mpg cyl disp
Mazda RX4 21.0 6 160
Mazda RX4 Wag 21.0 6 160
Datsun 710 22.8 4 108Introdução à Ciência de Dados
Markdown e RMarkdown
Prof. Jodavid Ferreira
UFPE
Markdown e RMarkdown
Markdown
O Markdown é uma linguagem de marcação leve, criada em 2004 por John Gruber, com o objetivo de ser fácil de escrever e ler em formato de texto plano. Ele é amplamente utilizado para formatação de textos em arquivos simples, como documentação, blogs, e também para criar apresentações.
Uma linguagem de marcação leve é um tipo de linguagem que foi projetada para ser simples, e essa simplicidade é definida por algumas características, como: Sintaxe Simples, Legibilidade, Conversão Fácil, Foco no Conteúdo e Portabilidade.
Markdown
Sintaxe Simples: A sintaxe é minimalista e intuitiva, permitindo que o conteúdo seja formatado com poucos caracteres especiais. Isso torna a escrita mais rápida e reduz a probabilidade de erros.
Legibilidade: Mesmo sem renderizar, o documento escrito é facilmente legível por humanos. O texto se parece muito com o que você veria em um editor de texto simples, com apenas pequenas adições para formatar o conteúdo.
Conversão Fácil: Documentos podem ser facilmente convertidos para outros formatos mais complexos, como HTML, PDF, ou DOCX, utilizando ferramentas de conversão.
Foco no Conteúdo: Essas linguagens priorizam a clareza e a simplicidade do conteúdo, sem exigir que o autor tenha que se preocupar com detalhes de apresentação ou formatação avançada.
Portabilidade: Por ser baseada em texto plano, gera arquivos pequenos e fáceis de compartilhar, o que é ideal para colaboração e controle de versão.
Markdown
O Markdown é projetado para converter texto simples em HTML.
Ele utiliza uma sintaxe simples e intuitiva para formatação, permitindo adicionar cabeçalhos, listas, links, imagens, negrito, itálico, e muito mais, sem a complexidade de tags HTML.
Entretanto, o Markdown não se limita a HTML. Ele pode ser convertido em vários outros formatos, como PDF, DOCX, e PPT.
Conversão para Outros Formatos: Markdown pode ser facilmente convertido em diversos formatos usando ferramentas como Pandoc ou reveal.js. Isso permite flexibilidade na escolha do meio de apresentação.
Pandocé geralmente usado para converter documentos para formatos como HTML, PDF, DOCX, LaTeX, EPUB, entre outros.reveal.jsé uma biblioteca JavaScript que permite criar apresentações de slides interativas e modernas diretamente a partir de arquivos HTML ou Markdown
Markdown
Markdown é o formato utilizado para criar arquivos README no GitHub.
O que é o README do GitHub?
O README é um arquivo essencial em repositórios de código no GitHub. Ele geralmente está localizado na raiz do repositório e é o primeiro lugar onde os visitantes do repositório olham para obter informações sobre o projeto.
Principais Funcionalidades do README:
- Introdução ao Projeto: Descreve o propósito do projeto, seus objetivos e como ele pode ser útil.
- Instruções de Instalação: Fornece orientações detalhadas sobre como configurar o ambiente e instalar as dependências necessárias para rodar o projeto.
Markdown
- Exemplos de Uso: Apresenta exemplos práticos de como utilizar o projeto, o que pode incluir trechos de código, capturas de tela ou links para demonstrações.
- Documentação: Pode incluir links para documentação mais detalhada, como tutoriais, guias de uso ou referências API.
- Licença e Contribuições: Informa sobre a licença do projeto e como outros desenvolvedores podem contribuir.
O README no GitHub é escrito em Markdown porque essa linguagem permite que o conteúdo seja facilmente formatado e mantido legível, ao mesmo tempo que pode ser renderizado em HTML para exibição diretamente no navegador. Por isso, você verá elementos como títulos, listas, links, e imagens no README, todos formatados de maneira simples e intuitiva usando Markdown.
Markdown
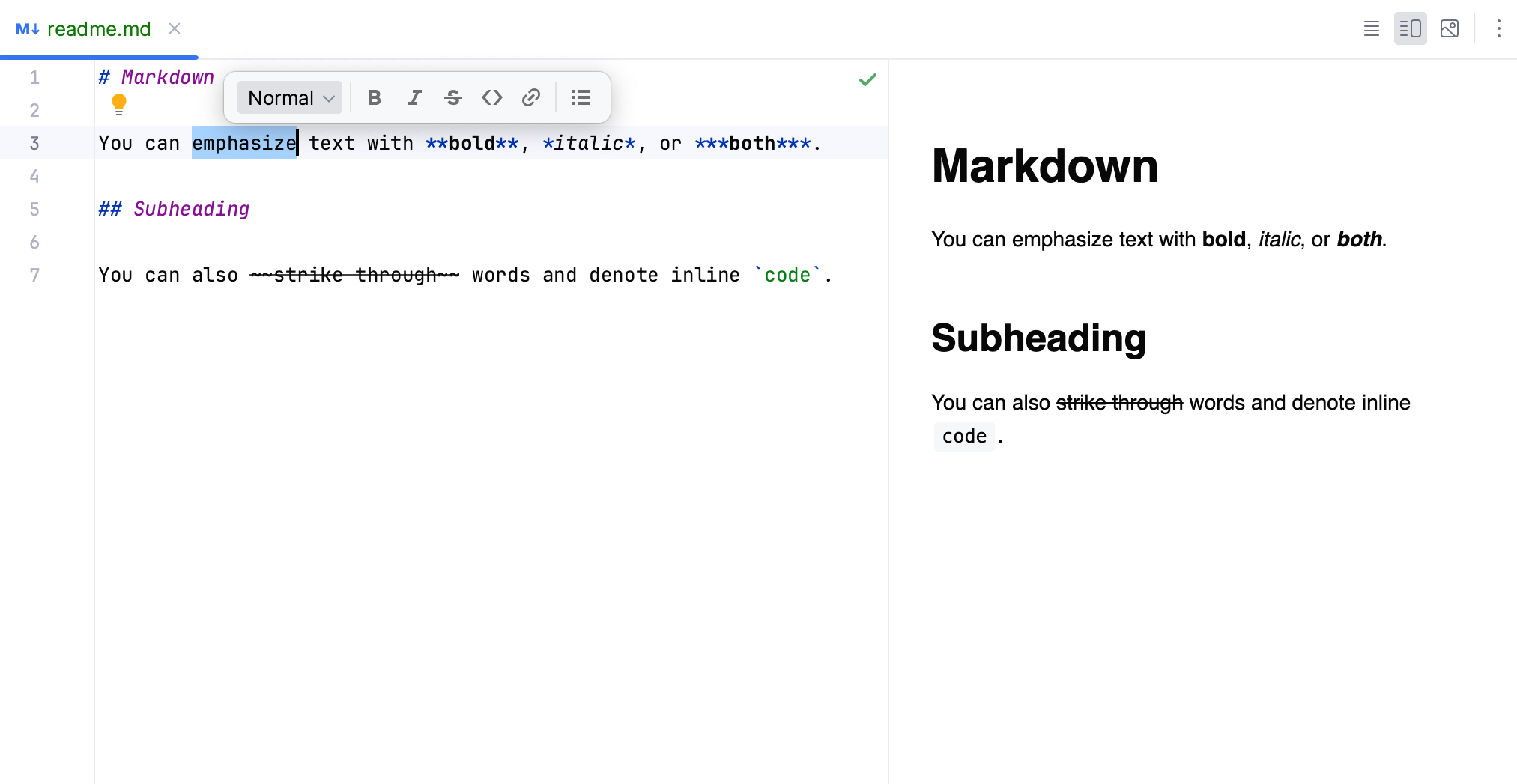
fonte: https://resources.jetbrains.com/help/img/idea/2024.2/markdown-basics.png
Markdown

Markdown

Markdown
Vamos praticar:
- Crie um arquivo no Rstudio com extensão
.md - Adicione os seguintes elementos:
# Projeto de Exemplo

Bem-vindo ao **Projeto de Exemplo**! Este projeto demonstra como documentar um repositório GitHub usando Markdown.
## Índice
1. [Descrição](#descrição)
2. [Instalação](#instalação)
3. [Uso](#uso)
- [Exemplo de Execução](#exemplo-de-execução)
4. [Contribuição](#contribuição)
5. [Licença](#licença)
## Descrição
Este projeto é um exemplo básico de como estruturar uma documentação de README no GitHub utilizando Markdown.
## Instalação
Para instalar o projeto, siga os passos abaixo:
git clone https://github.com/seu-usuario/seu-repositorio.git
cd seu-repositorio
## Uso
Para usar o projeto, execute o seguinte comando:
python main.py
### Exemplo de Execução
Aqui está um exemplo de como os resultados devem aparecer:
Resultado: 42
## Configurações
| Parâmetro | Descrição | Valor Padrão |
|-----------|---------------------|--------------|
| `--input` | Caminho do arquivo de entrada | `input.txt` |
| `--output`| Caminho do arquivo de saída | `output.txt` |
## Contribuição
Contribuições são bem-vindas! Siga os passos abaixo para contribuir:
1. Faça um _fork_ do repositório.
2. Crie uma nova _branch_ (`git checkout -b feature/nova-funcionalidade`).
3. Faça _commit_ das suas mudanças (`git commit -m 'Adiciona nova funcionalidade'`).
4. Faça _push_ para a _branch_ (`git push origin feature/nova-funcionalidade`).
5. Abra um _Pull Request_.
## Licença
Este projeto está licenciado sob a [MIT License](LICENSE).
## Links Úteis
- [Documentação Oficial do Python](https://docs.python.org/3/)
- [Guia de Markdown no GitHub](https://guides.github.com/features/mastering-markdown/)
RMarkdown
Markdown no R
RMarkdown
- O RMarkdown é uma extensão do Markdown que permite a inclusão de código R em um documento Markdown.
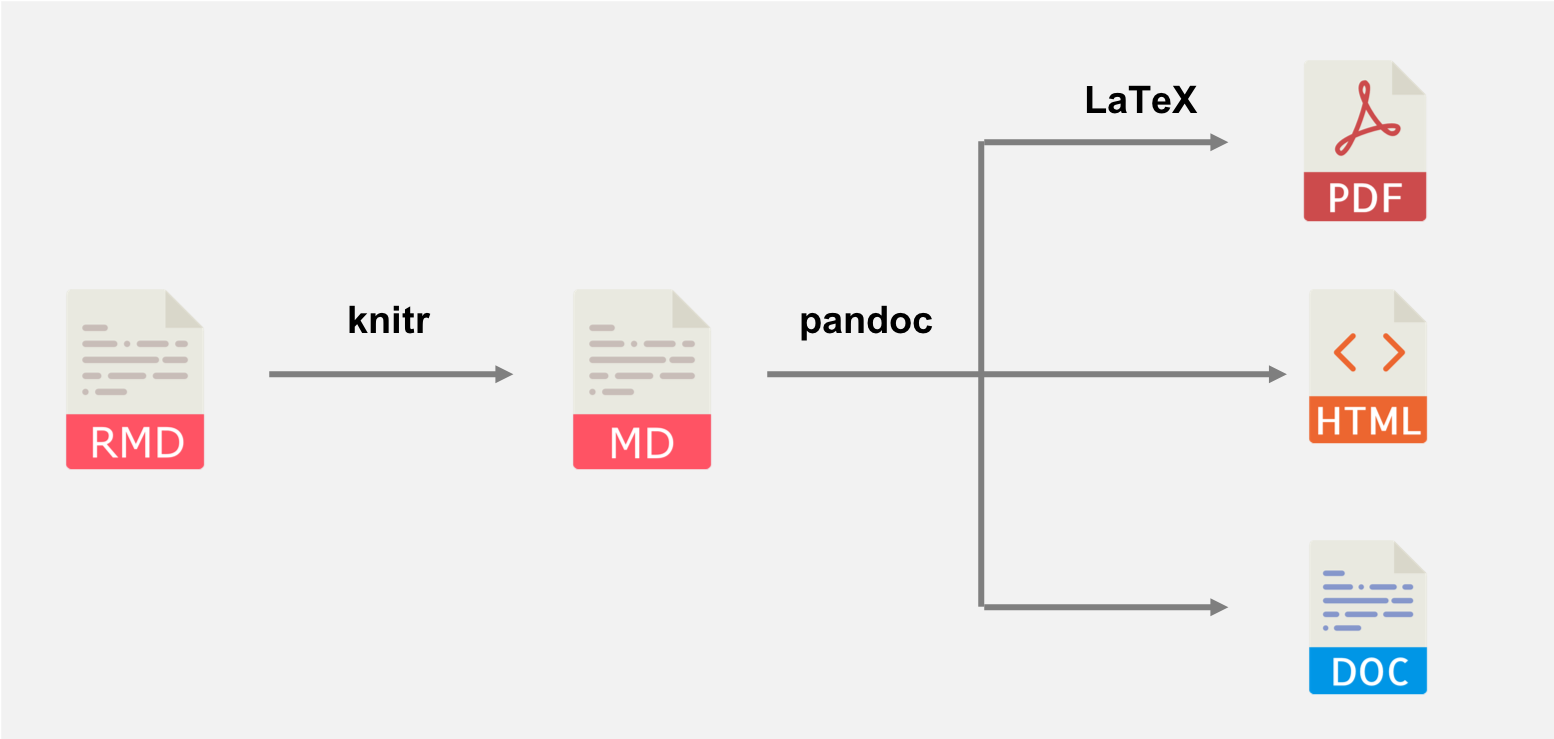
RMarkdown
O documento
.Rmdcontém uma combinação de YAML (metadados), texto (narrativas) e blocos de código (chunks).Primeiro, a função
knit()do pacote knitr é usada para executar todo o código embutido no arquivo.Rmde preparar a saída do código para ser exibida no documento. Todos esses resultados são convertidos para a linguagem de marcação correta e contidos em um arquivo temporário.md.Em seguida, o arquivo
.mdé processado pelo Pandoc, que utiliza quaisquer parâmetros especificados no YAML do documento (por exemplo, título, autor e data) para converter o documento no formato de saída especificado no parâmetro de saída (comohtml_documentpara saída em HTML).
RMarkdown
Se o formato de saída for PDF, há uma camada adicional de processamento, pois o Pandoc converterá o arquivo
.mdintermediário em um arquivo.texintermediário. Este arquivo é então processado pelo LaTeX para formar o documento PDF final.- Nesse caso, o rmarkdown chama a função
latexmk()do pacote tinytex, que, por sua vez, chama o LaTeX para compilar.texpara.pdf.
- Nesse caso, o rmarkdown chama a função
Não são todos os documentos R Markdown são eventualmente compilados através do Pandoc. O arquivo
.mdintermediário pode ser compilado por outros renderizadores de Markdown. Abaixo estão dois exemplos:O pacote xaringan passa a saída
.mdpara uma biblioteca JavaScript, que renderiza o conteúdo Markdown no navegador da web.O pacote blogdown suporta o formato de documento
.Rmarkdown, que é transformado em.markdown, e esse documento Markdown geralmente é renderizado para HTML por um gerador de sites externo.
RMarkdown
Vamos praticar:
- Crie um arquivo no Rstudio com nome
diamond_sizes.Rmd - Adicione os seguintes elementos:
---
title: "Diamond sizes"
date: "29-08-2024"
output: html_document
---
` ` `{r setup, echo=TRUE, eval=FALSE}
library(ggplot2)
library(dplyr)
smaller <- diamonds |>
filter(carat <= 2.5)
` ` `
Nós temos dados sobre o ` r nrow(diamonds) ` observações de diamantes.
Apenas ` r nrow(diamonds) - nrow(smaller) ` diamantes são maiores de 2.5 quilates.
A distribiuição dos tamanhos dos diamantes menores que 2.5 quilates é mostrada no gráfico abaixo:
` ` `{r plot, echo=FALSE}
smaller |>
ggplot(aes(carat)) +
geom_freqpoly(binwidth = 0.1)
` ` `
RMarkdown
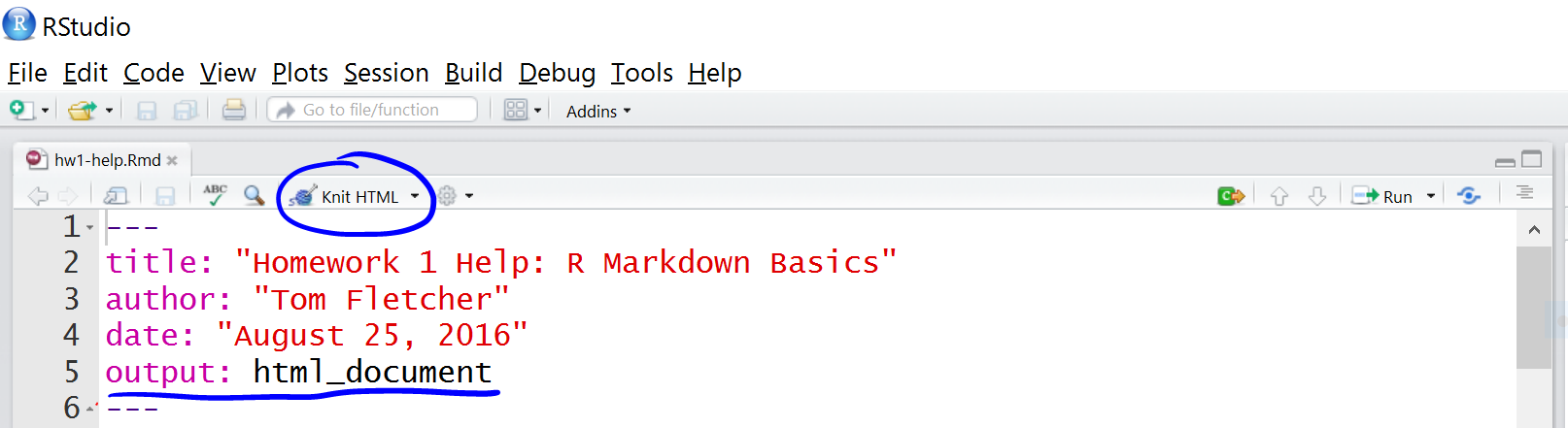
Para reproduzir o relatório, pode-se utilizar:
- o comando
rmarkdown::render("diamond_sizes.Rmd")no console do RStudio. - Cmd/Ctrl + Shift + K no RStudio.
- Clicando no botão “Knit” ou ’Render” que fica próximo ao botão de salvar no RStudio.
- o comando
RMarkdown
Trechos de Código - Chunks
Os trechos de código são blocos de código R (python, bash, atualmente suportam outras linguagens) que são executados e exibem seus resultados no documento final.
Eles são delimitados por três crases e uma chave de abertura
{r}no início e uma chave de fechamento no final.É possível associar nomes aos chunks que possui três vantagens:
- Navegar mais facilmente para um chunk específico usando o navegador de código drop-down no canto inferior esquerdo do editor de script;
- Gráficos produzidos pelos chunks terão nomes úteis que facilitam seu uso em outros lugares1.
- Você pode configurar redes de chunks em cache para evitar realizar cálculos computacionalmente custosos em cada execução.
RMarkdown
Opções de Chunk
A saída do chunk pode ser customizada com opções, ou seja, argumentos fornecidos para o header do chunk.
Vamos ver alguns exemplos de opções de chunk1:
eval: controla se o código R no chunk é executado. A opção FALSE é útil para incluir código R no documento sem executá-lo.echo: controla se o código R no chunk é exibido no documento final. A opção FALSE é útil para incluir código R no documento sem exibi-lo.include: também controla se o chunk é incluído no documento final. Mas nesse caso, a opção FALSE executa o código mas não mostra os resultados e o código no documento final. Ideal para códigos intermediários que vocẽ não deseja mostra o resultado e o código.
RMarkdown
Opções de Chunk
message: controla se as mensagens de saída do código R são exibidas no documento final. A opção FALSE é útil para suprimir mensagens de saída desnecessárias.warning: controla se as mensagens de aviso do código R são exibidas no documento final. A opção FALSE é útil para suprimir mensagens de aviso desnecessárias.error: controla se os erros do código R interrompem a execução do documento. A opção FALSE é útil para continuar a execução do documento, mesmo que ocorram erros no código R. O default é TRUE.
RMarkdown
Tabelas
Por padrão, a formatação do print direto do data frame e/ou matrizes é similar ao console
RMarkdown
Colocando em Cache
Algumas vezes partes do seu código podem ser computacionalmente custosas, e você não deseja executá-las toda vez que você renderiza o documento. Uma solução neste caso é colocar essa parte em cache para que ela seja executada apenas uma vez e os resultados sejam armazenados para uso futuro.
Vamos ver um exemplo abaixo de como fazer isso:
` ` `{r rawdata, echo=TRUE, eval=FALSE}
rawdata <- read.csv("dataset/used_cars_data.csv")
` ` `` ` `{r, echo=TRUE, eval=FALSE, cache=TRUE}
processed_rawdata <- rawdata |>
dplyr::select(c(`ano`,`quilometros_percorridos`)) |>
dplyr::filter(ano > 2010)
` ` `Neste exemplo anterior o chunk referente a variável processed_rawdata é executado apenas uma vez e os resultados são armazenados em cache para uso futuro. Entretanto, ele só será reexecutado se alguma alteração dentro do chunk for realizado. Se a alteração for feita no primeiro chunk, que está lendo o arquivo data.csv, o segundo chunk não será reexecutado.
RMarkdown
Colocando em Cache
A solução do problema anterior é colocar dependência no chunk sobre o qual as saídas estão sendo utilizadas:
` ` `{r rawdata_dep, echo=TRUE, eval=FALSE}
rawdata <- readr::read_csv("dataset/used_cars_data.csv")
` ` `` ` `{r, echo=TRUE, eval=FALSE, cache=TRUE, dependson=rawdata_dep}
processed_rawdata <- rawdata |>
dplyr::select(c(ano,quilometros_percorridos)) |>
dplyr::filter(ano > 2010)
` ` `O dependson é uma opção que permite que você especifique quais chunks devem ser reexecutados se houver alterações neles. Neste caso, o chunk processed_rawdata será reexecutado se houver alterações no chunk rawdata_dep, ou seja, o knitr atualizará os resultados para o chunk em cache sempre que detectar que uma de suas dependências mudou.
RMarkdown
YAML
Sobre o YAML no RMArkdown:
No R Markdown, o YAML é usado para definir metadados do documento, como título, autor, data, formato de saída, e outras opções de renderização.
O YAML é colocado no início do documento R Markdown, entre três hífens
---no início e no final.A definição do tipo de saída é feita no YAML, e defininda na opção output e pode ser adicionado as seguintes saída:
html_document,pdf_document,word_document,beamer_presentation,ioslides_presentation,slidy_presentation,revealjs::revealjs_presentation, entre outros.
RMarkdown
Um exemplo para html é:
---
title: "Título do Documento"
author: "Autor do Documento"
date: "Data do Documento"
output: html_document
---
No caso para PDF seria:
---
title: "Título do Documento"
author: "Autor do Documento"
date: "Data do Documento"
output: pdf_document
---
RMarkdown
Dica de link: https://rmarkdown.rstudio.com/lesson-15.html
Referências para serem utilizadas
Livro: R for Data Science. Disponível em: https://r4ds.had.co.nz/
https://bookdown.org/yihui/rmarkdown-cookbook/rmarkdown-process.html
https://stackoverflow.com/q/40563479/559676
https://yihui.org/knitr/options/
https://rmarkdown.rstudio.com/lesson-15.html
https://gomesfellipe.github.io/post/2018-01-12-tabelas-incriveis-com-r/tabelas-incriveis-com-r/
OBRIGADO!
Slide produzido com quarto
Introdução à Ciência de Dados - Prof. Jodavid Ferreira