Redes Neurais
Dropout
Dropout
- A ideia básica do Dropout é desligar (ou “drop”) aleatoriamente uma fração dos neurônios durante o treinamento, o que força a rede a não depender de neurônios específicos, mas sim a aprender representações mais robustas dos dados.
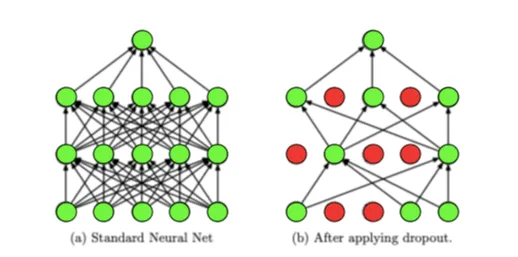
- Isso previne que as unidades se adaptem excessivamente umas às outras.
Dropout
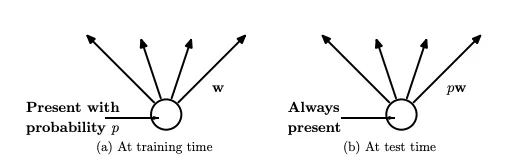
Como o dropout remove algumas das unidades de uma camada, uma rede com dropout ponderará as unidades restantes mais fortemente durante cada execução de treinamento para compensar as entradas ausentes.
No entanto, no momento do teste, não é viável usar os pesos do modelo treinado em seus estados exagerados e, portanto, cada peso é reduzido multiplicando-se pelo hiperparâmetro \(p\).
Esse fenômeno pode ser observado no exemplo abaixo.
Vamos observar uma rede com quatro unidades em uma camada (imagem abaixo). O peso em cada unidade será inicialmente \(\dfrac{1}{4} = 0.25\).

Dropout
- Se aplicarmos dropout com \(p = 0.5\) a essa camada, ela poderia acabar se parecendo com a seguinte imagem:

Como podemos ver, duas unidades foram “desligadas” aleatoriamente.
Isso significa que as conexões dessas unidades foram removidas temporariamente da rede.
Como apenas duas unidades são consideradas, cada uma terá um peso inicial de \(\dfrac{1}{2} = 0.5\).
Dropout
No entanto, o dropout é usado apenas no treinamento, então não queremos que esses pesos fiquem fixos nesse valor alto durante o teste.
Para resolver esse problema, quando passamos para a fase de teste, multiplicamos os pesos por \(p\) (como visto na imagem abaixo), terminando com \(0.5*0.5 = 0.25\), que nesse caso, coincidentemente foi igual ao peso inicial correto.