Tópicos Especiais em Estatística Comp.
Conceitos de Big Data e Spark
UFPE
Big Data
- Estamos em um período de transformação no modo em que dirigimos nossos negócios e, principalmente, as nossas vidas.
- Neste exato momento, uma verdadeira enxurrada de dados, ou 2.5 quintilhões de bytes por dia, são gerados e estes dados estão sendo utilizados para nortear indivíduos, empresas e governos, e está dobrando a cada dois anos.
- Toda vez que fazemos uma compra, uma ligação ou interagimos nas redes sociais, estamos produzindo esses dados.
- E com a recente conectividade em objetos, tal como relógios, carros e até geladeiras, as informações capturadas se tornam massivas e podem ser cruzadas para criar roadmaps cada vez mais elaborados, apontando e, até prevendo, o comportamento de empresas e clientes.
Big Data
Big Data
Mas afinal, o que é Big Data?
Big Data é uma coleção de conjuntos de dados, grandes e complexos, que não podem ser processados por bancos de dados ou aplicações de processamento tradicionais.
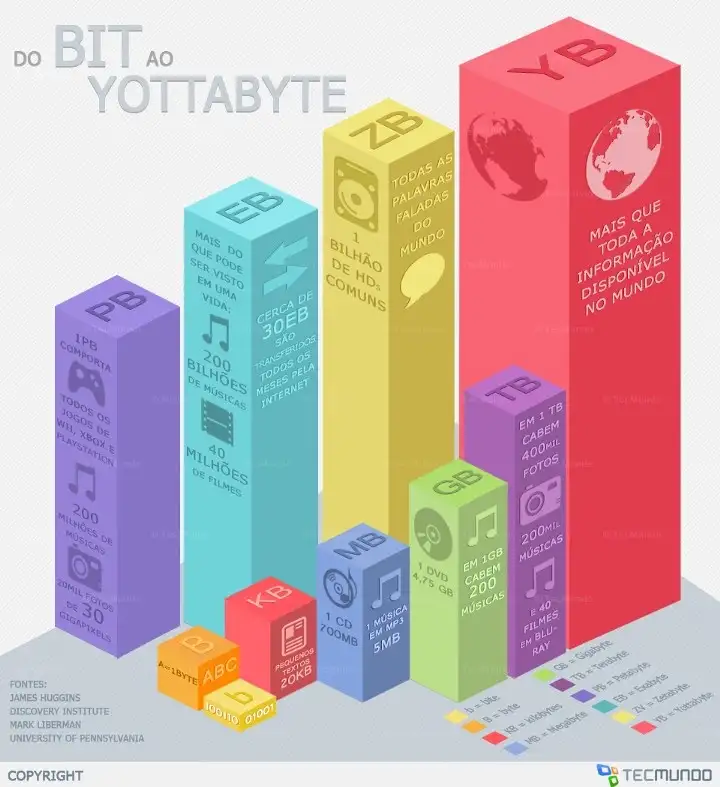
- O Google estima que a humanidade criou nos últimos 5 anos, o equivalente a 300 Exabytes de dados ou seja: 300.000.000.000.000.000.000 bytes de dados.
- Podemos definir o conceito de Big Data como sendo conjuntos de dados extremamente amplos e que, por este motivo, necessitam de ferramentas especialmente preparadas para lidar com grandes volumes, de forma que toda e qualquer informação nestes meios possa ser encontrada, analisada e aproveitada em tempo hábil.
Big Data
- Muitos dos dados gerados, possuem um tempo de vida curto e se não analisados, perdem a utilidade.
- Dados são transformados em informação, que precisa ser colocada em contexto para que possa fazer sentido.
- É caro integrar grandes volumes de dados não-estruturados, pois vai exigir muito poder computacional consequentemente máquinas mais poderosas e mais caras.
Big Data
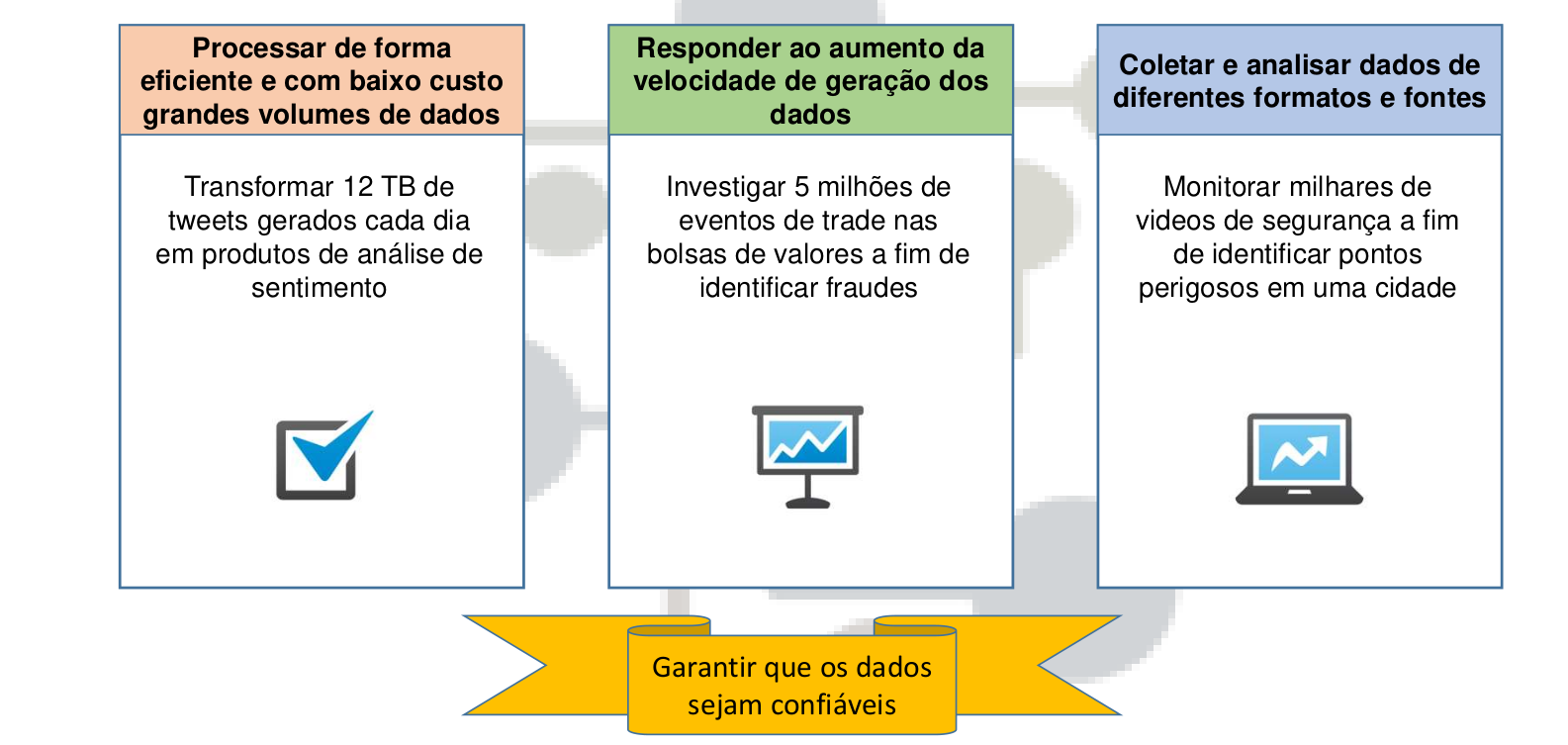
Trabalhar com Big Data exige alguns desafios:
- Encontrar profissionais habilitados em Big Data.
- Compreender as plataformas e ferramentas para Big Data.
- Coletar, armazenar e analisar dados de diferentes fontes, em diferentes formatos e gerados em diferentes velocidades.
- Migrar do sistema tradicional de coleta e armazenamento de dados, para uma estrutura de Big Data.
Big Data
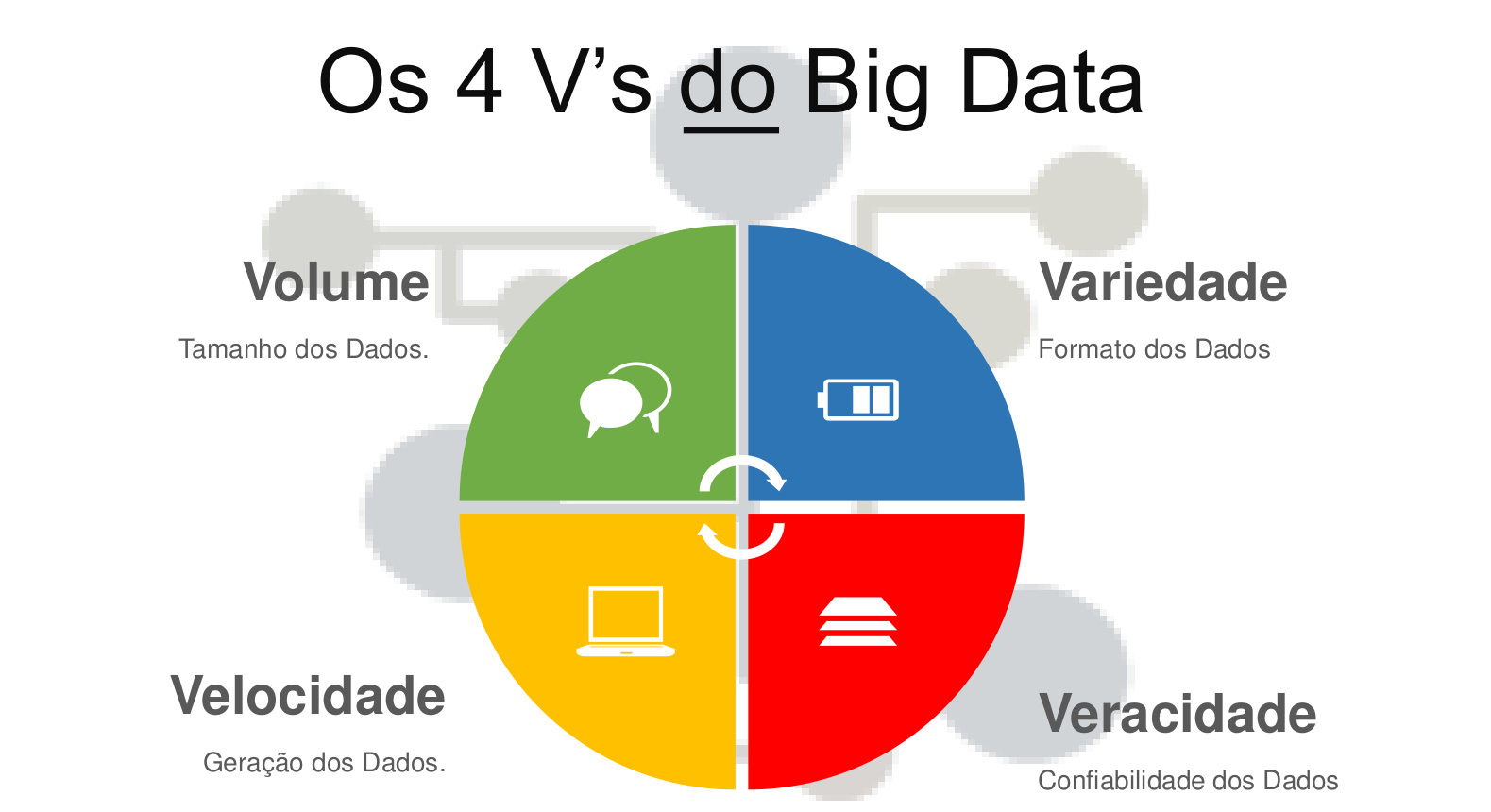
O Big Data são caracterizados por 4 V’s:
Big Data
Big Data
Volume
O volume refere-se à quantidade de dados que são gerados, armazenados e processados.
O volume de dados é um dos principais desafios do Big Data, pois os dados são gerados em uma velocidade muito alta e em grandes quantidades.
O volume de dados pode ser medido em terabytes, petabytes, exabytes, zettabytes e yottabytes.
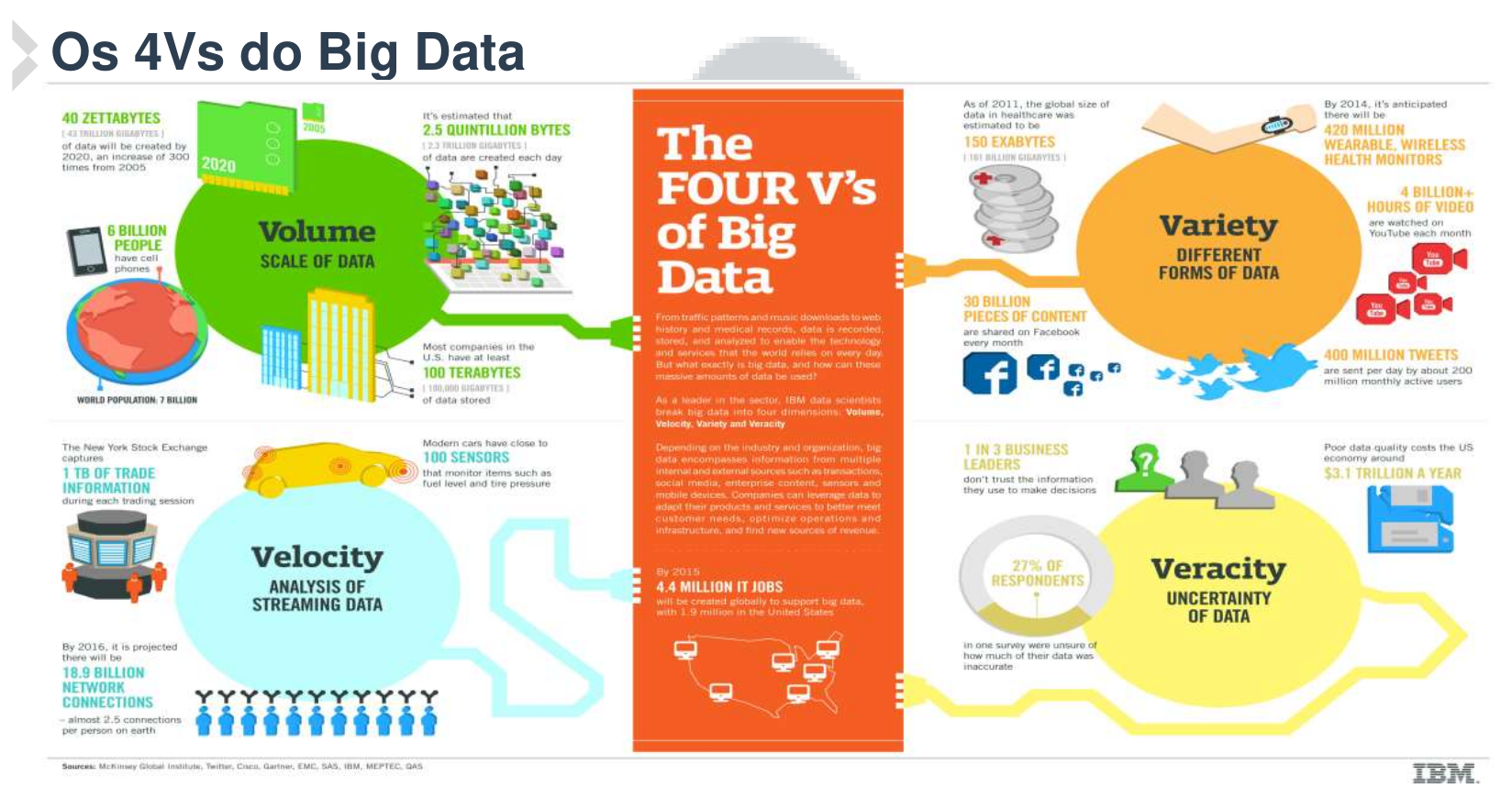
Estima-se que cada empresa americana armazena cerca de 100 Terabytes de dados por dia.
E que existem atualmente, aproximadamente cerca de 6 bilhões de telefones móveis no planeta gerando dados constatemente.
Big Data
Variedade
A variedade refere-se aos diferentes tipos de dados que são gerados, armazenados e processados. Como os dados estruturados são dados que são organizados em tabelas e são fáceis de serem processados e os dados não-estruturados são dados que não possuem uma estrutura definida e são difíceis de serem processados.
Os dados podem ser gerados a partir de diferentes fontes, como sensores, redes sociais, dispositivos móveis, etc.
150 exabytes é a estimativa de dados que foram gerados especificamente para tratamento de casos de doença em todo o mundo no ano de 2011;
Mais de 4 bilhões de horas por mês são usadas para assistir vídeos no YouTube;
30 bilhões de imagens são publicadas por mês no Instagram;
Big Data
Velocidade
A velocidade refere-se à rapidez com que os dados são gerados, armazenados e processados.
A velocidade é um dos principais desafios do Big Data, pois os dados são gerados em uma velocidade muito alta e em tempo real.
A velocidade dos dados pode ser medida em tempo real, em segundos, minutos, horas, dias, semanas, meses e anos.
1 terabyte de informação é criada durante uma única sessão da bolsa de valores Americana, a New Yor Stock Exchange (NYSE);
Aproximadamente 100 sensores estão instalados nos carros modernos para monitorar nível de combustível, pressão dos pneus e muitos outros aspectos do veículo;
Big Data
Veracidade
A veracidade refere-se à qualidade dos dados que são gerados, armazenados e processados.
A veracidade é um dos principais desafios do Big Data, pois os dados podem ser imprecisos, incompletos, inconsistentes, incorretos, etc.
Estima-se que, 1 em cada 3 empresas acredita que os dados que possuem são imprecisos, incompletos, inconsistentes ou incorretos, e assim, tais gestores tem experimentado problemas relacionados a veracidade dos dados para tomar decisões de negócios.
Além disso, estima-se que 3.1 trilhões de dólares por ano sejam desperdiçados devido a problemas de qualidade dos dados
Big Data
Apache Spark

O Apache Spark é um framework de computação distribuída de código aberto, que fornece uma interface de programação unificada para processamento de dados em larga escala.
O Spark foi desenvolvido para ser rápido, fácil de usar e oferecer suporte a uma ampla variedade de aplicativos de processamento de dados de forma eficiente e escalável.
O Spark é amplamente utilizado em empresas de tecnologia, finanças, saúde, varejo e outras indústrias para processar grandes volumes de dados e executar análises em tempo real.
Pode ser usado com linguagens Python, R, Scala e Java
Apache Spark
O Apache Spark oferece basicamente 3 principais benefícios:
Facilidade de uso – é possível desenvolver API’s de alto nível em Java, Scala, Python e R, que permitem focar apenas no conteúdo a ser computado, sem se preocupar com configurações de baixo nível e extremamente técnicas.
Velocidade – Spark é veloz, permitindo uso iterativo e processamento rápido de algoritmos complexos. Velocidade é uma característica especialmente importante no processamento de grandes conjuntos de dados e pode fazer a diferença entre analisar os dados de forma interativa ou ficar aguardando vários minutos pelo fim de cada processamento. Com Spark, o processamento é feito em memória.
Uso geral – Spark permite a utilização de diferentes tipos de computação, como processamento de linguagem SQL (SQL Spark), processamento de texto, Machine Learning (MLlib) e processamento de grafos (GraphX). Estas características fazem do Spark uma excelente opção para projetos de Big Data.
Apache Spark
Parquet
O Apache Parquet é um formato de arquivo de código aberto para armazenar dados em colunas.
Ele é projetado para ser eficiente em termos de espaço e velocidade de leitura/escrita.
O Parquet é especialmente útil para consultas analíticas em que você normalmente lê apenas algumas colunas de um grande conjunto de dados.
O Parquet é amplamente utilizado em sistemas de Big Data, como o Apache Hadoop e o Apache Spark.
Ele armazena grande volume de dados em disco, de forma compacta e eficiente, e permite a leitura de dados de forma rápida e eficiente.
Apache Spark
Vamos usar o Spark no python e R!
OBRIGADO!
Slide produzido com quarto
Tópicos Especiais em Estatística Computacional - Prof. Jodavid Ferreira