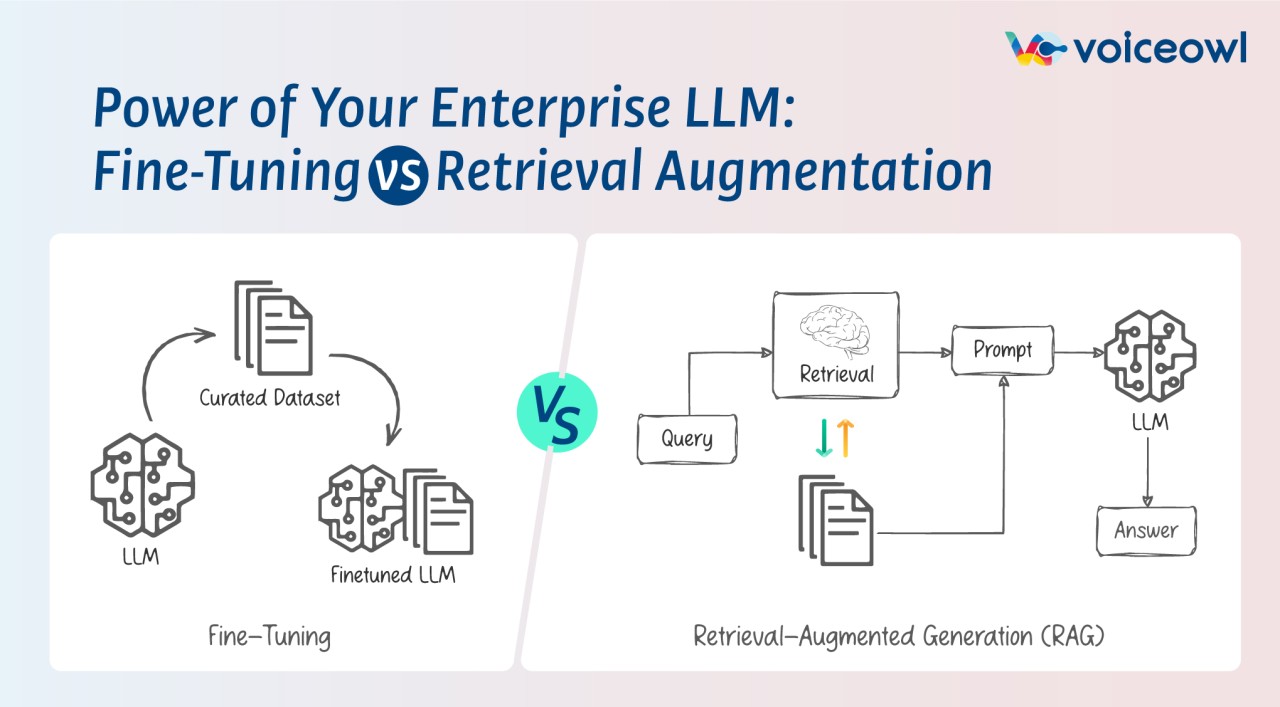
Duas alternativas para mitigar esses problemas são:
Fine-Tuning: ajustar o modelo para um conjunto de dados específico, para que ele possa aprender a tarefa desejada;
RAG (Retrieve and Generate): que é um modelo que combina a capacidade de recuperar informações de um grande banco de dados com a capacidade de gerar texto de um modelo de linguagem.
Referências
Patriota, A. G. (2024). O modelo estatístico por trás dos Modelos de Linguagem Modernos. Apresentação para o V EPBEST.
Reid, Machel, et al. (2024). Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530 .
Vaswani, A., N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin (2017). Attention is all you need. Advances in neural information processing systems 30.
Devlin, J., M.-W. Chang, K. Lee, and K. Toutanova (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Referências
Fontes das imagens utilizadas: