Problemática: Esta base de dados é referente a carros usados na ‘Índia’. Através dos dados existentes, quais informações relevantes poderíamos obter sobre esses carros usados do país em questão?
Python - Base de dados
=> id: Número único por linha para representar cada observação;
=> nome: Nome do carro usado
=> localizacao: Cidade de localização do carro na Índia
=> ano: Ano de fabricação do carro
=> quilometros_percorridos: Quilômetros percorridos pelo carro em km
=> tipo_de_combustivel: Tipo de combustível utilizado pelo carro
=> transmissao: Transmissão do carro
=> tipo_proprietario: Quantos donos o carro já possuiu
=> quilometragem_por_litro: Quantos km o carro faz com 1 lt
=> motor: Quantidade de cilindradas do motor
=> potencia: Potência do motor em bhp
=> assentos: Quantidade de assentos do carro
=> novo_preco: Variável que possui um preço do carro em LAKh
=> preco: Variável que possui preco do carro também em LAKh
Obs.: 1 Lakh, chamado de um laque, é uma unidade do sistema de numeração indiana. Um laque indiano equivale a 100.000 (cem mil) rupias indianas. E 1 rupia equivale a 0,06 centavos. Assim, 1 Lakh = 6.415,62 reais.
Python - Importação das Bibliotecas
O primeiro passo nesse caso é importar bibliotecas necessárias para análise:
# -----------------# Bibliotecas necessarias para Analise dos Dadosimport pandas as pdimport numpy as npimport scipy as sp# -----------------# Bibliotecas Gráficasimport matplotlib.pyplot as pltimport seaborn as sns# -----------------import plotly.express as px# -----------------
# -----------------# Lendo a Base de dadosdados = pd.read_csv("dataset/used_cars_data.csv")# -----------------
Visualizando um cabeçalho dos dados
# -----------------# Visualizando um cabeçalho dos dadosdados.head()
id nome localizacao ... assentos novo_preco preco
0 0 Maruti Wagon R LXI CNG Mumbai ... 5.0 NaN 1.75
1 1 Hyundai Creta 1.6 CRDi SX Option Pune ... 5.0 NaN 12.50
2 2 Honda Jazz V Chennai ... 5.0 8.61 Lakh 4.50
3 3 Maruti Ertiga VDI Chennai ... 7.0 NaN 6.00
4 4 Audi A4 New 2.0 TDI Multitronic Coimbatore ... 5.0 NaN 17.74
[5 rows x 14 columns]
# -----------------
# -----------------# Visualizando os últimos dadosdados.tail()# -----------------
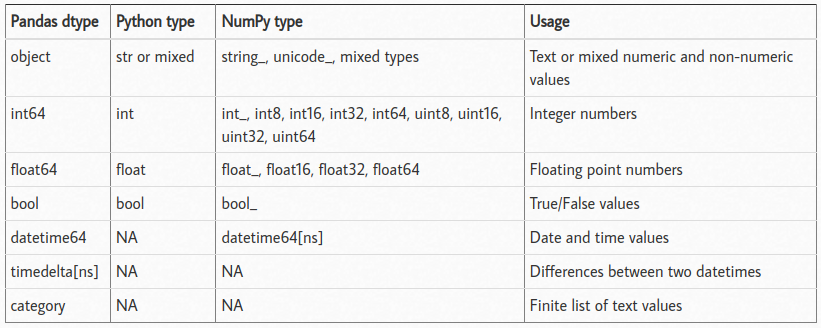
Python - Tipos das variáveis
# -----------------# Visualizando Informações das colunasdados.info()
nome
Mahindra XUV500 W8 2WD 55
Maruti Swift VDI 49
Maruti Swift Dzire VDI 42
Honda City 1.5 S MT 39
Maruti Swift VDI BSIV 37
..
Chevrolet Beat LT Option 1
Skoda Rapid 1.6 MPI AT Elegance Plus 1
Ford EcoSport 1.5 TDCi Ambiente 1
Hyundai i10 Magna 1.1 iTech SE 1
Hyundai Elite i20 Magna Plus 1
Name: count, Length: 2041, dtype: int64
# ---------------------
Python - Variáveis Qualitativas
Calculando frequências quando as variáveis são categóricas
tipo_proprietario First Fourth & Above Second Third
transmissao
Automatic 1682 1 332 34
Manual 4270 11 820 103
# ---------------------
# ---------------------# Teste de Qui-Quadradofrom scipy.stats import chisquarefrom scipy.stats import chi2_contingency# Aplicando Teste Qui-Quadrado na Tabela. c, p, dof, expected = chi2_contingency(tabela_cruzada)print(p)
0.34358871263824625
# ---------------------
Python - Variáveis Qualitativas
Criando tabelas cruzadas entre as variáveis
# ---------------------# Teste de Qui-Quadrado com Transmissao e Localizaçãotabela_cruzada = pd.crosstab(dados['transmissao'], dados['localizacao']) # ---c, p, dof, expected = chi2_contingency(tabela_cruzada)print(p)
1.3894902634085349e-55
# ---------------------
# ---------------------# Tabela Cruzada para Transmissao e Localizaçãotabela_cruzada
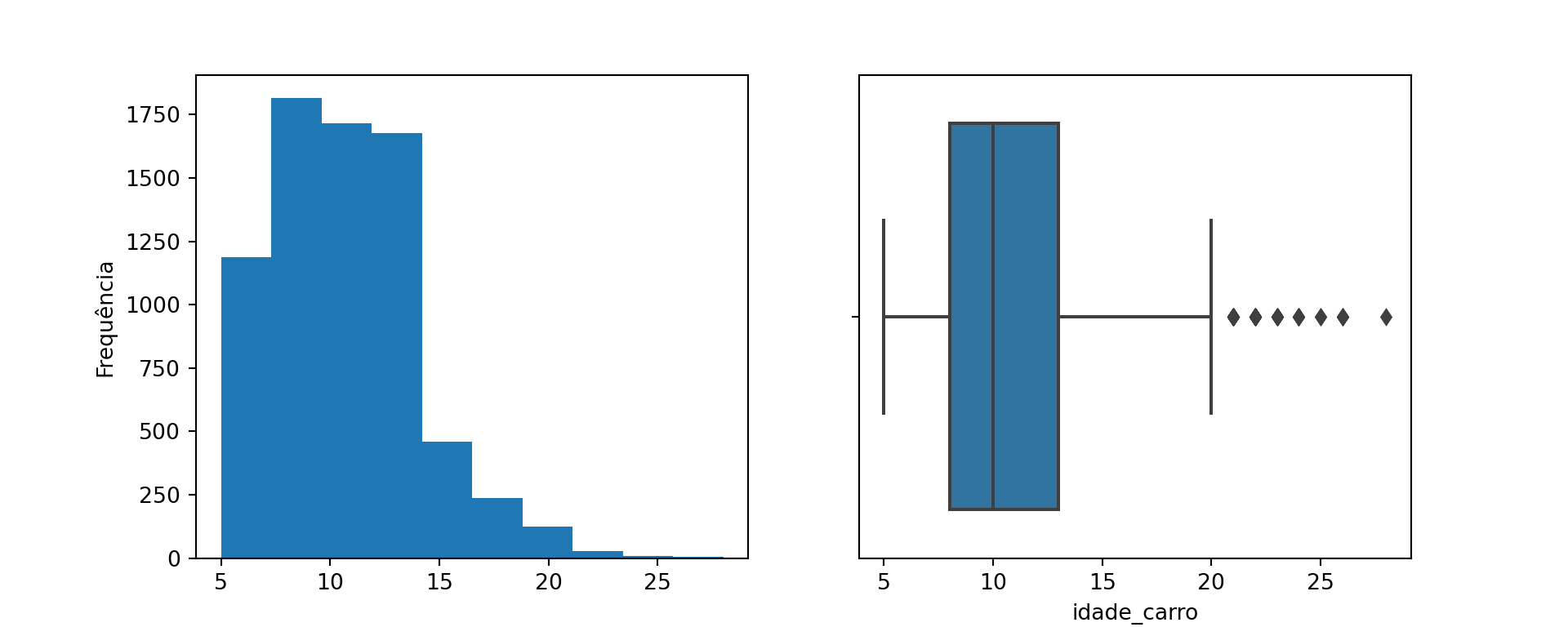
# -----------------# Criação da variável 'Car_Age'como uma novas variávelfrom datetime import date# ---print("O ano atual é: "+str(date.today().year) )
nome ... idade_carro
0 Maruti Wagon R LXI CNG ... 14
1 Hyundai Creta 1.6 CRDi SX Option ... 9
2 Honda Jazz V ... 13
3 Maruti Ertiga VDI ... 12
4 Audi A4 New 2.0 TDI Multitronic ... 11
... ... ... ...
7248 Volkswagen Vento Diesel Trendline ... 13
7249 Volkswagen Polo GT TSI ... 9
7250 Nissan Micra Diesel XV ... 12
7251 Volkswagen Polo GT TSI ... 11
7252 Mercedes-Benz E-Class 2009-2013 E 220 CDI Avan... ... 10
[7253 rows x 4 columns]
# -----------------
Python - Criação de variáveis
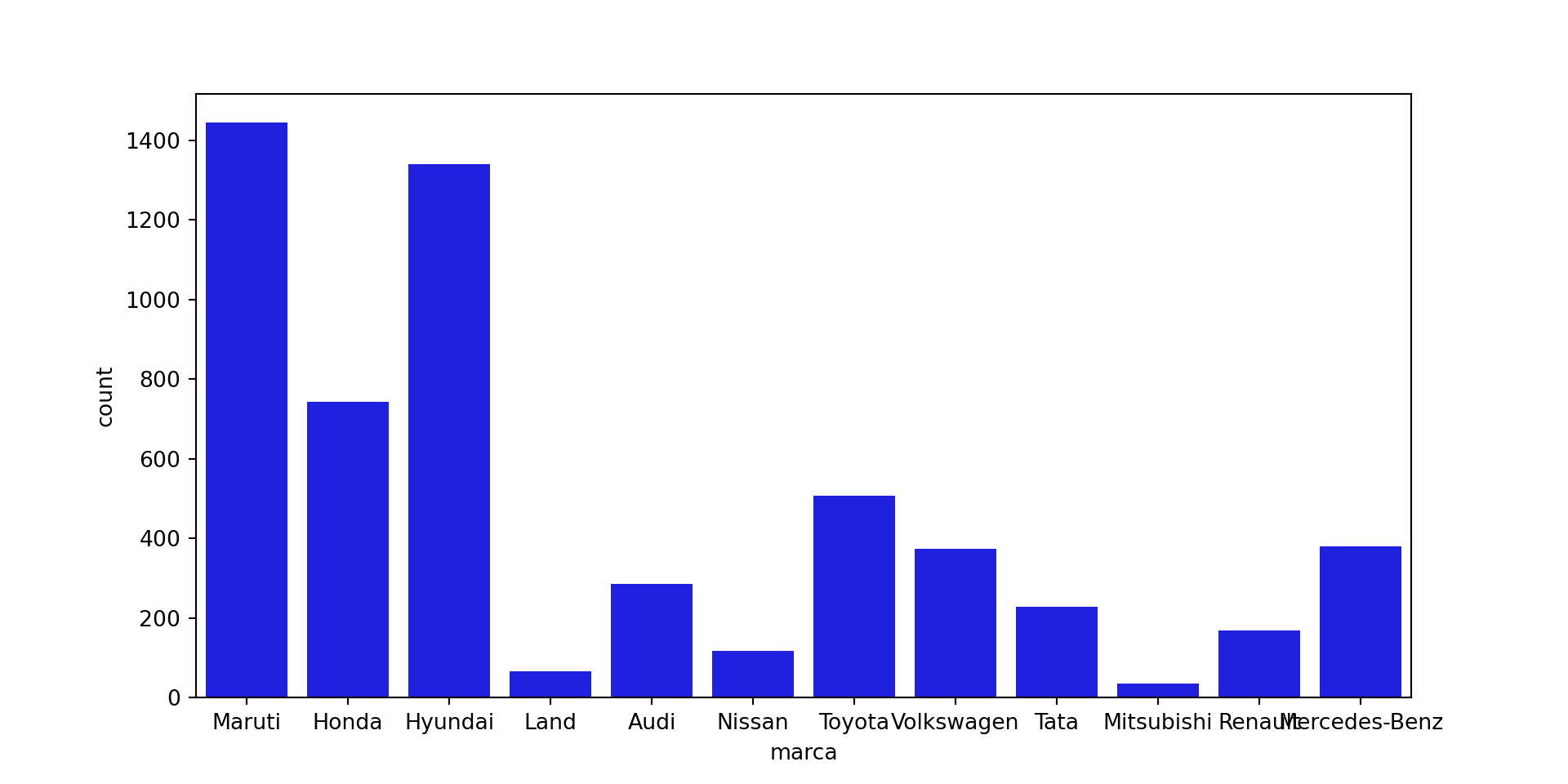
# -----------------# Criação da variável 'Marca' do carro# str.split: quebra as strings# str.get(0): pega todas as posições 0 de cada lista criada da linhadados['marca'] = dados.nome.str.split().str.get(0)# --dados[['nome','marca']].head()
nome marca
0 Maruti Wagon R LXI CNG Maruti
1 Hyundai Creta 1.6 CRDi SX Option Hyundai
2 Honda Jazz V Honda
3 Maruti Ertiga VDI Maruti
4 Audi A4 New 2.0 TDI Multitronic Audi
# -----------------
OBS.: Para retornar data.frames com duas ou mais colunas selecionadas, é necessário utilizar dois pares de [], ou seja, df[[colname(s)]]. O primeiro par retorna uma série, enquanto os colchetes duplos retornam um dataframe.
Python - Verificando variáveis
Antes dos gráficos, vamos verificar quais variáveis são numéricas e quais são categóricas
# -----------------fig, axes = plt.subplots(3, 2, figsize = (18, 18))fig.suptitle('Gráficos de Barras para todas as variáveis categóricas da base de dados')sns.countplot(ax = axes[0, 0], x ='tipo_de_combustivel', data = dados, color ='blue', order = dados['tipo_de_combustivel'].value_counts().index);sns.countplot(ax = axes[0, 1], x ='transmissao', data = dados, color ='blue', order = dados['transmissao'].value_counts().index);sns.countplot(ax = axes[1, 0], x ='tipo_proprietario', data = dados, color ='blue', order = dados['tipo_proprietario'].value_counts().index);sns.countplot(ax = axes[1, 1], x ='localizacao', data = dados, color ='blue', order = dados['localizacao'].value_counts().index);sns.countplot(ax = axes[2, 0], x ='marca', data = dados, color ='blue', order = dados['marca'].head(20).value_counts().index);sns.countplot(ax = axes[2, 1], x ='ano', data = dados, color ='blue', order = dados['ano'].head(20).value_counts().index);axes[1][1].tick_params(labelrotation=45);axes[2][0].tick_params(labelrotation=90);axes[2][1].tick_params(labelrotation=90);# -----------------
Gráficos de Barras entre duas variáveis categóricas e uma numérica
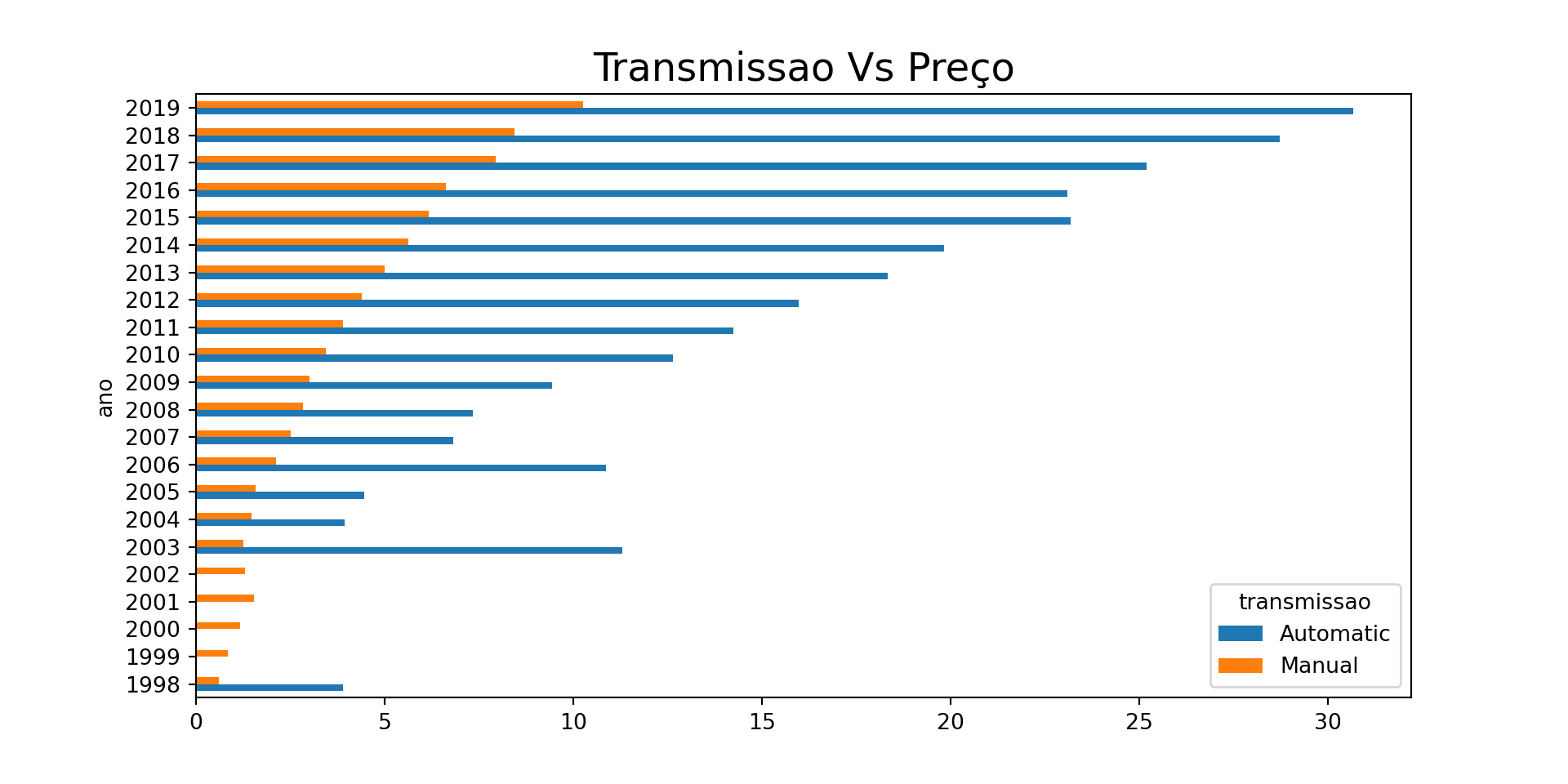
# -------------------# Criando uma Tabela para geração do gráfico distinta por categoriasdfp = dados.pivot_table(index='ano', columns='transmissao', values='preco', aggfunc='mean')# -------------------dfp.head(10)
transmissao Automatic Manual
ano
1998 3.900000 0.610000
1999 NaN 0.835000
2000 NaN 1.175000
2001 NaN 1.543750
2002 NaN 1.294000
2003 11.305000 1.258000
2004 3.931667 1.463600
2005 4.467778 1.569167
2006 10.853636 2.124925
2007 6.825000 2.514286
# -----------
Python - Gráficos
Gráficos de Barras entre duas variáveis categóricas e uma numérica
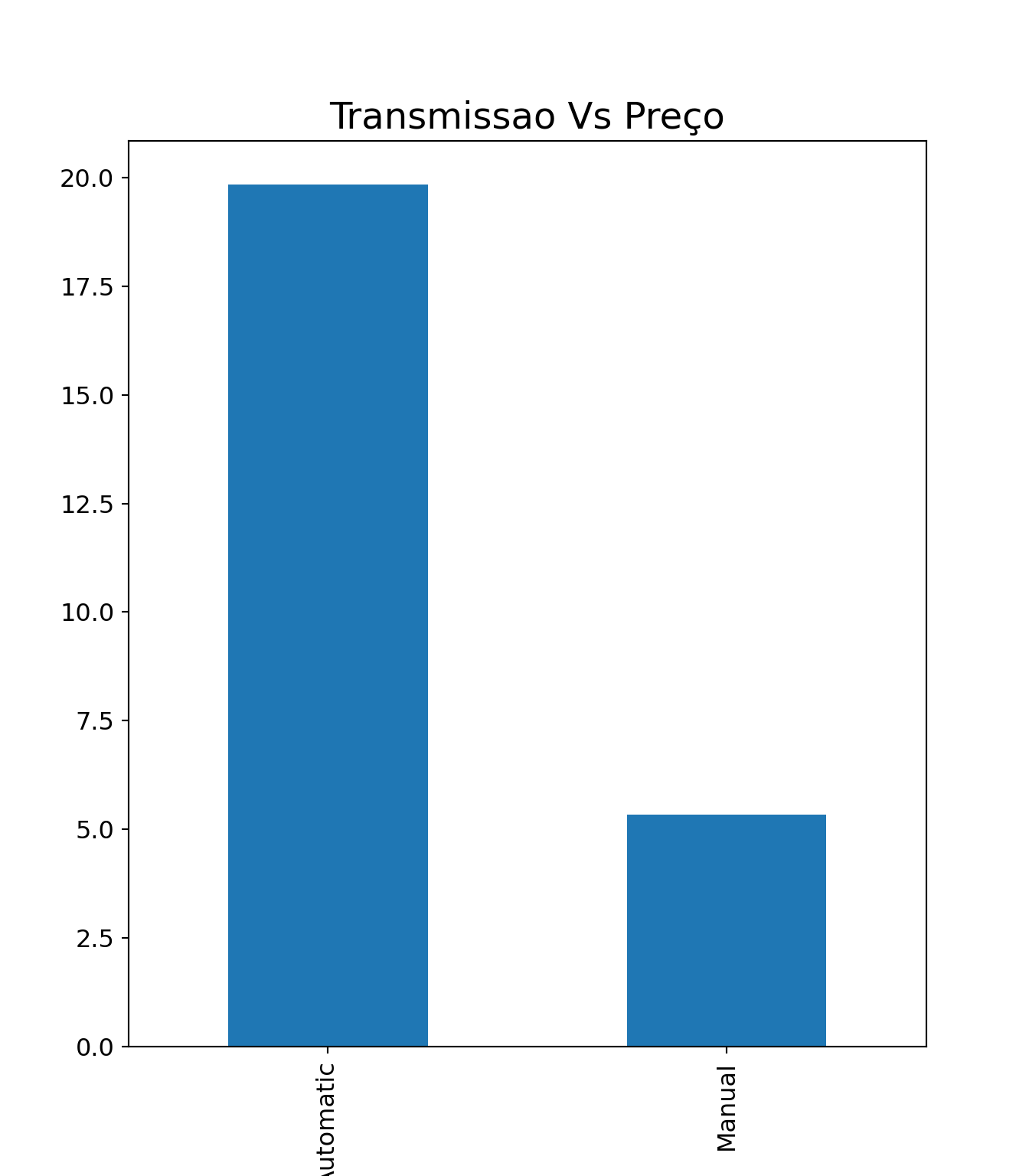
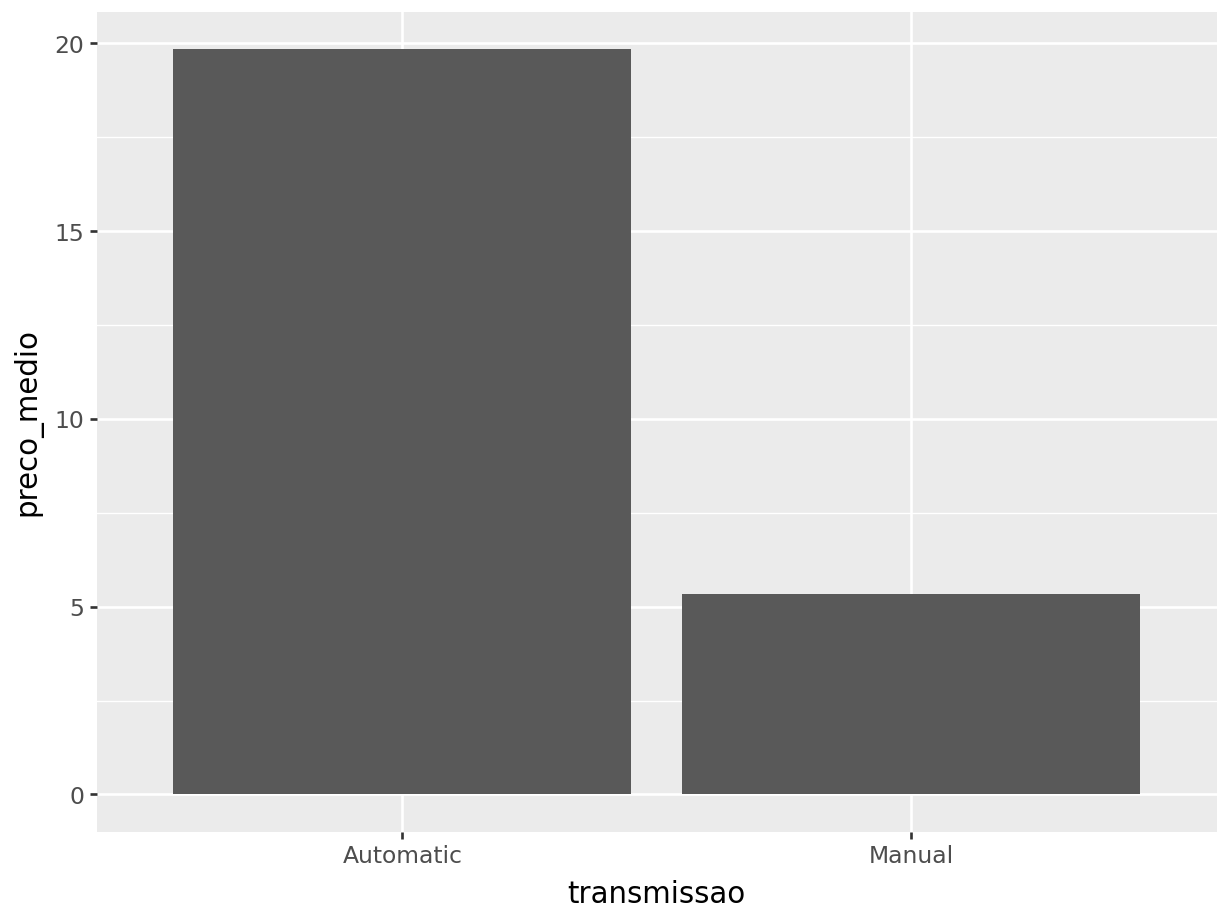
dfp.plot.barh(fontsize=10, rot =0) \ .set_title("Transmissao Vs Preço", fontsize=18)
O que podemos concluir de forma breve até esse momento com o estudo:
Existem uma frequência maior de carros manuais;
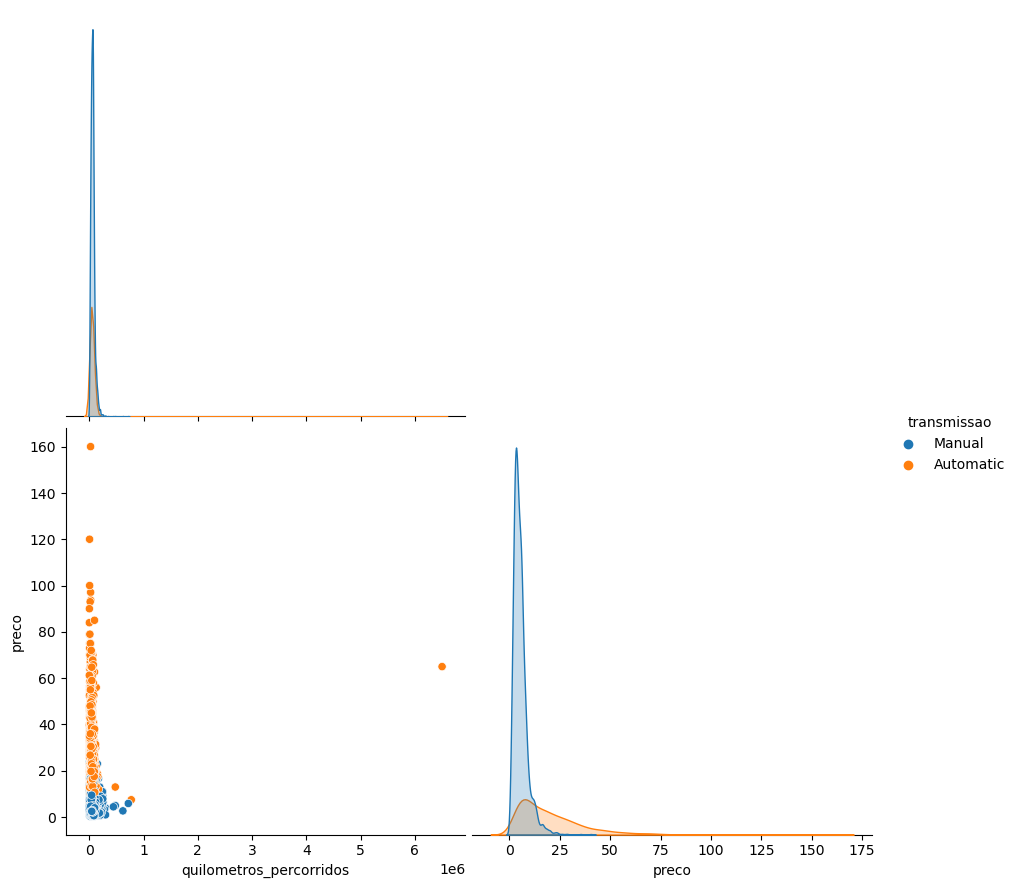
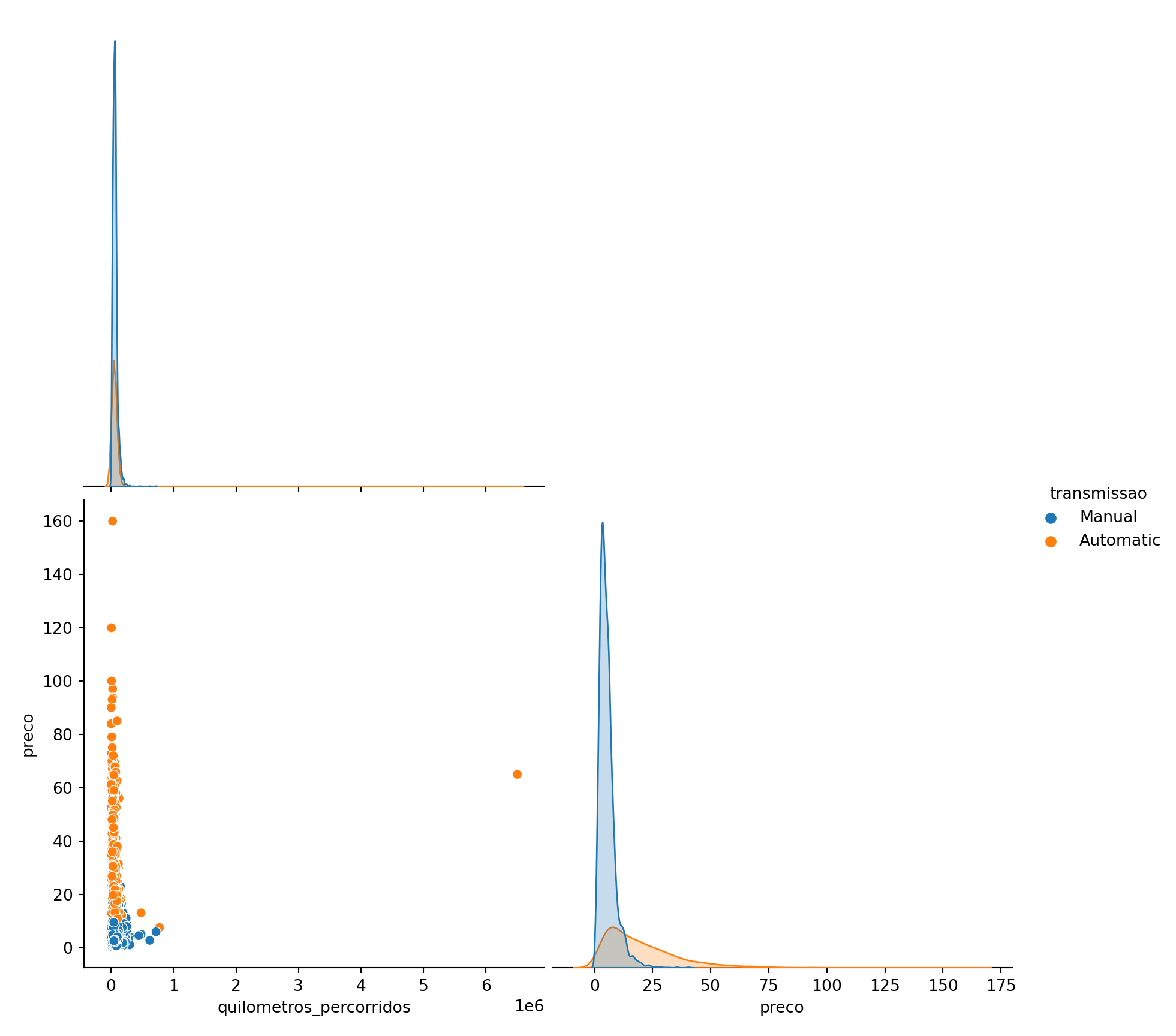
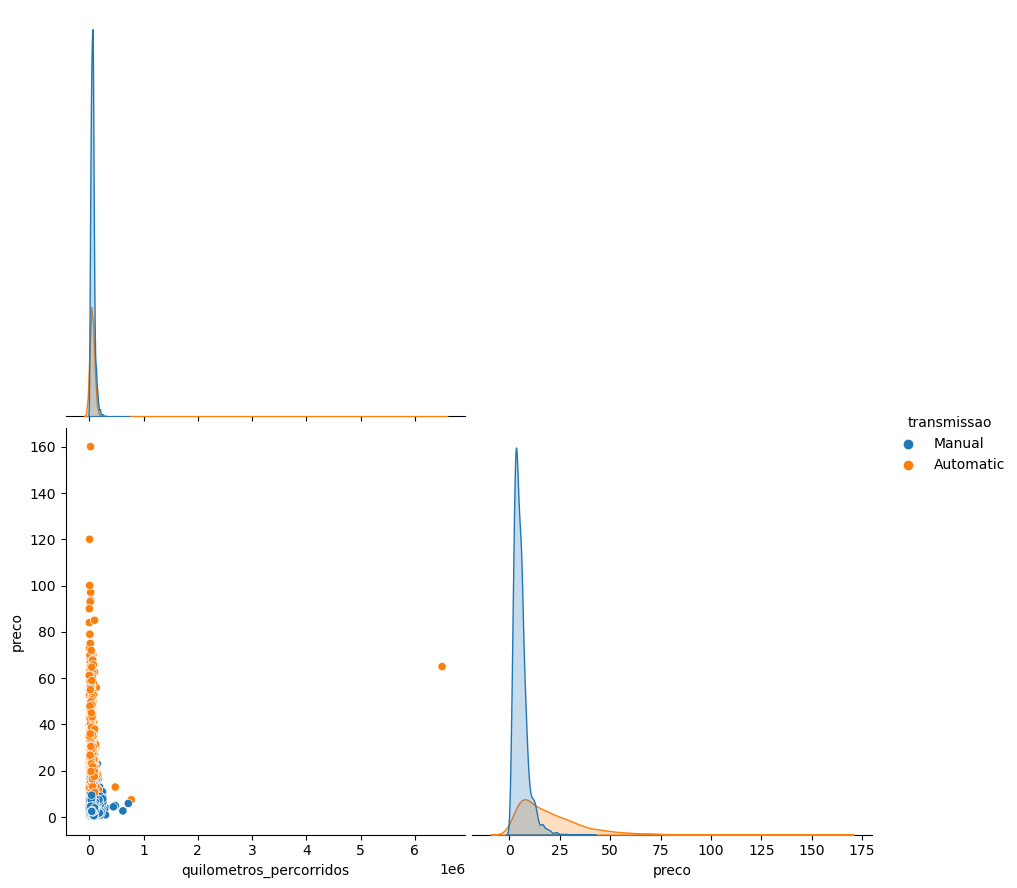
Os carros de transmissão automáticos são mais caros que os carros manuais;
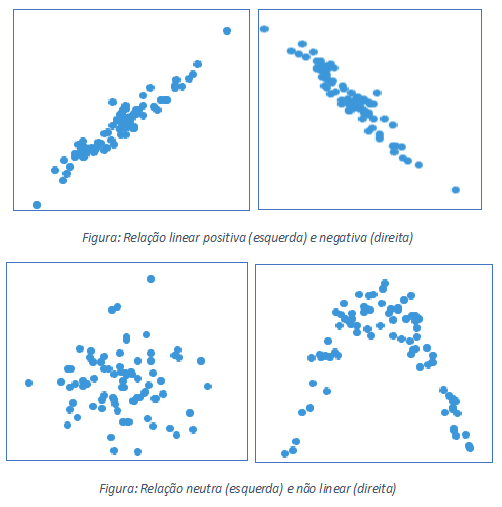
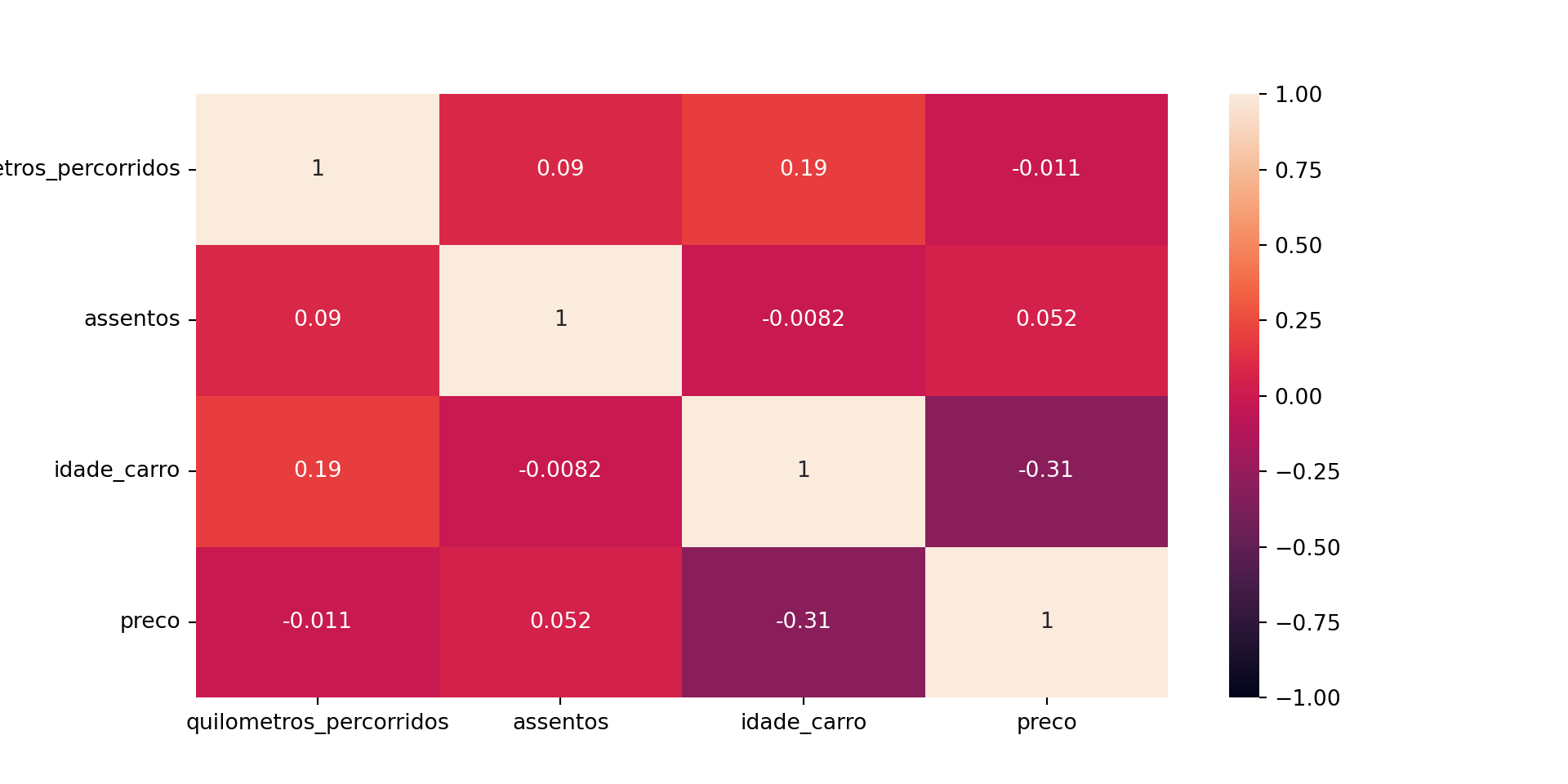
Existe uma correlação fraca/moderada negativa, entre o ano dos carros e os preços, ou seja, quanto maior a idade do carro, mais barato ele é.
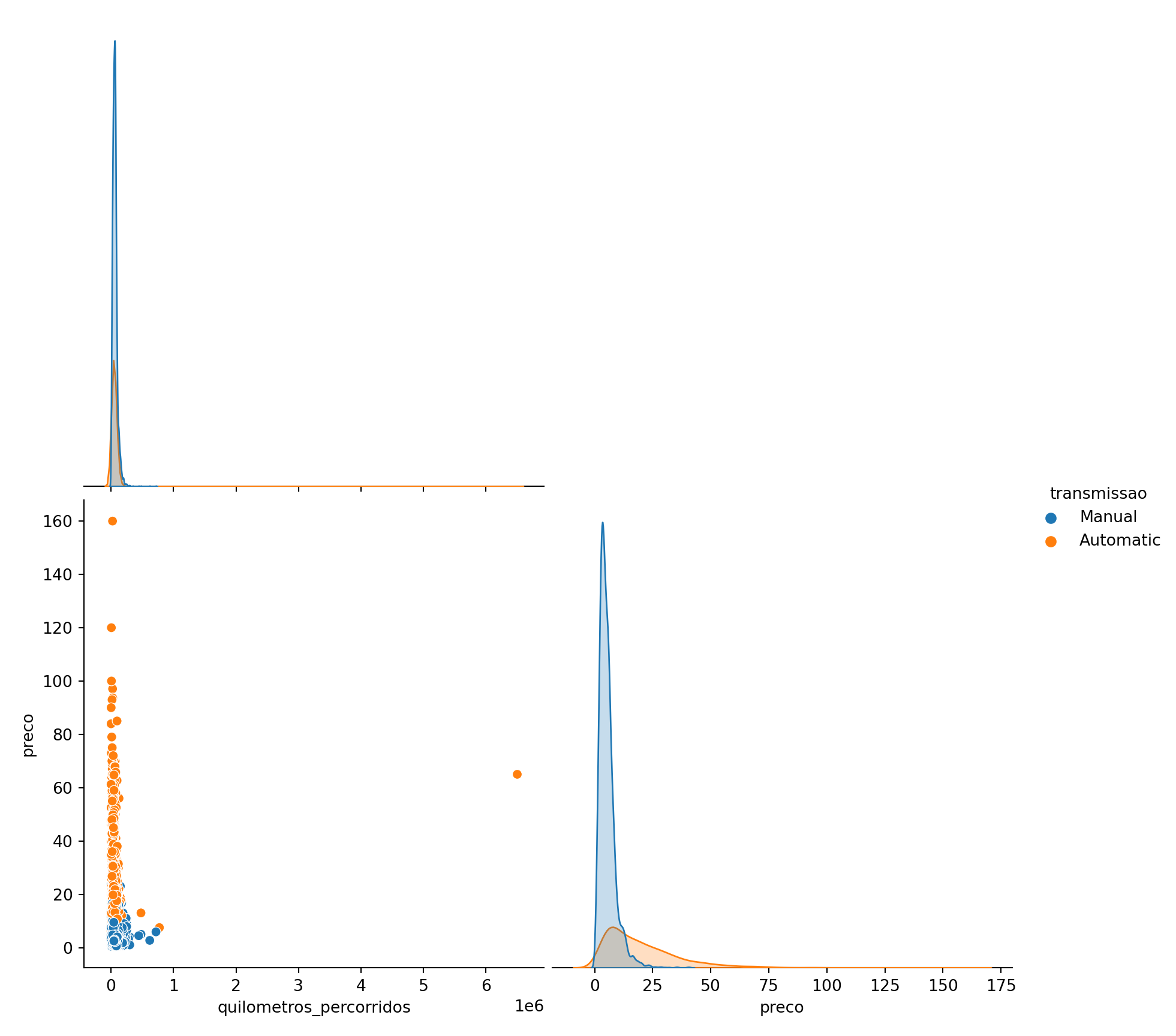
Existe uma correlação fraca entre idade do carro e quilometragem percorrida, ou seja, quanto mais antigo for o carro, mais quilometragem provavelmente percorreu.
.png)