Introdução ao R aplicado ao Geoprocessamento
UFPE
Estrutua do Minicurso
- Introdução ao GeoProcessamento
- Conceitos de Sistemas de Informação Geográfica
- Por que escolher o R?
- Introdução a linguagem de programação R
- Criando mapas com R
Geoprocessamento
Geoprocessamento é a área da ciência que utiliza um conjunto de métodos e tecnologias para coletar, armazenar, processar, analisar dados espaciais sobre o mundo real (Burrough, 1986).
Nosso foco será nos SIGs (Sistemas de Informação Geográfica), que são tecnologias do Geoprocessamento, em que é possível:
- representar em ambientes computacionais os fenômenos geográficos, tais como, a distribuição espacial de dados e informações, realização e visualização de análises espaciais, entre outros.
Sistemas de Informação Geográfica
Os Sistemas de Informação Geográfica englobam tecnologias como:
- Sensoriamento Remoto;
- Digitalização de Dados;
- Sistemas de Posicionamento Global - GPS;
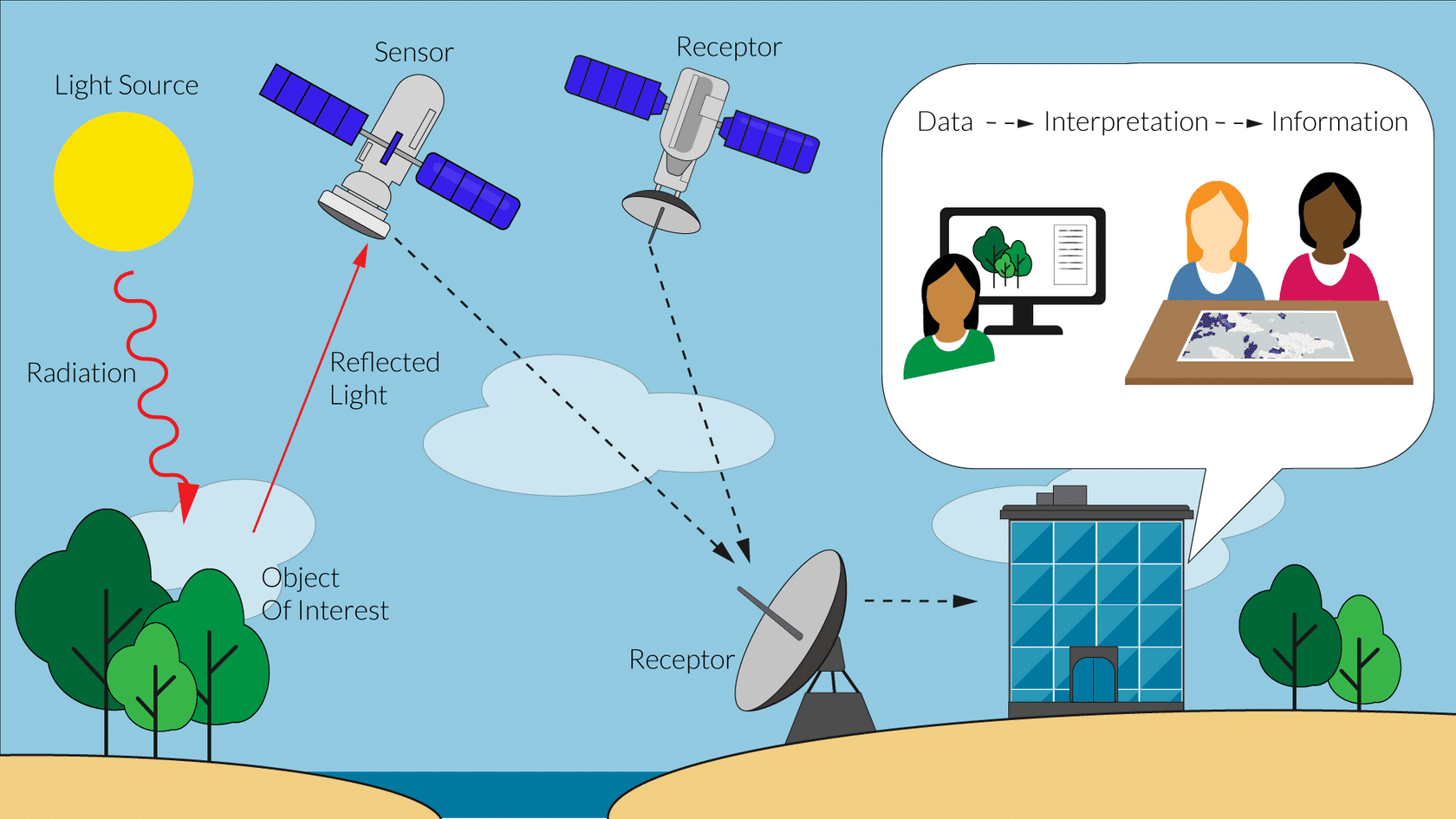
Sistemas de Informação Geográfica
A primeira utilização de um SIG foi em Londres - Inglaterra, no ano de 1854, quando uma epidemia de cólera assolava a cidade e ninguém sabia o motivo para tal. Então o médico John Snow decidiu pegar um mapa do local, e localizar os poços de águas (principal fonte de água dos habitantes) e os locais de moradias do doentes, e ele visualizou uma forte correlação espacial entre as pessoas que doentes e o poço de água da Broad Street.

Sistemas de Informação Geográfica
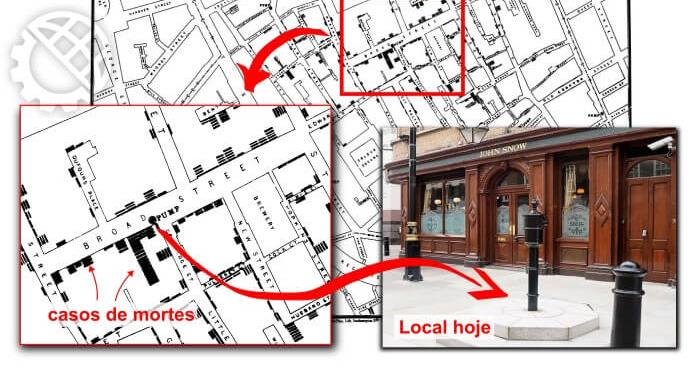
Sistemas de Informação Geográfica
Alguns conceitos importantes sobre o SIG são:
- Espaço Geográfico;
- Dados Espaciais (Informação Espacial);
- Banco de dados Geográficos;
Sistemas de Informação Geográfica
Espaço Geográfico
É a coleção de localizações na superfície da Terra onde ocorrem os fenômenos geográficos. O espaço geográfico se define em relação a suas coordenadas, sua altitude e sua posição relativa. Vale relembrar que os dados geográficos não estão sozinhos no espaço, ou seja, possuem relação com outros dados.
O espaço geográfico é composto por entidades distintas (diferentes) e identificáveis, estes são definidos como geo-campos e os geo-objetos;
Sistemas de Informação Geográfica
Espaço Geográfico
Os geo-campos possuem uma distribuição espacial de uma variável com valores em todos os pontos pertencentes a uma região do Espaço Geográfico.
- exemplos: tipo de solo, floresta aberta.
Os geo-objetos são dados que possuem localizações e identificação que compõem uma determinada região, do espaço geográfico.
- exemplos:: hospitais, igrejas, escolas, o IFPB, etc.
Sistemas de Informação Geográfica
Dados Espaciais (Informação Espacial)
São as informações obtidas de um espaço geográfico que depende da localização do geo-objeto (ou de pontos do geo-campo).
Os dados espaciais são compostos em duas partes (dois componentes distintos):
Parte Gráfica: responsável pela parte que representa o geo-objeto ou o geo-campo na visualização da região.
Parte não gráfica: responsável pela características, ou seja, os dados quantitativos e os qualitativos dos geo-campos ou geo-objetos que podem ser utilizados para fazer análises.
Sistemas de Informação Geográfica
Banco de dados Geográficos
No SIG os dados espaciais são armazenados em Banco de Dados, e esta organização varia de acordo com o tipo do software utilizado.
Geralmente os Bancos de dados do SIG são divididos em Projetos, cujo estes estão divididos em níveis, camadas ou Planos de Informação - PIs.
Os Planos de Informações (PIs) armazenam os dados geográficos de uma determinada região. Cada plano representa a mesma área, porém contendo informações geográficas diferentes. Por exemplo PIs de rodovias, classificação climática, etc. O cruzamento das informações existentes nesses PIs, formarão a cartografia básica, ou seja, mapa da integração desses dados como produto final.
Sistemas de Informação Geográfica
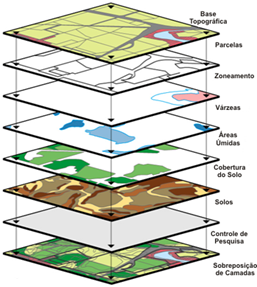
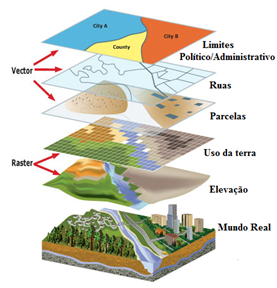
Sistemas de Informação Geográfica
Esses dados dos Planos de Informações, são incorporados em um SIG, advindos de diversas fontes, dentre as quais, podem-se destacar:
- os mapas em papel;
- mapas digitais;
- dados de campo;
- sensoriamento remoto (fotos aéreas, imagens de satélite);
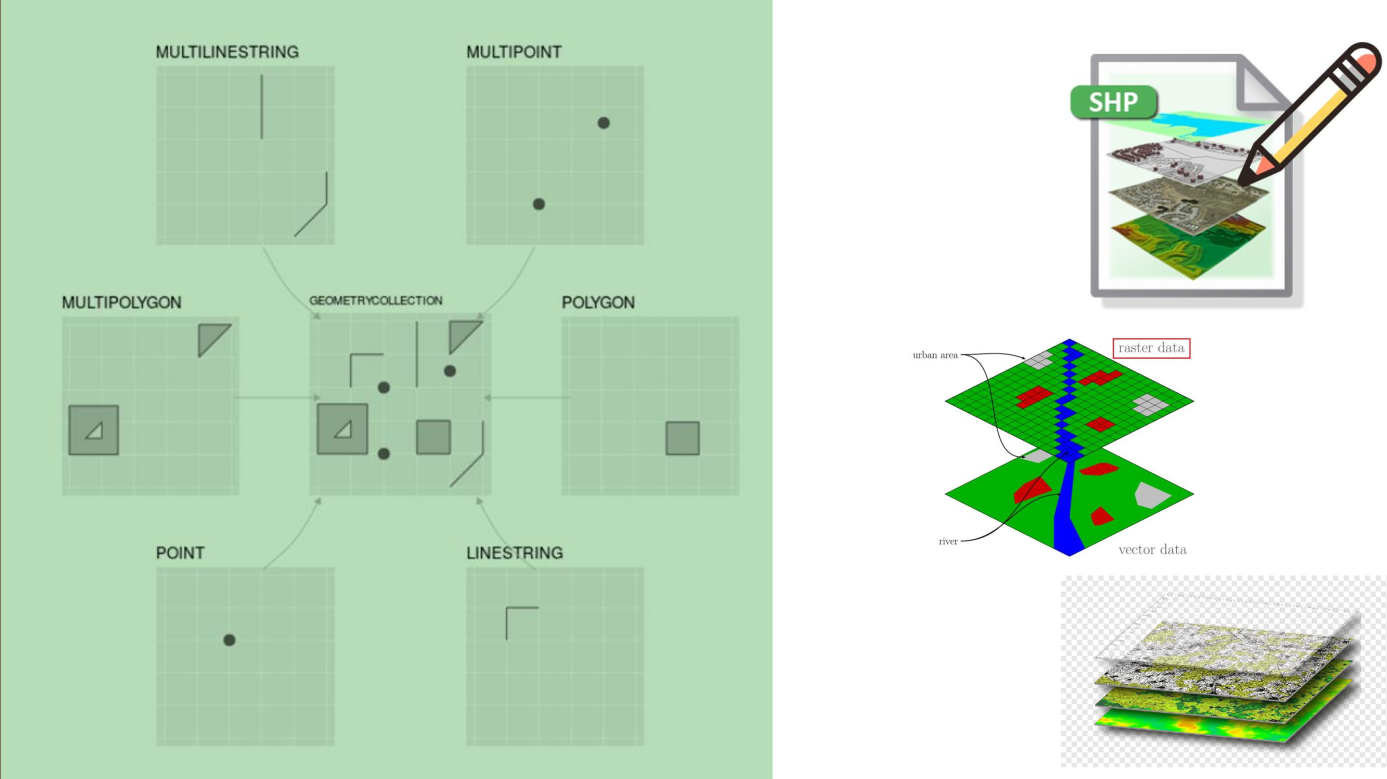
- arquivos shapefiles (vetoriais);
- raster (matricial);
Sistemas de Informação Geográfica
Esses dados dos Planos de Informações, são incorporados em um SIG, advindos de diversas fontes, dentre as quais, pode-se destacar:
- os mapas em papel;
- mapas digitais;
- dados de campo;
- sensoriamento remoto (fotos aéreas, imagens de satélite);
- arquivos shapefiles (vetoriais);
- raster (matricial);
Sistemas de Informação Geográfica
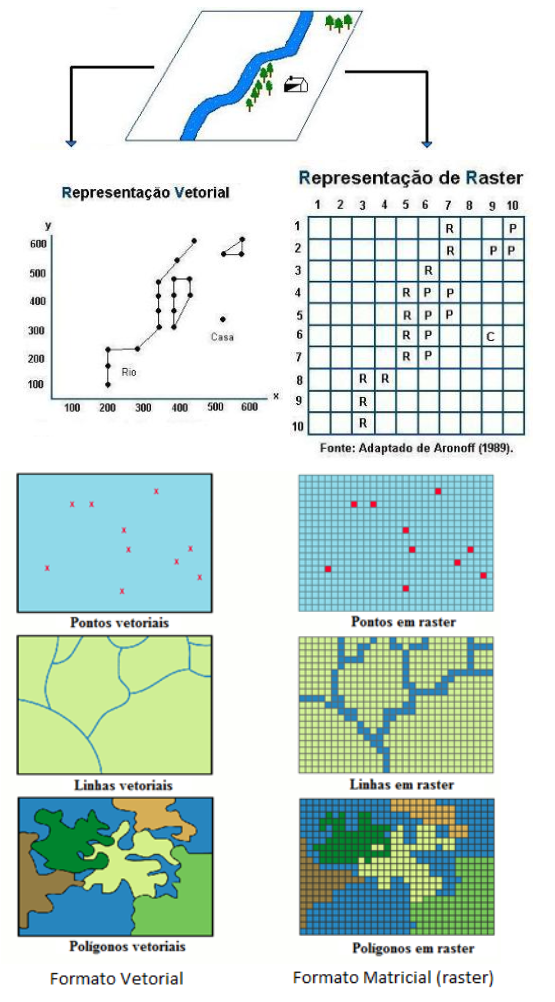
- Formato Vetorial - Conjunto de posições em x e y, que formam pontos, linhas e polígonos.
- Formato Matricial (Raster) - Conjunto de linhas e colunas (matriz), a cada célula da matriz está associado um valor.
Sistemas de Informação Geográfica
Software para Geoprocessamento

Por que a escolha do R?
O R é uma linguagem de programação inicialmente desenvolvida para computação estatística. É licenciada como Software Livre.
- Atualmente, é uma linguagem de programação muito utilizada em estatística e ciência de dados, e é uma das linguagens mais populares para análise de dados.
- É uma implementação de código aberto do S, que é uma linguagem de programação estatística desenvolvida pela AT&T Bell Laboratories.
- As vantagens do R para programação estatística são a facilidade de uso, a capacidade de criar gráficos de alta qualidade e a comunidade de usuários ativos.
Por que a escolha do R?
O R vai proporcionar a liberdade para fazer qualquer tipo de Análise Espacial.
Como assim? O que isso significa?
Vamos supor que temos os seguintes problemas:
- A polícia deseja investigar se existe algum padrão espacial na distribuição de roubos. Os roubos que ocorrem em determinadas áreas estão correlacionados com características sócio-econômicas dessas áreas?
- Quais os municípios do estado da Paraíba que possuem maiores taxas de casos de dengue dado sua população? Essas taxas são estatísticamente significativas?
Por que a escolha do R?
Em geral, trabalhamos com quatro tipos de dados:
- Dados Pontuais: é quando o objetivo é analisar dados de uma determinada área específica, e a localização exata é o fator de interesse de estudo. Ex.: pontos onde ocorreram casos de Tuberculose em uma cidade.
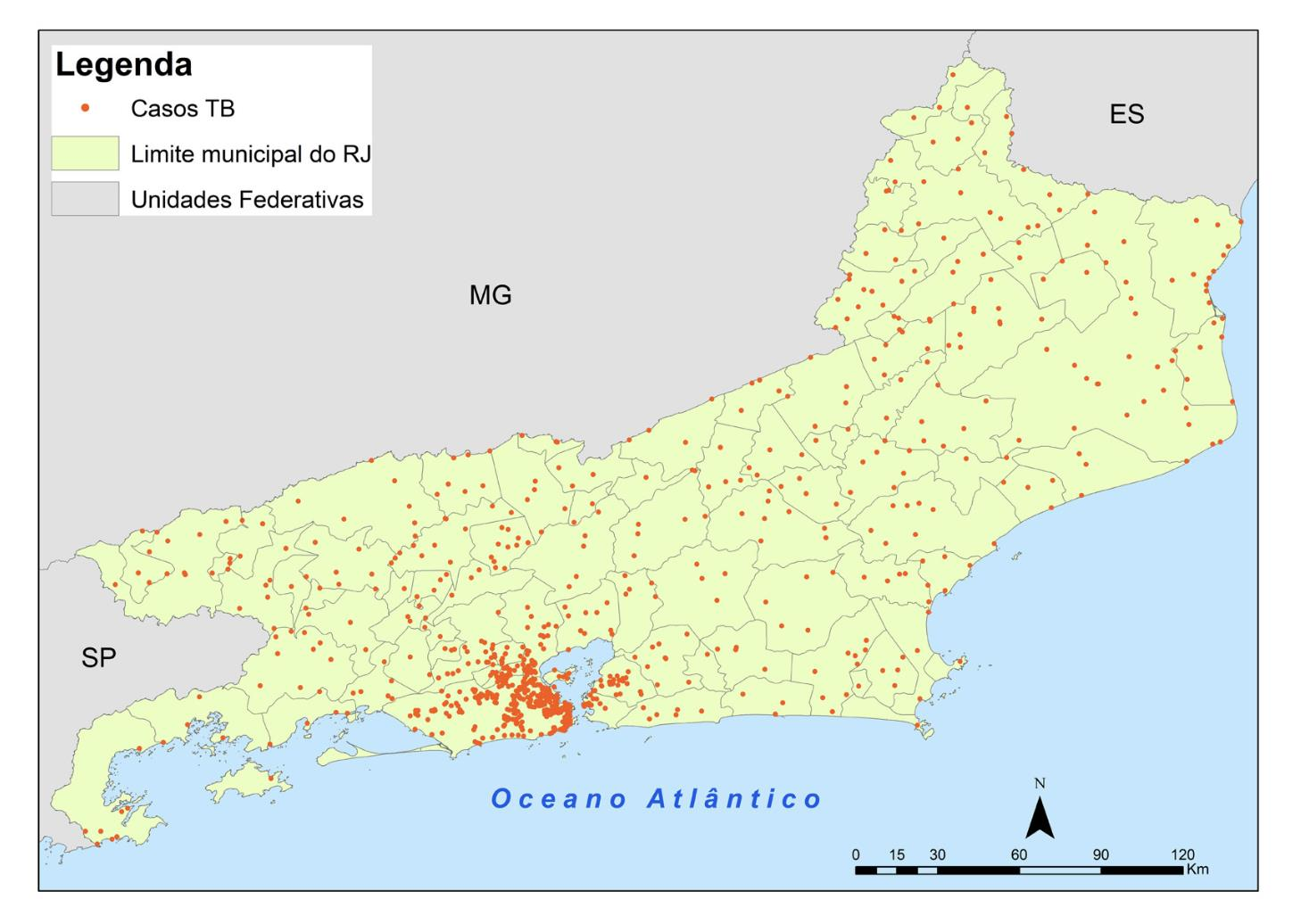
Por que a escolha do R?
Em geral, trabalhamos com quatro tipos de dados:
- Dados de Área: são dados obtidos e analisados de áreas geográficas, nesse caso não utiliza o ponto exato, mas uma determinada área geográfica. Ex.: Incidência de alguma epidemia por município, bairro.
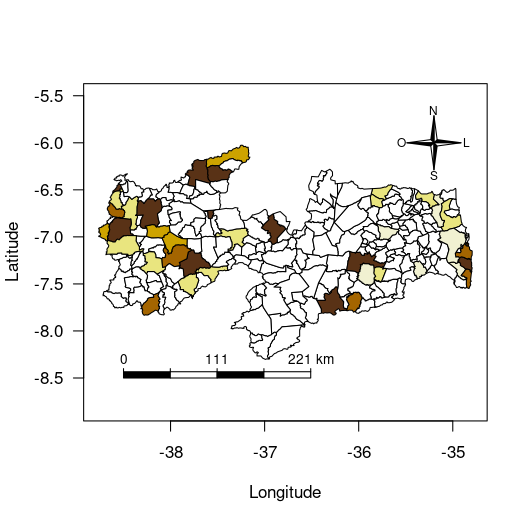
Por que a escolha do R?
Em geral, trabalhamos com quatro tipos de dados:
- Dados de Superfície: são dados obtido de levantamento de recursos naturais, nos quais, a sua natureza é a própria superfície do fenômeno estudado. Ex.: a distribuição da temperatura em um estado.
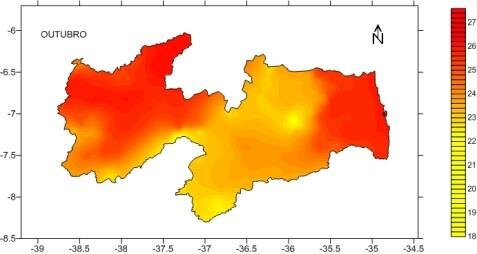
Por que a escolha do R?
Em geral, trabalhamos com quatro tipos de dados:
- Dados de Interação: são dados obtidos quando há fluxo de informações entre dois ou mais pontos com localizações geográficas fixas. Ex.: Fluxo migratório entre duas cidades.
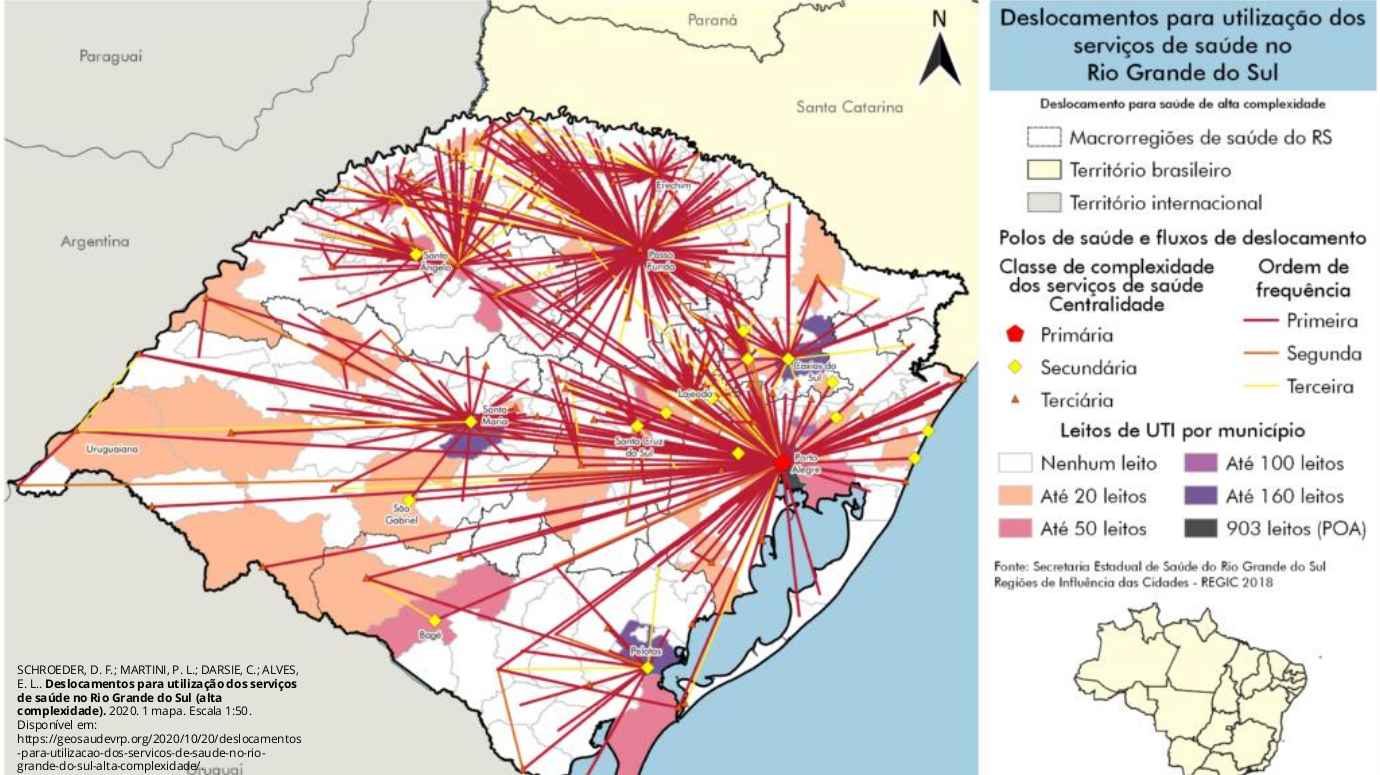
Por que a escolha do R?
Essa flexibilidade para desenvolver pesquisa e implementar novos métodos de análise espacial, é um dos pontos que torna o R uma ferramenta poderosa para o Geoprocessamento.
Linguagem R
Como dito anteriormente, o R é uma linguagem de programação de código aberto e licenciada como Software Livre.
- Um software ser licenciado como software livre, significa que você pode utilizá-lo para qualquer propósito, estudar seu código fonte, adaptá-lo para suas necessidades, redistribuir cópias do programa, melhorar o programa e distribuir suas melhorias para a comunidade.
Isso não é no nível de utilizar o R para fazer scripts, mas você pode ir a um nível mais profundo, ou seja, você pode pegar o R, fazer uma nova linguagem de programação baseada nele e distribuir para a comunidade, sem ter que pagar nada por isso, entretanto, vai precisar respeitar a licença do R, esta deve ser a mesma na sua modificação.
Linguagem R
Para obter o R, acesse o link: https://cloud.r-project.org/
O CRAN (Comprehensive R Archive Network) é um conjunto de servidores-espelho distribuídos pelo mundo e é utilizado para distribuir o R e os pacotes do R.
Uma nova grande versão do R é lançada uma vez por ano, e há dois ou três pequenos lançamentos por ano.
É interessante manter o R sempre atualizado, pois as novas versões do R trazem melhorias de desempenho em relação aos hardware mais recentes, novas funcionalidades e correções de bugs. tware para o R.
No momento da criação desse minicuroso, o R encontrava-se na versão 4.4.2 lançada em 31.10.2024.
Linguagem R
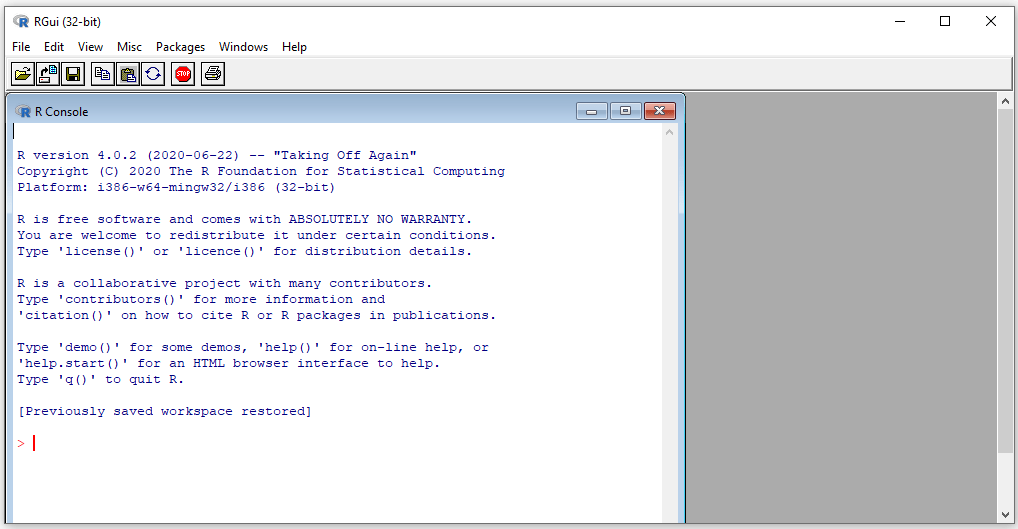
IDE padrão do R no Windows, é instalada juntamente com a linguagem no sistema.
Linguagem R
O uso R no Linux é através do terminal do sistema.
Linguagem R
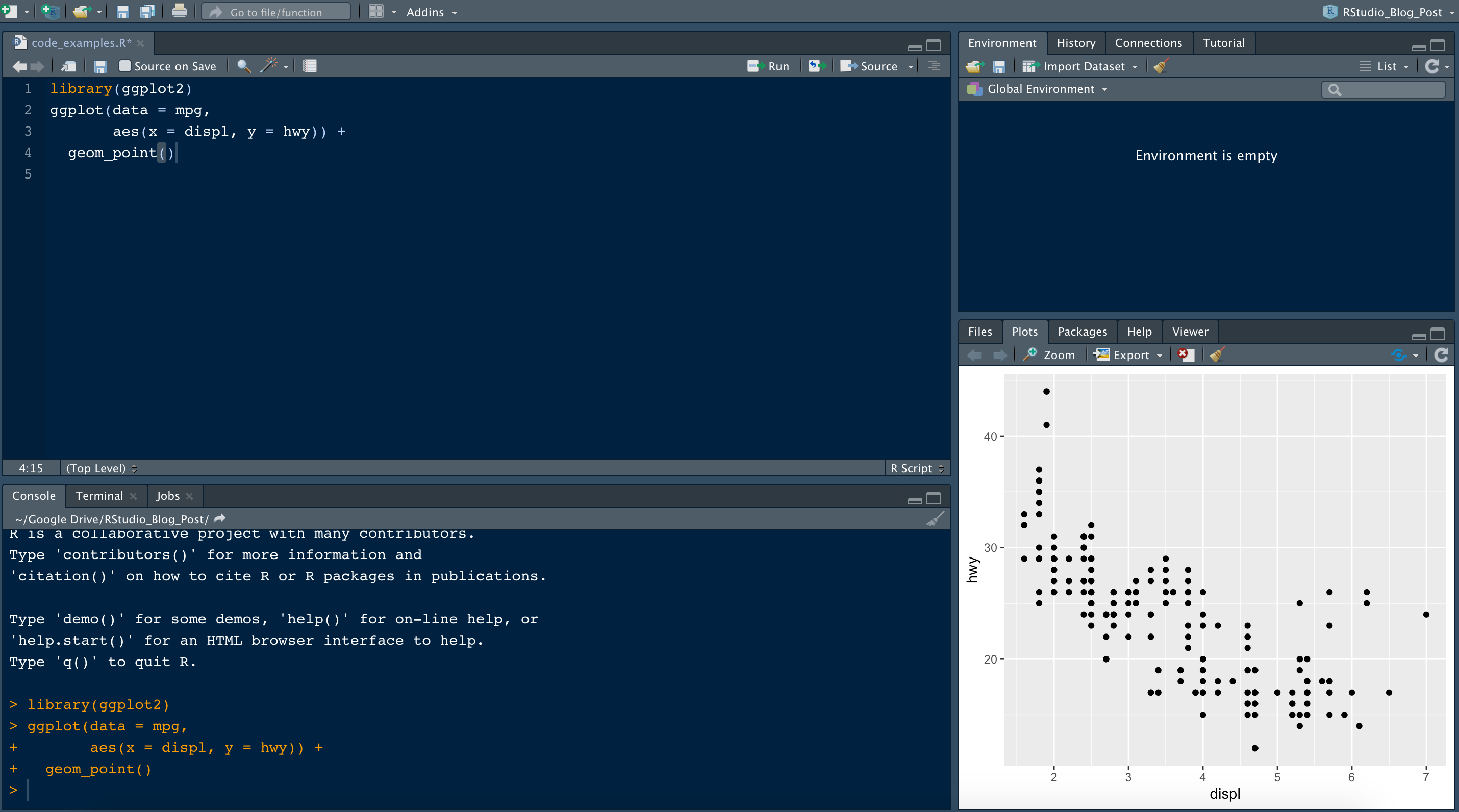
Pacotes
Um conceito importante no R são os pacotes.
Um pacote no R é uma colação de funções, dados e documentação que estende as capacidades do R base.
- O R base é o conjunto de funções que estão disponíveis quando você instala o R.
Existem milhares de pacotes disponíveis no CRAN, que foram disponibilizados por desenvolvedores de todo o mundo.
Para instalar um pacote no R, é da seguinte forma:
- Se não aparecer nenhum erro no console, tudo indica que o pacote foi instalado corretamente.
Pacotes
- Para carregar um pacote no R, utilizamos uma das seguintes funções:
ou
e as funções do pacote podem ser usadas de duas formas:
Pacotes
ou
# Exemplo de utilização de função de pacote
datasets::iris |>
dplyr::filter(Species == "setosa") |>
utils::head() Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosarelembrando a estrutura anterior novamente…
Operações Básicas
- O R é uma linguagem de programação que suporta operações aritméticas básicas, como adição, subtração, multiplicação e divisão.
Criação de Objetos
- No R, é possível criar objetos para armazenar valores, e esses objetos podem ser de diferentes tipos, como números, strings, vetores, matrizes, data frames, entre outros.
Utilização de Funções
- O R possui uma série de funções embutidas que podem ser utilizadas para realizar operações matemáticas, estatísticas, de manipulação de dados, entre outras. Estas funções são utilizadas da seguinte forma:
vetores, arrays, listas e matrizes
- No R, é possível criar vetores, arrays e listas, que são estruturas de dados que podem armazenar múltiplos valores.
- Um vetor é uma sequência de valores de um único tipo, e é criado utilizando a função
c().
vetores, arrays, listas e matrizes
- Uma lista é uma estrutura de dados que pode armazenar múltiplos valores de diferentes tipos, e é criado utilizando a função
list().
[[1]]
[1] 1
[[2]]
[1] "a"
[[3]]
[1] TRUEvetores, arrays, listas e matrizes
- Para acessar os elementos de estruturas como um vetor, array, lista ou matriz, utilizamos colchetes
[].
Vale uma observação, de que os índices em R começam em 1, e não em 0, como em algumas outras linguagens de programação.
pacote dplyr
Manipulação de dados com dplyr
- O pacote
dplyré um pacote do R que fornece uma gramática para manipulação de dados, e é muito útil para transformar, filtrar e resumir dados.
- O
dplyrfornece um conjunto de funções que são fáceis de usar e que permitem realizar operações comuns de manipulação de dados de forma eficiente, dessa forma, para essa parte inicial de tratamento de dados, vamos focar na utilização desse pacote.
- Vamos tentar sempre utilizar as funções da seguinte forma
pacote::funcao()para evitar conflitos de funções com o mesmo nome em diferentes pacotes.
Manipulação de dados com dplyr
- Vamos selecionar uma base de dados para utilizar as funções do
dplyr:
# A tibble: 13 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
11 2013 1 1 558 600 -2 849 851
12 2013 1 1 558 600 -2 853 856
13 2013 1 1 558 600 -2 924 917
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>Manipulação de dados com dplyr
Conseguimos fazer filtragem de dados utilizando a função filter()
# A tibble: 13 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 11 1 5 2359 6 352 345
2 2013 11 1 35 2250 105 123 2356
3 2013 11 1 455 500 -5 641 651
4 2013 11 1 539 545 -6 856 827
5 2013 11 1 542 545 -3 831 855
6 2013 11 1 549 600 -11 912 923
7 2013 11 1 550 600 -10 705 659
8 2013 11 1 554 600 -6 659 701
9 2013 11 1 554 600 -6 826 827
10 2013 11 1 554 600 -6 749 751
11 2013 11 1 555 600 -5 847 854
12 2013 11 1 555 600 -5 839 846
13 2013 11 1 555 600 -5 929 943
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>Manipulação de dados com dplyr
Para usar filtragens de forma eficaz, você precisa saber como utilizar operadores de comparação e operadores lógicos.
Alguns operadores são:
- Operadores de comparação:
==igual a!=diferente de>maior que<menor que
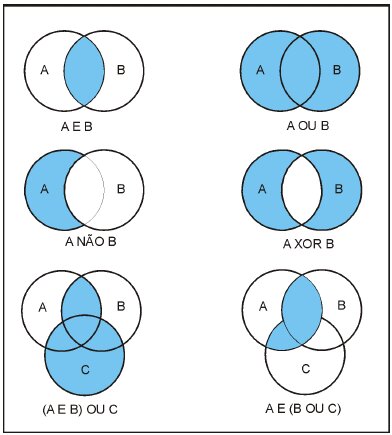
- Operadores lógicos:
&e|ou!não
Manipulação de dados com dplyr
- Neste caso, podemos utilizar
# A tibble: 5 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 11 1 5 2359 6 352 345
2 2013 11 1 35 2250 105 123 2356
3 2013 11 1 455 500 -5 641 651
4 2013 11 1 539 545 -6 856 827
5 2013 11 1 542 545 -3 831 855
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm># A tibble: 5 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 11 1 5 2359 6 352 345
2 2013 11 1 35 2250 105 123 2356
3 2013 11 1 455 500 -5 641 651
4 2013 11 1 539 545 -6 856 827
5 2013 11 1 542 545 -3 831 855
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>Manipulação de dados com dplyr
- Um problema que pode surgir para complicar as comparações, são os valores faltantes.
- Os NAs (“not available”, em português, “não disponível”) são valores que não existem na base de dados.
- Qualquer operação envolvendo um valor desconhecido, também será desconhecida.
Manipulação de dados com dplyr
- A função
filter()só considera as linhas em que a condição é verdadeira (TRUE), e descarta as linhas em que a condição é falsa (FALSE) ouNA. Se deseja preservar os valores faltantes, peça eles explicitamente:
# A tibble: 10 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 NA 1630 NA NA 1815
2 2013 1 1 NA 1935 NA NA 2240
3 2013 1 1 NA 1500 NA NA 1825
4 2013 1 1 NA 600 NA NA 901
5 2013 1 2 NA 1540 NA NA 1747
6 2013 1 2 NA 1620 NA NA 1746
7 2013 1 2 NA 1355 NA NA 1459
8 2013 1 2 NA 1420 NA NA 1644
9 2013 1 2 NA 1321 NA NA 1536
10 2013 1 2 NA 1545 NA NA 1910
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>Manipulação de dados com dplyr
- Outra função interessante é a
arraange(), que serve para ordenar os dados. - Ele funciona semelhante ao
filter(), mas ao invés de filtrar, ele ordena.
# A tibble: 10 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 10 30 2400 2359 1 327 337
2 2013 11 27 2400 2359 1 515 445
3 2013 12 5 2400 2359 1 427 440
4 2013 12 9 2400 2359 1 432 440
5 2013 12 9 2400 2250 70 59 2356
6 2013 12 13 2400 2359 1 432 440
7 2013 12 19 2400 2359 1 434 440
8 2013 12 29 2400 1700 420 302 2025
9 2013 2 7 2400 2359 1 432 436
10 2013 2 7 2400 2359 1 443 444
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>Manipulação de dados com dplyr
- é possível ordenar por mais de uma coluna, basta passar mais argumentos para a função
arrange().
# A tibble: 10 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>- Se deseja ordenar em forma decrescente, basta utilizar a função
desc().
Manipulação de dados com dplyr
- A função
select()é utilizada para selecionar colunas de um data frame.
Manipulação de dados com dplyr
- É possível excluir colunas também utilizando o
select().
# A tibble: 15 × 16
dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay carrier
<int> <int> <dbl> <int> <int> <dbl> <chr>
1 517 515 2 830 819 11 UA
2 533 529 4 850 830 20 UA
3 542 540 2 923 850 33 AA
4 544 545 -1 1004 1022 -18 B6
5 554 600 -6 812 837 -25 DL
6 554 558 -4 740 728 12 UA
7 555 600 -5 913 854 19 B6
8 557 600 -3 709 723 -14 EV
9 557 600 -3 838 846 -8 B6
10 558 600 -2 753 745 8 AA
11 558 600 -2 849 851 -2 B6
12 558 600 -2 853 856 -3 B6
13 558 600 -2 924 917 7 UA
14 558 600 -2 923 937 -14 UA
15 559 600 -1 941 910 31 AA
# ℹ 9 more variables: flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
# air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>Manipulação de dados com dplyr
- A função
mutate()é utilizada para criar novas colunas a partir de colunas existentes.
# A tibble: 15 × 20
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
11 2013 1 1 558 600 -2 849 851
12 2013 1 1 558 600 -2 853 856
13 2013 1 1 558 600 -2 924 917
14 2013 1 1 558 600 -2 923 937
15 2013 1 1 559 600 -1 941 910
# ℹ 12 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>, speed <dbl>Manipulação de dados com dplyr
- Existe também a função
summarise(), que é utilizada para resumir os dados. - A função
summarise()é muito útil para resumir os dados e obter estatísticas descritivas.
# A tibble: 1 × 2
mean_distance mean_air_time
<dbl> <dbl>
1 1040. NA- Observe que para a variável
air_timeo resultado foiNA, isso ocorreu porque a funçãomean()não sabe o que fazer com valores faltantes. Nesse caso, devemos passar como argumento para remover os valores faltantes.
Manipulação de dados com dplyr
- A função
group_by()é utilizada para agrupar os dados por uma ou mais variáveis.
dados |>
dplyr::group_by(month) |>
dplyr::summarise(mean_distance = mean(distance),
mean_air_time = mean(air_time, na.rm = TRUE)) # A tibble: 12 × 3
month mean_distance mean_air_time
<int> <dbl> <dbl>
1 1 1007. 154.
2 2 1001. 151.
3 3 1012. 149.
4 4 1039. 153.
5 5 1041. 146.
6 6 1057. 150.
7 7 1059. 147.
8 8 1062. 148.
9 9 1041. 143.
10 10 1039. 149.
11 11 1050. 155.
12 12 1065. 163.Manipulação de dados com dplyr
- Contagens também é uma operação muito comum, e para isso, utilizamos a função
n().
Manipulação de dados com dplyr
Também conseguimos agrupar por múltiplas variáveis, basta passar mais argumentos para a função group_by()
pacote ggplot2
ggplot2
![]()
O ggplot2 (https://ggplot2.tidyverse.org/) é um sistema para a criação declarativa de gráficos, baseado na Gramática de Gráficos. Você fornece os dados, informa ao ggplot2 como mapear as variáveis para os atributos estéticos, quais primitivas gráficas usar, e ele cuida dos detalhes1.
ggplot2
ggplot2
O que é gramática de dados?
- Foi criado em 2005 por Wilkinson para descrever as características fundamentais que estão por trás de todos os gráficos.
Em resumo, a gramática de gráficos nos diz que um gráfico mapeia os dados para atributos estéticos (cor, forma, tamanho) de objetos geométricos (pontos, linhas, barras). Além disso, o gráfico também pode incluir transformações estatísticas nos dados e informações sobre o sistema de coordenadas.
ggplot2
- O ggplot2 (Wickham 2009) baseia-se na gramática de Wilkinson, focando na primazia das camadas e adaptando-a para uso no R.
Todos os gráficos são compostos pelos dados, a informação que você deseja visualizar, e um mapeamento, a descrição de como as variáveis dos dados são mapeadas para os atributos estéticos.
Existem cinco componentes de mapeamento:
- Camadas;
- Escalas;
- Coordenadas;
- Facetas;
- Temas.
ggplot2
Componentes de mapeamento:
Todo gráfico em ggplot2 será iniciado com a função ggplot e, em seguida, adicionaremos dados, e demais informações. Uma dessas opções que podem ser adicionadas na função ggplot é o aes().
aes(): são mapeamentos estéticos que descrevem como as variáveis dos dados são mapeadas para propriedades visuais (estéticas).
ggplot2
Camadas:
- As camadas são coleções de elementos geométricos e transformações estatísticas. Os elementos geométricos, conhecidos como geoms, representam o que você realmente vê no gráfico: pontos, linhas, polígonos, etc. As transformações estatísticas, chamadas de stats, resumem os dados: por exemplo, agrupando e contando observações para criar um histograma ou ajustando um modelo.
O exemplo anterior não possui todas as camadas, vamos considerar um novo exemplo!
ggplot2
library(ggplot2)
# Usando o dataset 'milhas' do pacote 'dados'
milhas <- dados::milhas
# Criando o gráfico com os 5 componentes
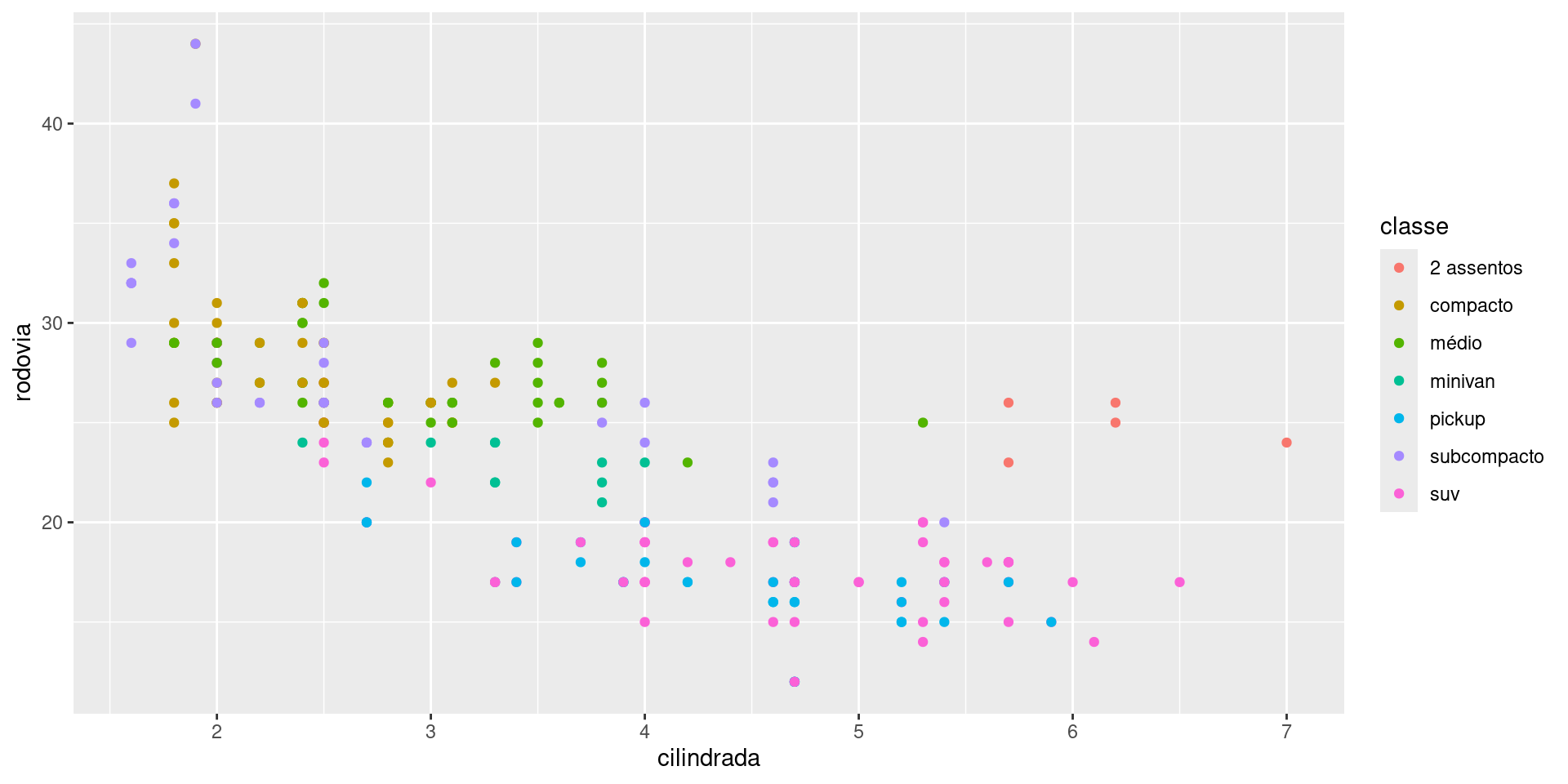
ggplot(milhas, aes(cilindrada, rodovia, colour = classe)) +
# Camada de pontos geométricos
geom_point() +
# Escala de cor manual
scale_colour_manual(values = c("2 assentos" = "red", "compacto" = "blue",
"médio" = "green", "minivan" = "purple",
"pickup" = "orange", "subcompacto" = "brown",
"suv" = "pink")) +
# Sistema de coordenadas polar para um efeito diferenciado
coord_cartesian()+
# Facetando (subdividindo) o gráfico por tipo de tração (drv)
facet_wrap(~ tracao) +
# Tema minimalista para controlar os detalhes visuais
theme_minimal(base_size = 15, base_family = "Arial") +
# Título do gráfico
labs(title = "Consumo na Rodovia vs Cilindrada",
x = "Cilindrada do motor (litros)",
y = "Consumo na rodovia (mpg)",
colour = "Classe do veículo")ggplot2
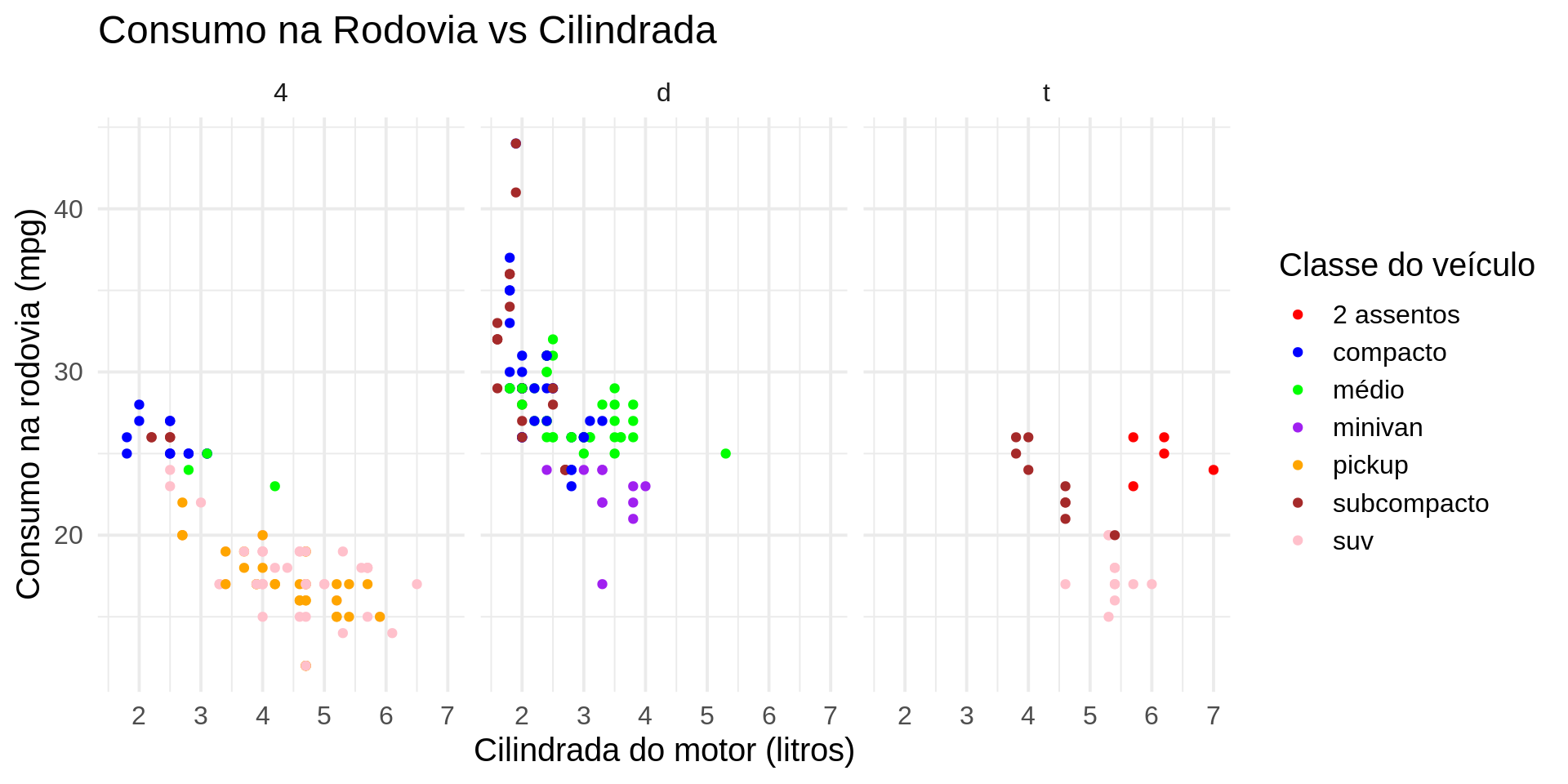
ggplot2
Escalas:
- As Escalas mapeiam valores no espaço dos dados para valores no espaço estético. Isso inclui o uso de cor, forma ou tamanho. As escalas também desenham a legenda e os eixos, que possibilitam a leitura dos valores originais dos dados a partir do gráfico (um mapeamento inverso).
library(ggplot2)
milhas <- dados::milhas
ggplot(milhas, aes(cilindrada, rodovia, colour = classe)) +
geom_point() +
scale_colour_manual(values = c("2 assentos" = "red", "compacto" = "blue",
"médio" = "green", "minivan" = "purple",
"pickup" = "orange", "subcompacto" = "brown",
"suv" = "pink")) +
coord_cartesian()+
facet_wrap(~ tracao) +
theme_minimal(base_size = 15, base_family = "Arial")ggplot2
Coordenadas:
- As Coordenadas ou sistema de coordenadas, descreve como as coordenadas dos dados são mapeadas no plano gráfico. Ele também fornece eixos e linhas de grade para ajudar a ler o gráfico. Normalmente usamos o sistema de coordenadas Cartesiano, mas vários outros estão disponíveis, incluindo coordenadas polares e projeções de mapas.
library(ggplot2)
milhas <- dados::milhas
ggplot(milhas, aes(cilindrada, rodovia, colour = classe)) +
geom_point() +
scale_colour_manual(values = c("2 assentos" = "red", "compacto" = "blue",
"médio" = "green", "minivan" = "purple",
"pickup" = "orange", "subcompacto" = "brown",
"suv" = "pink")) +
coord_cartesian()+
facet_wrap(~ tracao) +
theme_minimal(base_size = 15, base_family = "Arial")ggplot2
Facetas:
- As facetas especificam como dividir e exibir subconjuntos de dados como múltiplos gráficos pequenos. Isso também é conhecido como condicionamento ou latticing/trellising.
library(ggplot2)
milhas <- dados::milhas
ggplot(milhas, aes(cilindrada, rodovia, colour = classe)) +
geom_point() +
scale_colour_manual(values = c("2 assentos" = "red", "compacto" = "blue",
"médio" = "green", "minivan" = "purple",
"pickup" = "orange", "subcompacto" = "brown",
"suv" = "pink")) +
coord_cartesian()+
facet_wrap(~ tracao) +
theme_minimal(base_size = 15, base_family = "Arial")ggplot2
Temas:
- Os temas controlam os detalhes mais finos de exibição, como o tamanho da fonte e a cor de fundo. Embora os padrões no ggplot2 tenham sido escolhidos com cuidado, pode ser necessário consultar outras referências para criar um gráfico mais atraente e editar os existentes da melhor forma que preferir.
library(ggplot2)
milhas <- dados::milhas
ggplot(milhas, aes(cilindrada, rodovia, colour = classe)) +
geom_point() +
scale_colour_manual(values = c("2 assentos" = "red", "compacto" = "blue",
"médio" = "green", "minivan" = "purple",
"pickup" = "orange", "subcompacto" = "brown",
"suv" = "pink")) +
coord_cartesian()+
facet_wrap(~ tracao) +
theme_minimal(base_size = 15, base_family = "Arial")ggplot2
Construindo um gráfico no R
Abrir o
RStudio;Abrir um novo arquivo
R:File > New File > R Script- ou \(\quad\)
Ctrl + Shift + N;
ggplot2
# A tibble: 3 × 11
fabricante modelo cilindrada ano cilindros transmissao tracao cidade rodovia
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int>
1 audi a4 1.8 1999 4 auto(l5) d 18 29
2 audi a4 1.8 1999 4 manual(m5) d 21 29
3 audi a4 2 2008 4 manual(m6) d 20 31
# ℹ 2 more variables: combustivel <chr>, classe <chr>- Vamos visualizar o tipo das variáveis
tibble [234 × 11] (S3: tbl_df/tbl/data.frame)
$ fabricante : chr [1:234] "audi" "audi" "audi" "audi" ...
$ modelo : chr [1:234] "a4" "a4" "a4" "a4" ...
$ cilindrada : num [1:234] 1.8 1.8 2 2 2.8 2.8 3.1 1.8 1.8 2 ...
$ ano : int [1:234] 1999 1999 2008 2008 1999 1999 2008 1999 1999 2008 ...
$ cilindros : int [1:234] 4 4 4 4 6 6 6 4 4 4 ...
$ transmissao: chr [1:234] "auto(l5)" "manual(m5)" "manual(m6)" "auto(av)" ...
$ tracao : chr [1:234] "d" "d" "d" "d" ...
$ cidade : int [1:234] 18 21 20 21 16 18 18 18 16 20 ...
$ rodovia : int [1:234] 29 29 31 30 26 26 27 26 25 28 ...
$ combustivel: chr [1:234] "p" "p" "p" "p" ...
$ classe : chr [1:234] "compacto" "compacto" "compacto" "compacto" ...Quem desejar entender o que significa cada variável da base pode executar
?dados::milhasno console.
ggplot2
- Vamos criar um gráfico de dispersão entre as colunas
cilindradaerodovia
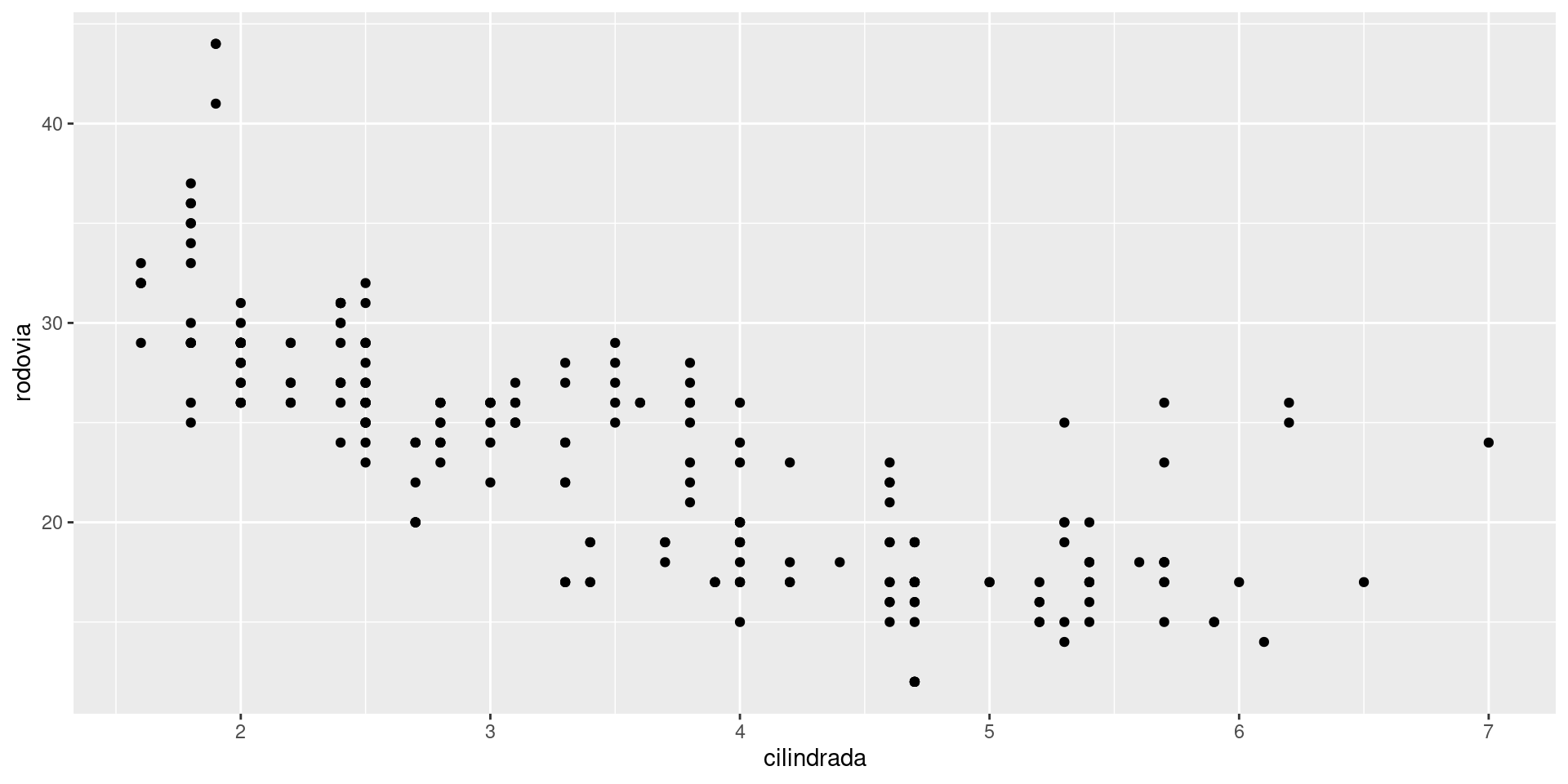
ggplot2
Vamos separar as observações por tipo do carro
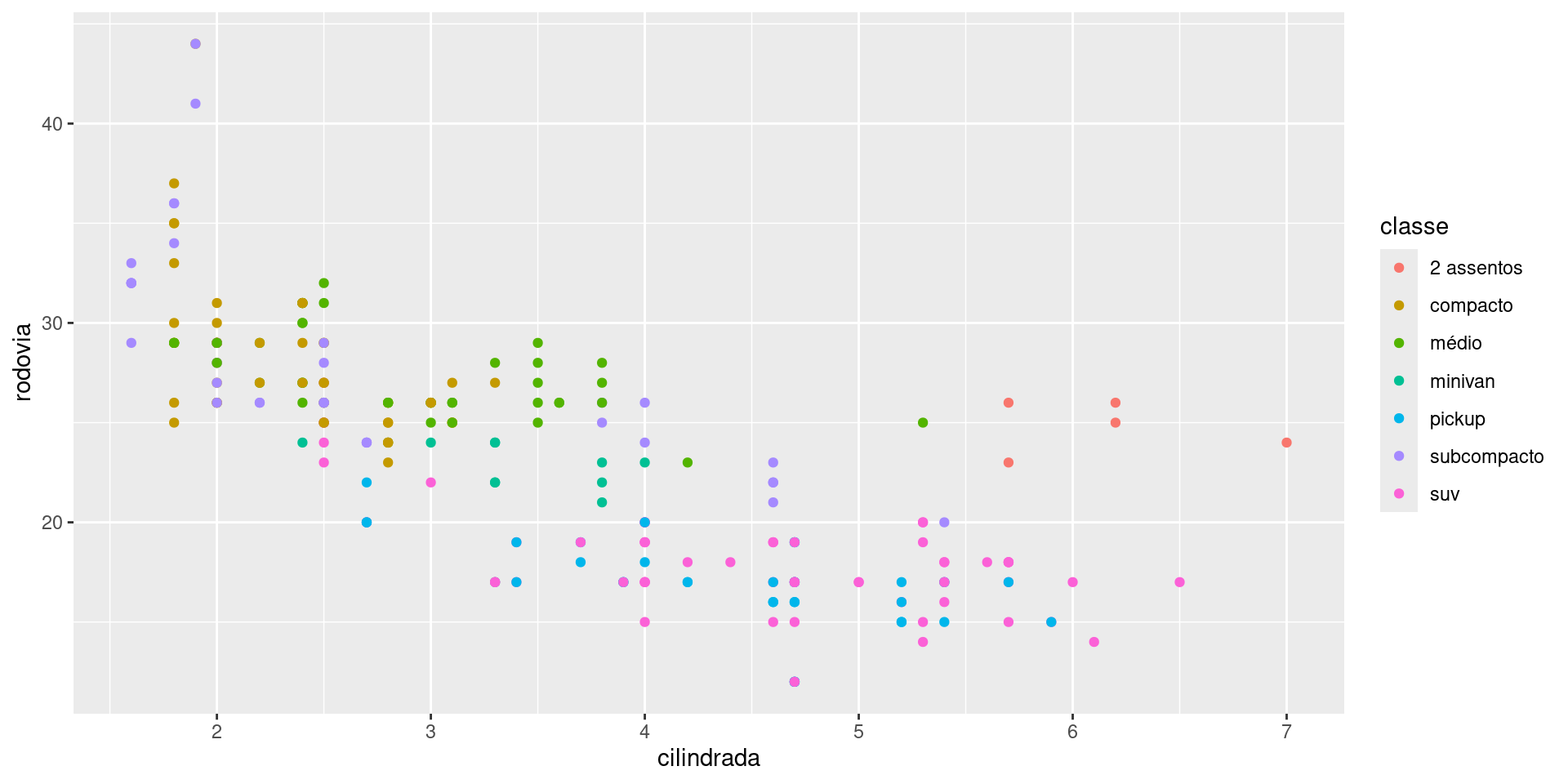
ggplot2
Uma segunda forma de fazer, é:
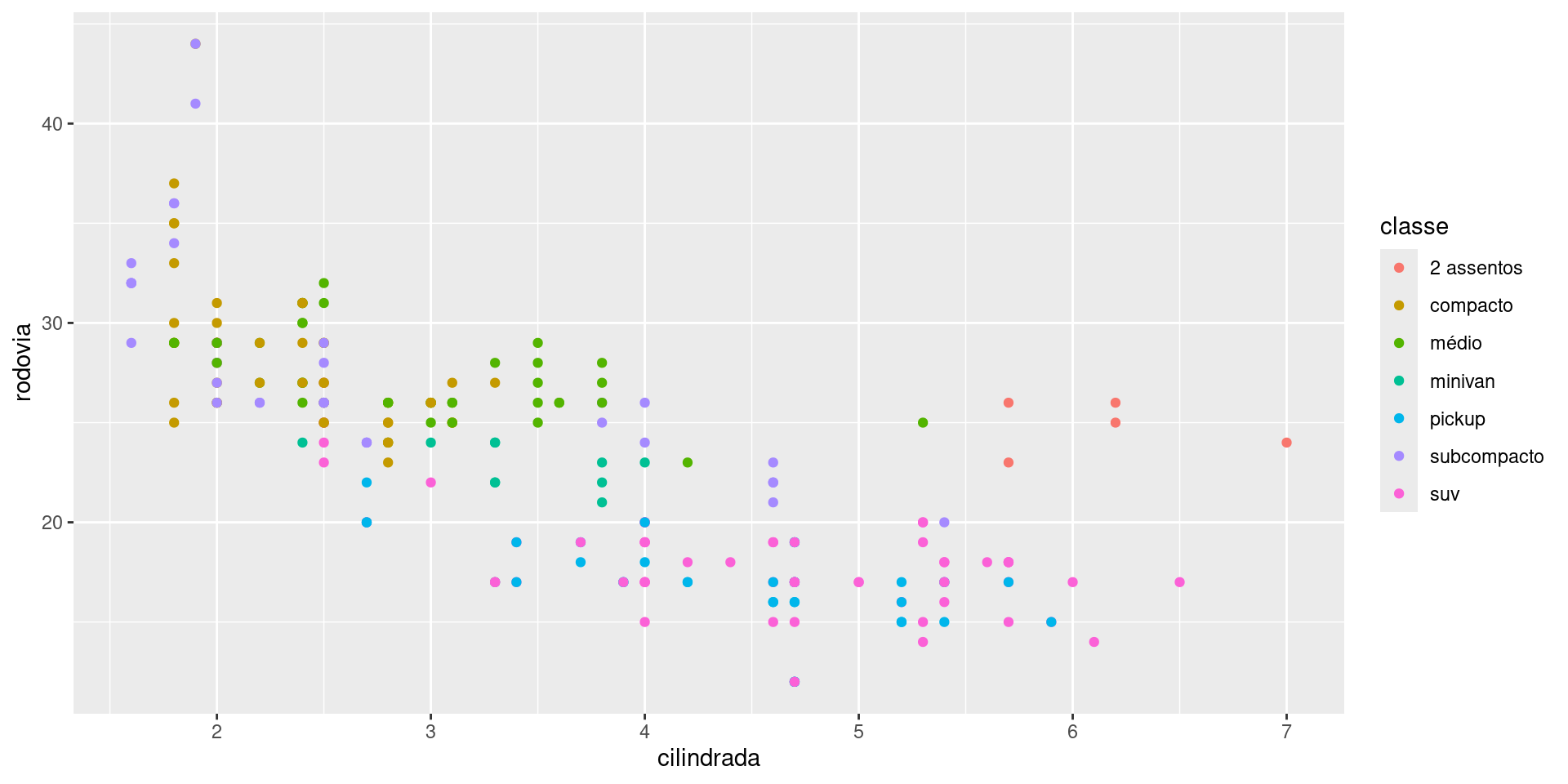
ggplot2
Utilizando facetamento por tipo do carro:
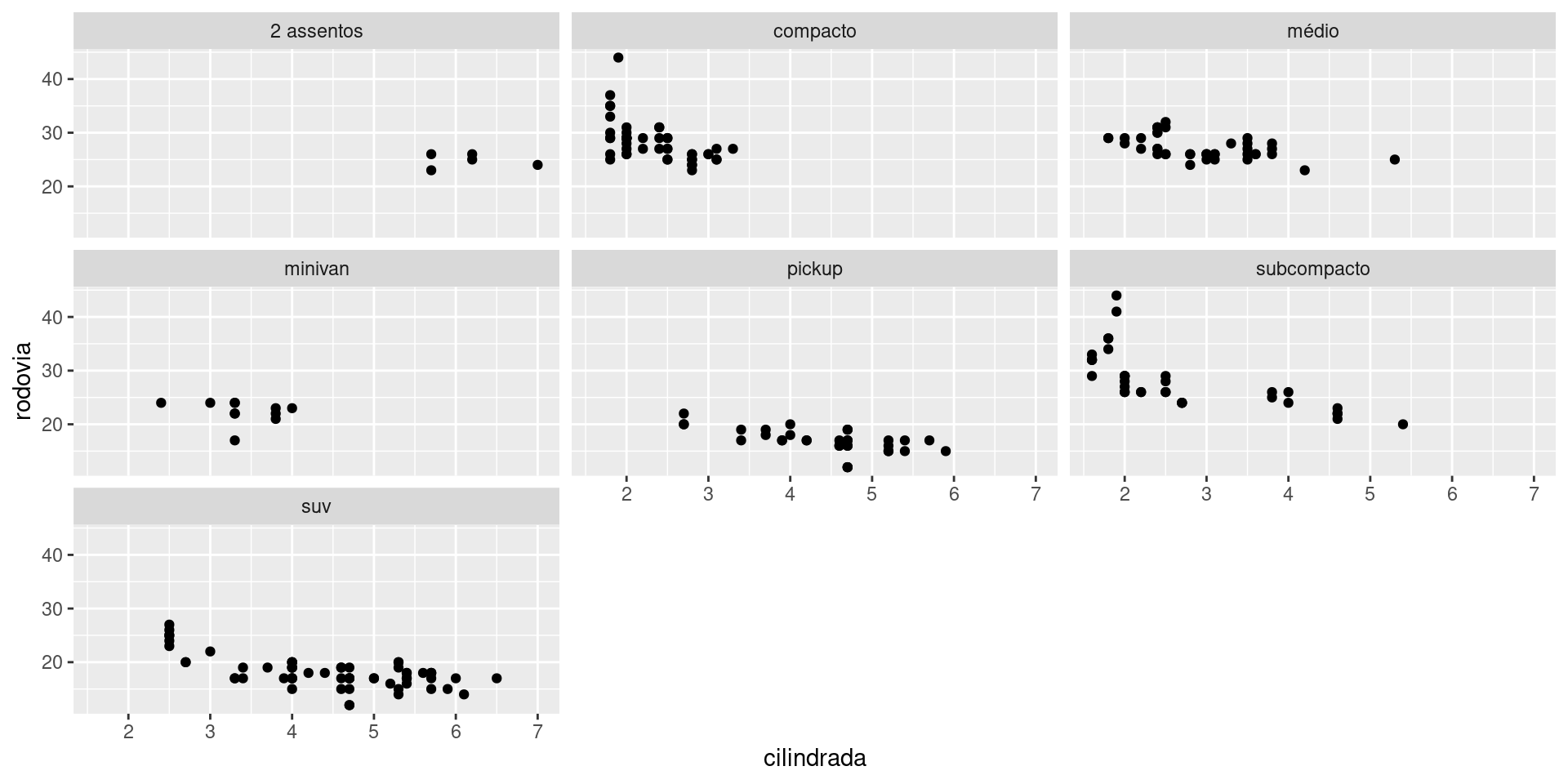
ggplot2
Estamos interessados em fazer Box-Plot, logo:
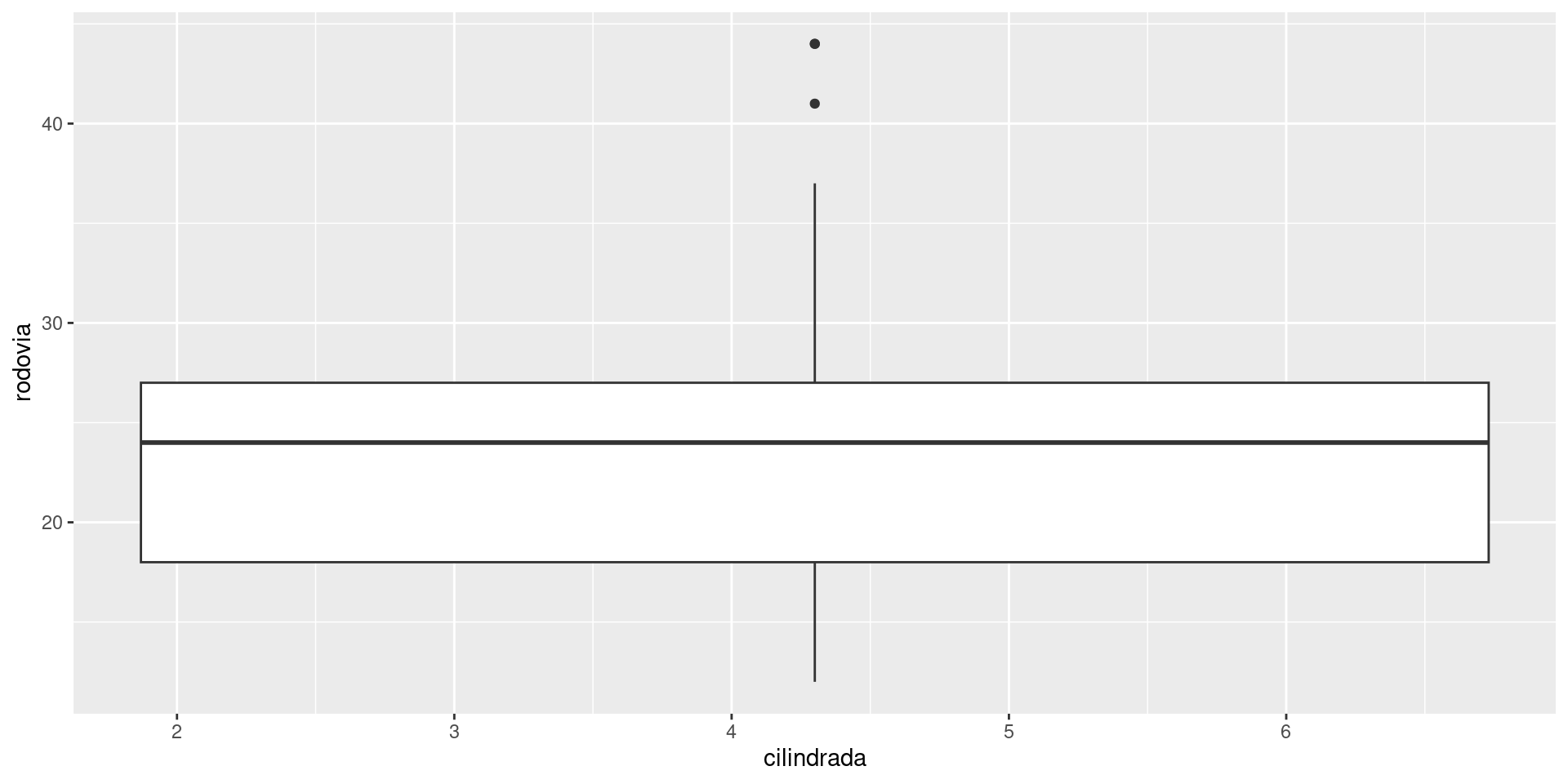
ggplot2
Estamos interessados em fazer Box-Plot, por tipo de carro, assim:
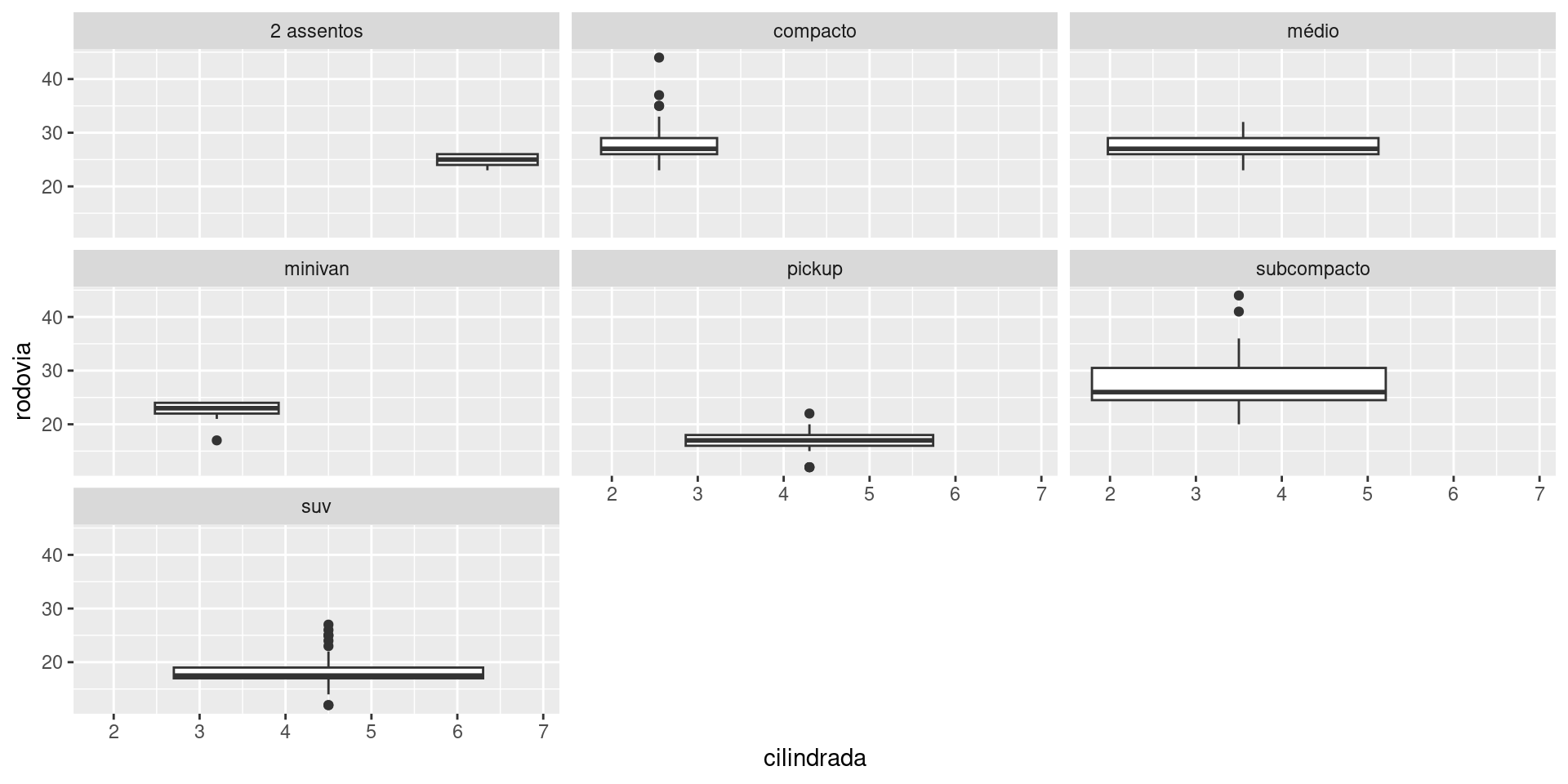
ggplot2
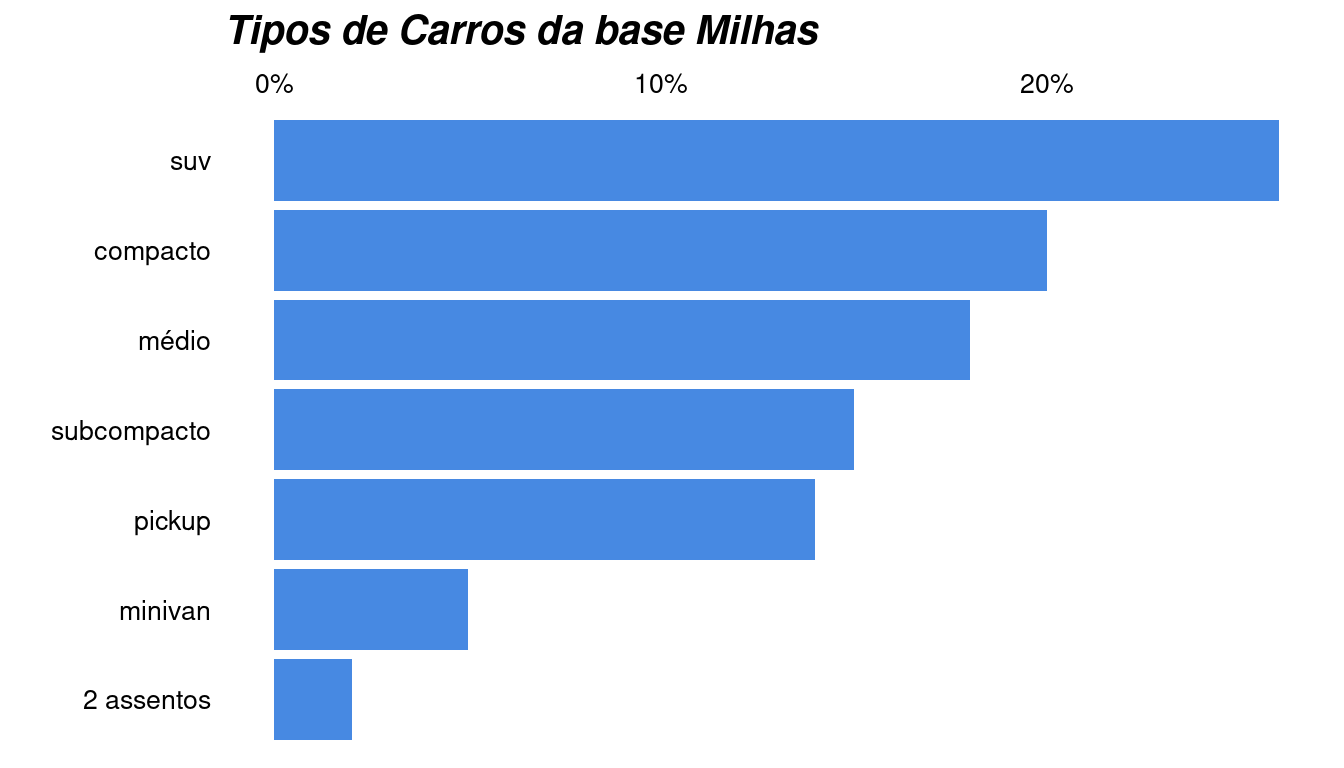
Vamos construir um gráfico de barras horizontais com percentual por categoria, tema minimalista e na tonalidade azul.
Mas primeiro, vamos entender como tratar os dados e construir o gráfico na forma padrão (vertical), e em seguida ir modificando.
library(dplyr)
# Criando um novo data.frame com proporções
classes_milhas <- milhas |>
count(classe) |>
mutate(prop = round(prop.table(n),2))
#' --------------------
#' Ordenando as colunas pela frequência
classes_milhas$classe <- factor(classes_milhas$classe,
levels = classes_milhas$classe[order(classes_milhas$n, decreasing = F)])ggplot2
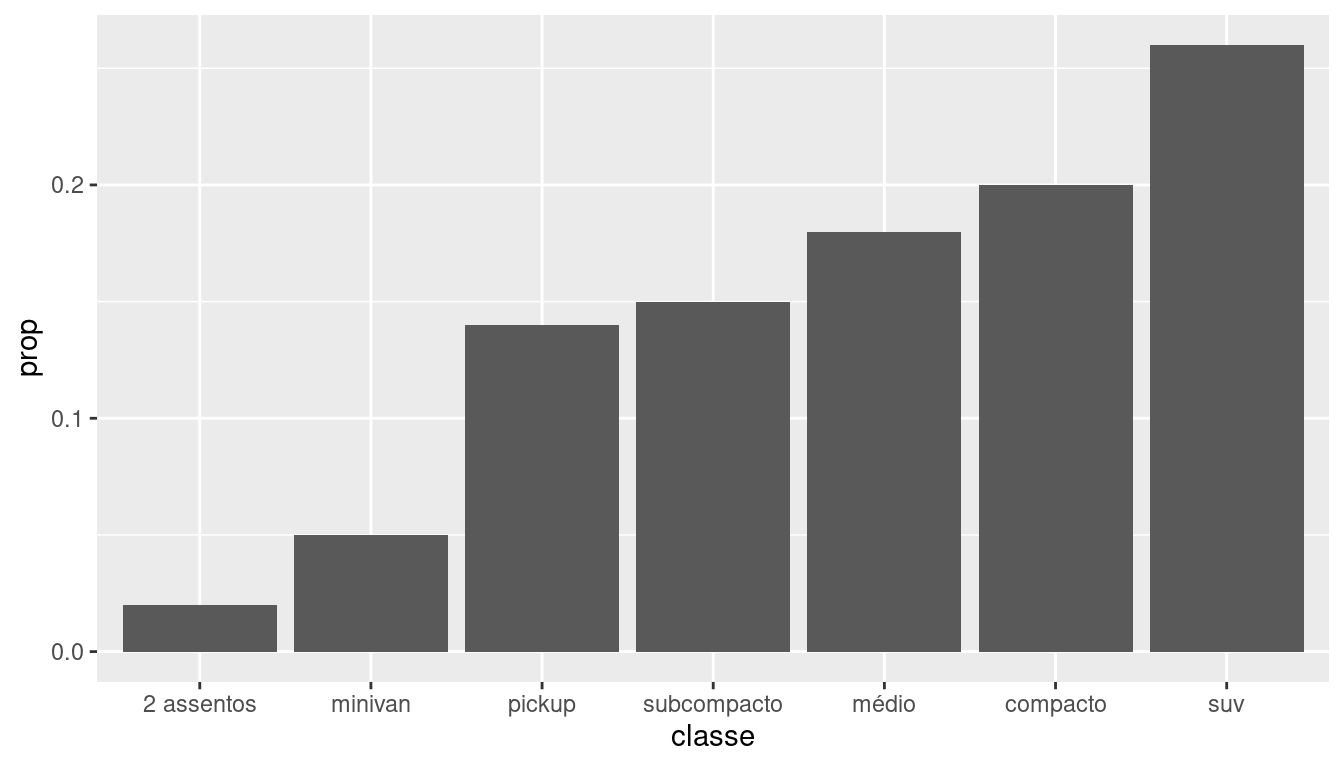
ggplot2
Agora vamos colocar as barras na horizontal e tonalidade azul:
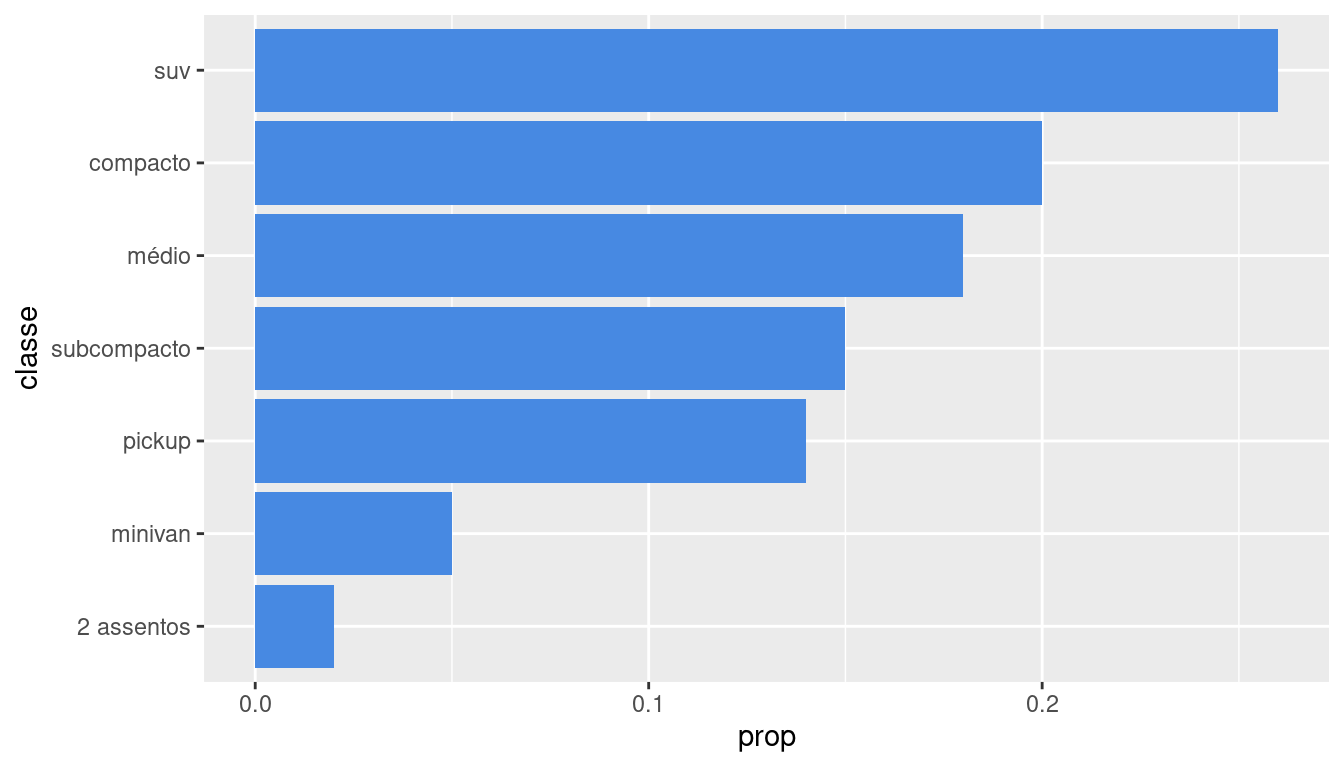
ggplot2
Modificando o tema do gráfico:
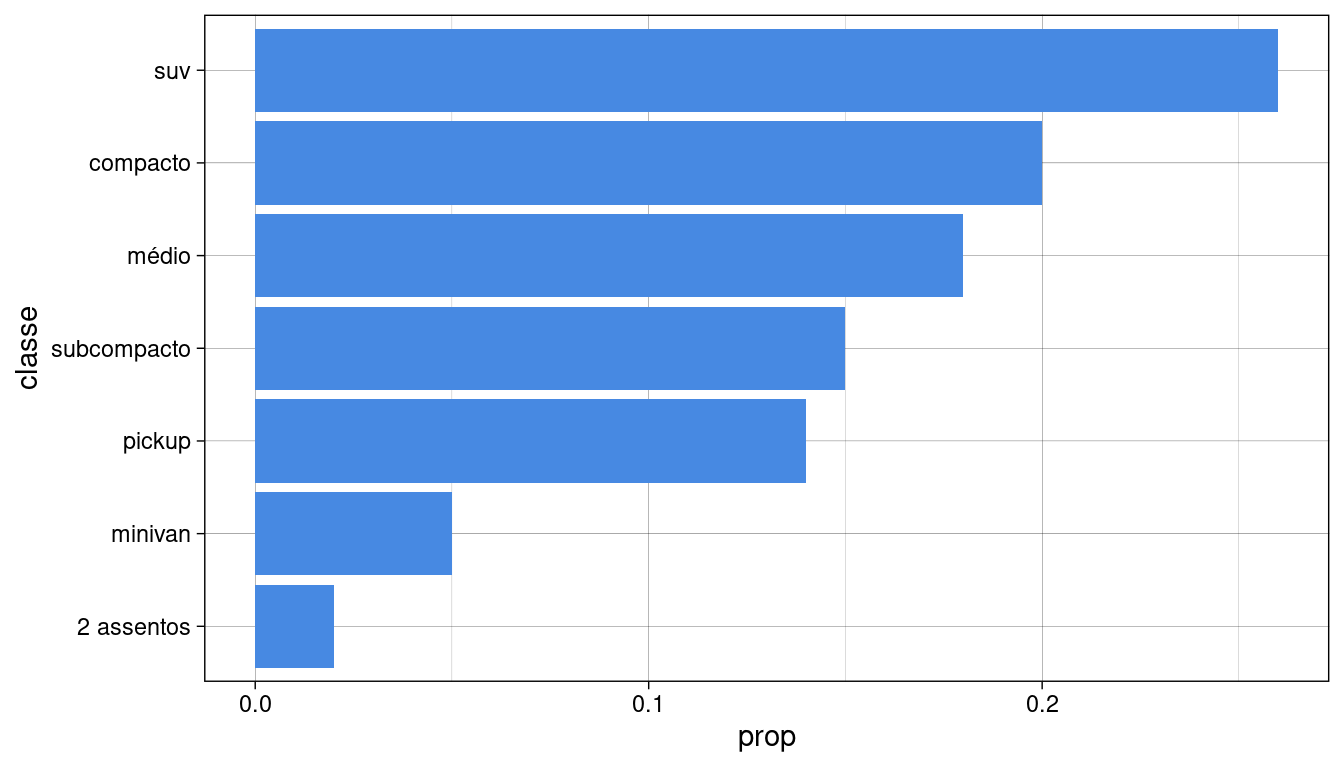
ggplot2
removendo os nomes dos eixos xe y:
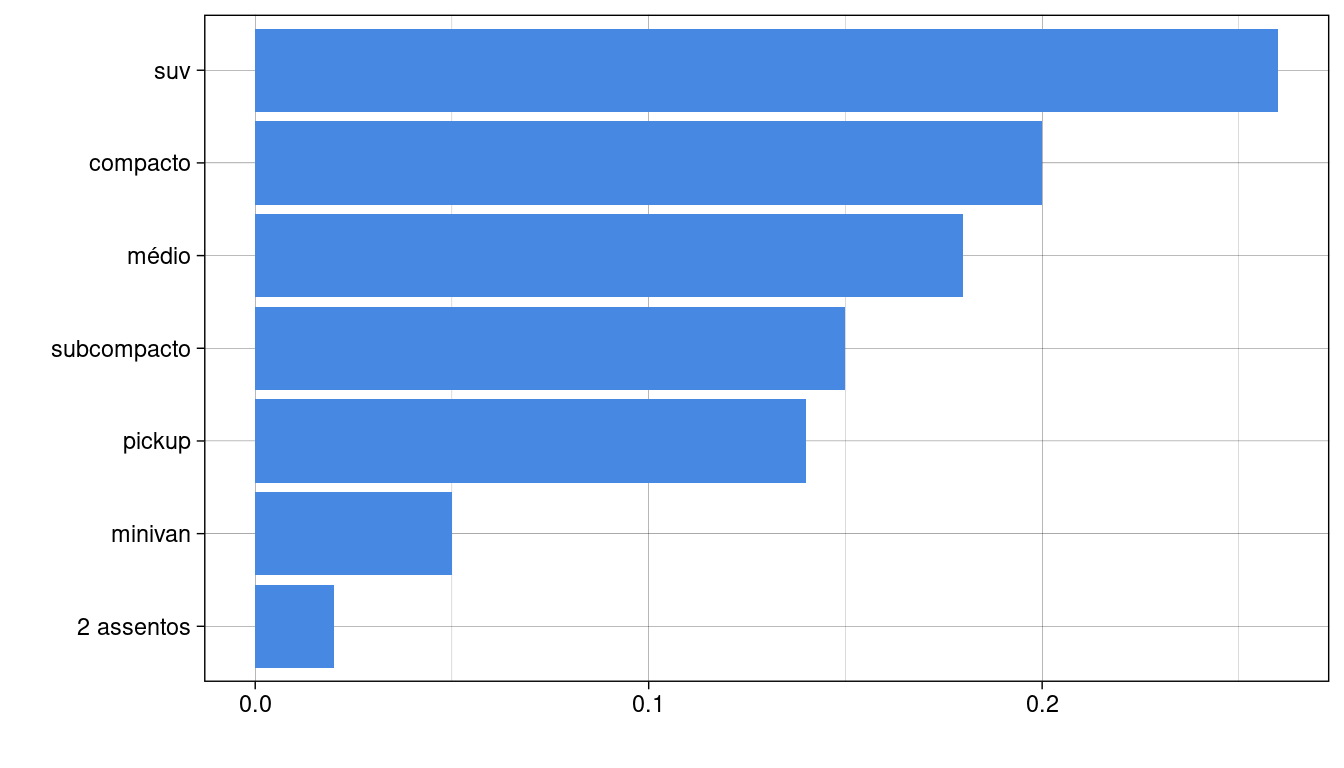
ggplot2
ggplot2
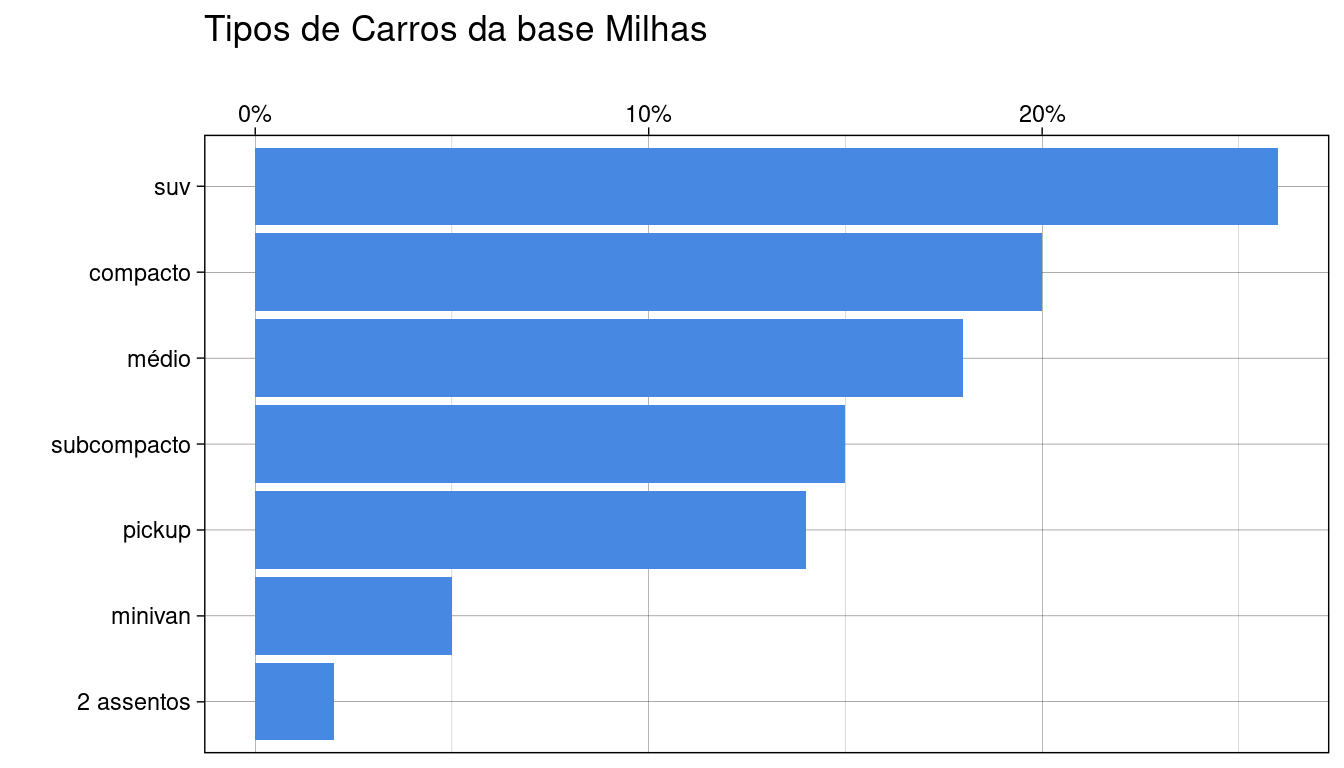
Nosso gráfico final, após algumas adições de camadas:
ggplot(classes_milhas, aes(classe, y = prop)) +
geom_bar(stat = 'identity', fill = "#4789e2") +
coord_flip() +
theme_linedraw() +
xlab("") +
ylab("") +
labs(title = "Tipos de Carros da base Milhas") +
scale_y_continuous(labels = scales::percent_format(), position = "right" ) +
theme(axis.text = element_text(size=10),
plot.title = element_text(color="black", size=15, face="bold.italic"),
#--
axis.title.x = element_blank(),
#--
axis.ticks = element_blank(),
panel.border = element_blank(),
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_rect(fill = "transparent",colour = NA),
plot.background = element_rect(fill = "transparent",colour = NA))ggplot2
Nosso gráfico final, após algumas adições de camadas:
vamos praticar!
Criação de mapas com R
Vamos criar mapas de 3 formas diferentes, todos utilizando o conceito de dados de área:
- Criando mapas com auxílio do pacote
geobr;
- Criando mapas utilizando arquivos shapefile (.shp);
- Criando mapas iterativos com shapefile (.shp) e o pacote
leaflet;
Criando mapas com geobr
![]()
geobré um pacote computacional para download de conjuntos de dados espaciais oficiais do Brasil. O pacote inclui uma ampla gama de dados geoespaciais em formato de geopacote (como shapefiles), disponíveis em várias escalas geográficas e por vários anos com atributos harmonizados, projeção e topologia1.
Criando mapas com geobr
Para criarmos nosso mapa, vamos precisar gerar dados para serem as informações existentes no mapa. Dessa forma, vamos supor que estamos gerando quantas pessoas estão no youtube nesse momento em cada estado do Brasil. Vamos gerar esses dados através de simulação, sendo uma amostra de tamanho 1.000, que vai discrimar aleatoriamente cada observação para os 26 estados + DF do país.
Lista dos estados do Brasil (BR):
- Acre - AC;
- Alagoas - AL;
- Amapá - AP;
- Amazonas - AM;
- Bahia - BA;
- Ceará - CE;
- Distrito Federal - DF;
- Espírito Santo - ES;
- Goiás - GO;
- Maranhão - MA;
- Mato Grosso - MT;
- Mato Grosso do Sul - MS;
- Minas Gerais - MG;
- Pará - PA;
- Paraíba - PB;
- Paraná - PR;
- Pernambuco - PE;
- Piauí - PI;
- Roraima - RR;
- Rondônia - RO;
- Rio de Janeiro - RJ;
- Rio Grande do Norte - RN;
- Rio Grande do Sul - RS;
- Santa Catarina - SC;
- São Paulo - SP;
- Sergipe - SE;
- Tocantins - TO.
Criando mapas com geobr
# Adicionando uma semente
set.seed(29)
# Estados
estados <- c("AC", "AL", "AP", "AM", "BA", "CE", "DF", "ES",
"GO", "MA", "MT", "MS", "MG", "PA", "PB", "PR",
"PE", "PI", "RR", "RO", "RJ", "RN", "RS", "SC",
"SP", "SE", "TO")
# Verificando se existem 27 estados
estados |>
length()[1] 27# Criando uma amostra de tamanho 1.000
amostra <- sample(x = estados, size = 1000, replace = TRUE)
# Verificando as frequências em cada estado
amostra |>
table()amostra
AC AL AM AP BA CE DF ES GO MA MG MS MT PA PB PE PI PR RJ RN RO RR RS SC SE SP
35 42 35 34 35 33 33 37 31 42 35 38 31 42 36 45 32 41 35 35 40 37 39 40 44 35
TO
38 Criando mapas com geobr
Em geral ficou uma amostra uniforme, em torno da frequẽncia 35. Vamos agora chamar a biblioteca e gerar o mapa usando o geobr.
No Debian/Ubuntu, foi necessário instalar a libudunits2-dev no terminal do linux;
Após a instalação da biblioteca no Sistema operacional, foi utilizado o comando para instalar o pacote novamente e se tudo ocorreu como esperado, o pacote foi instalado com sucesso!
Criando mapas com geobr
Abaixo vamos seguir com o código da geração do mapa
# Lendo as bibliotecas
library(geobr) # Necessária para os dados dos mapas
library(dplyr) # Necessária para manipulação dos dados
# Convertendo a amostra em tibble
amostra <- as_tibble(amostra)
# Agrupando os dados dos estados
dados_estados <- amostra |>
mutate(abbrev_state = factor(value)) |>
group_by(abbrev_state) |>
summarise(n = n())
# Fazendo left_join das informações do geobr com os dados
dados_mapa <- read_state(year=2019, showProgress = FALSE) |>
left_join(dados_estados)Criando mapas com geobr
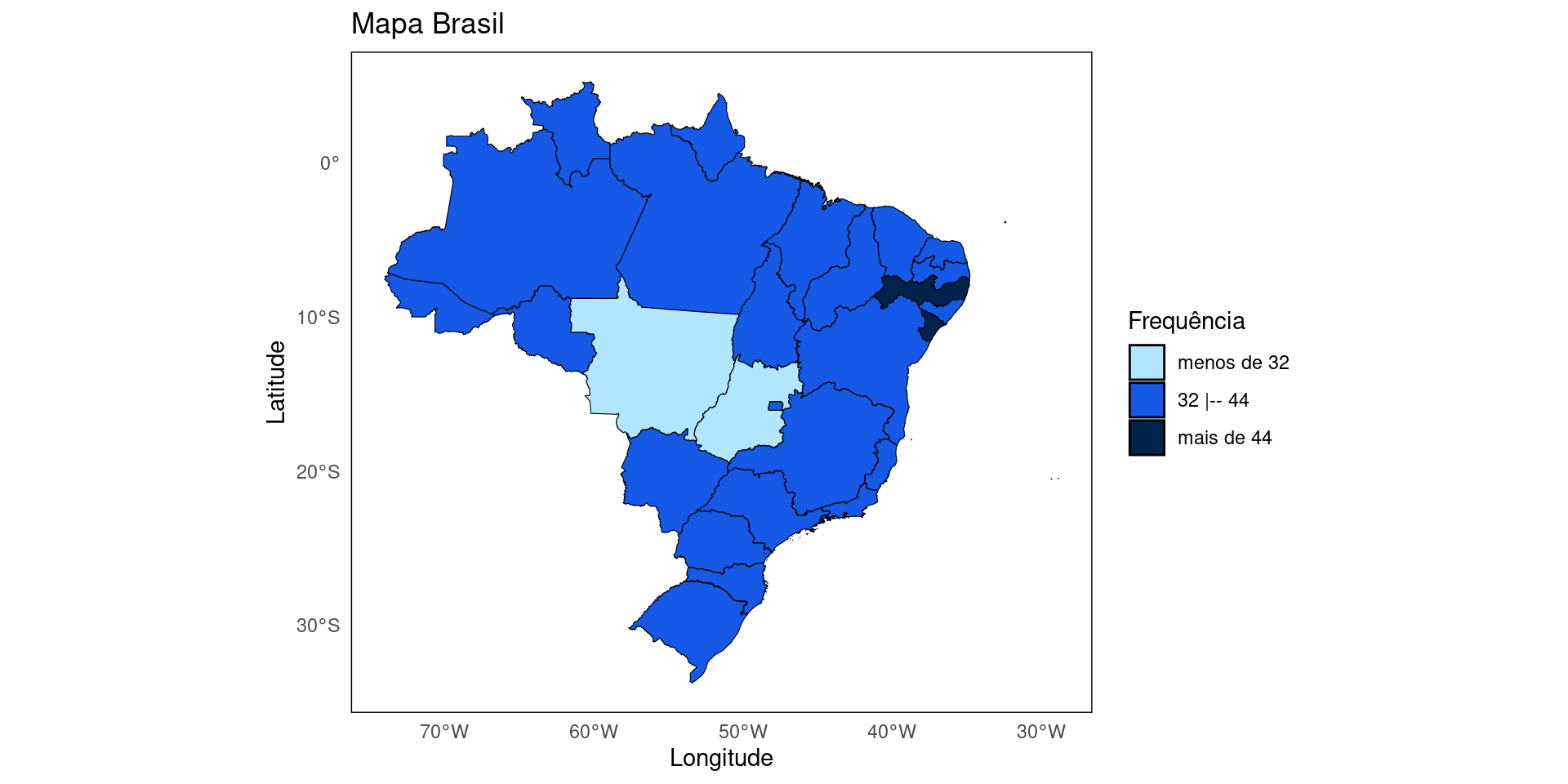
Gerando o mapa utilizando a frequência gerada pelo prórpio ggplot:
# Pacote ggplot2
library(ggplot2)
# Código do MAPA
mapa <- dados_mapa |>
ggplot() +
geom_sf(aes(fill = n)) +
labs(title = "Mapa Brasil", fill = "Frequência")+
theme_minimal()+
theme(axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
panel.grid = element_blank())Criando mapas com geobr
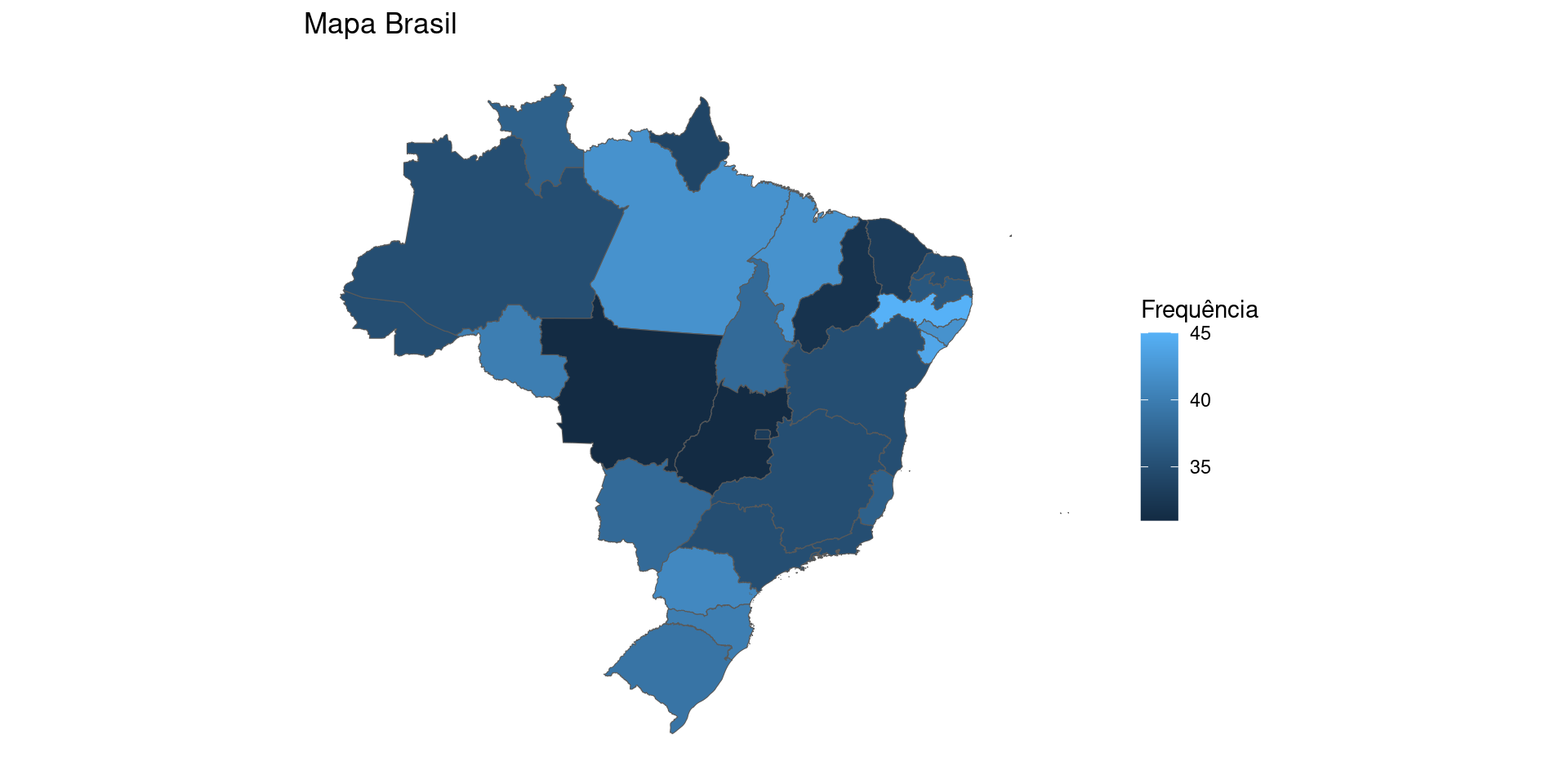
Criando mapas com geobr
Criando um intervalo e fazendo o gráfico de acordo com a legenda criada:
# Descobrindo o maximo e minimo para definir a quantidade de intervalos
# Calculando o máximo, mínimo e amplitude
maximo <- max(dados_mapa$n);
minimo <- min(dados_mapa$n);
amplitude <- max(dados_mapa$n) - min(dados_mapa$n)
print(c(minimo, maximo, amplitude))[1] 31 45 14# Por questão de facilidade vamos dividir em 3 categorias:
# 1 - Frequência de menos de 'minimo+1';
# 2 - Frequência de 'minimo+1' até 'máximo-1';
# 3 - Frequência de 'máximo-1' ou mais;
#Criando os Intervalos para a Legenda
classes = c(-Inf, minimo+1, maximo-1, Inf)
classes_plot <- findInterval(dados_mapa$n,classes)
# Criar legenda
legenda = c(paste0('menos de ',minimo+1),
paste0(minimo+1,' |-- ',maximo-1),
paste0('mais de ',maximo-1))
cores = c("#b2e6ff",
"#1659e6",
"#00234b")Criando mapas com geobr
Gerando o mapa atualizado:
# Adicionando a coluna classes_plot no tibble dados_mapa
dados_mapa <- dados_mapa |>
mutate(classes_plot = factor(classes_plot))
# Pacote ggplot2
library(ggplot2)
# Código do MAPA
mapa <- dados_mapa |>
ggplot() +
geom_sf(aes(fill = classes_plot), color = "black") +
labs(title = "Mapa Brasil",
x = "Longitude",
y = "Latitude",
fill = "Frequência")+
scale_fill_manual(labels = legenda,
values = cores)+
theme_minimal() +
theme(
panel.grid = element_blank(), # Remove grade
panel.border = element_rect(color = "black", fill = NA) # Adiciona borda
)Criando mapas com geobr
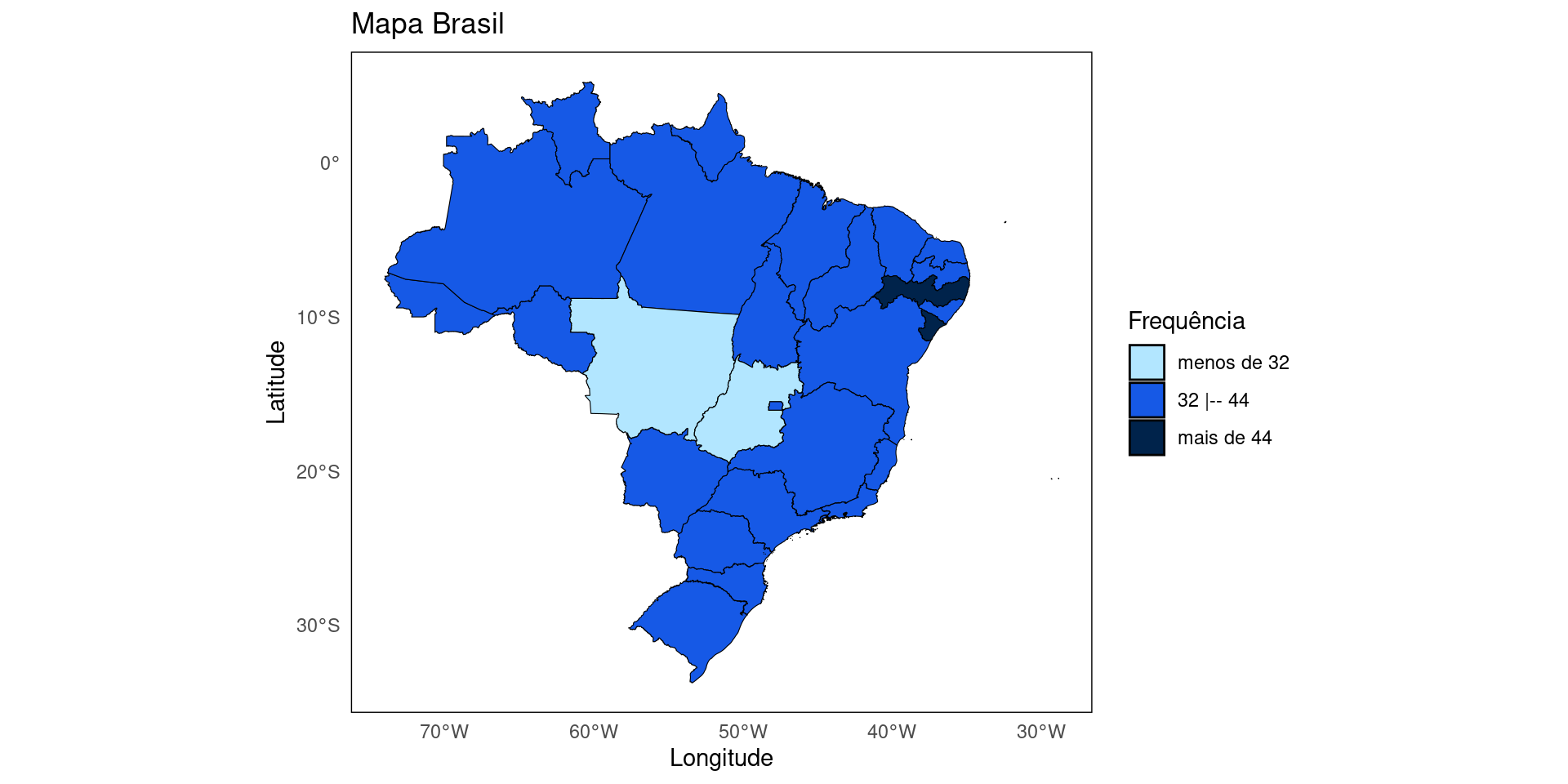
Criando mapas com shapefile
A ideia é semelhante a utilizar o pacote geobr, entretanto, nesse caso, precisamos ter o arquivo do shape, que no exemplo anterior, foi baixado diretamente do pacote geobr.
Neste caso, vamos precisar o pacote sf para leitura do arquivo shapefile.
No Debian/Ubuntu, foi necessário instalar as libs abaixo no terminal do linux;
Criando mapas com shapefile
Vamos utilizar neste caso um arquivo de teste para simular uma análise de dados e fazendo o gráfico utilizando o arquivo shapefile, vamos adicionar também uma Rosa dos Ventos.
Vamos nesse caso utilizar um arquivo de shapefile do estado da PB e dados também.
# ---- Load shapefile
shapename <- read_sf('dados/shape_estado_pb/Municipios.shp')
# ---- Carregar dados
dados <- read.csv2("dados/exemplo_de_base.csv")
dados |>
head(3) GEOCODIG_M NOME_MUNIC MICRORREGI NOME_MICRO cod UF coordy
1 2500106 Água Branca 25007 Serra do Teixeira 250010 PB -7.512
2 2500205 Aguiar 25005 Piancó 250020 PB -7.092
3 2500304 Alagoa Grande 25015 Brejo Paraibano 250030 PB -7.089
coordx casos POP2017
1 -37.641 0 10479.088
2 -38.171 0 5469.505
3 -35.635 0 25128.464Criando mapas com shapefile
Um ponto importante, é ter certeza que a ordenação dos dados da sua base é a mesma do shapefile. Assim, vamos criar um dataframe, mantendo a ordenação do shapefile.
# ---- Criando dataframe com a ordem correta do shapefile
codigoshape <- data.frame(GEOCODIG_M = shapename$GEOCODIG_M)
# ---- Unindo o shapefile com os dados
dados_mapa_shp <- shapename |>
left_join(dados, by = 'GEOCODIG_M')
dados_mapa_shp |>
head(3)Simple feature collection with 3 features and 21 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: -38.33535 ymin: -7.59681 xmax: -35.49084 ymax: -6.94149
CRS: NA
# A tibble: 3 × 22
OBJECTID GEOCODIG_M UF.x SIGLA NOME_MUNIC.x REGI_O MESORREGI_ NOME_MESO
<dbl> <dbl> <chr> <chr> <chr> <chr> <chr> <chr>
1 1 2500106 25 PB Água Branca Nordeste 2501 Sertão Para…
2 2 2500205 25 PB Aguiar Nordeste 2501 Sertão Para…
3 3 2500304 25 PB Alagoa Grande Nordeste 2503 Agreste Par…
# ℹ 14 more variables: MICRORREGI.x <chr>, NOME_MICRO.x <chr>,
# SHAPE_LENG <dbl>, SHAPE_AREA <dbl>, geometry <MULTIPOLYGON>,
# NOME_MUNIC.y <chr>, MICRORREGI.y <int>, NOME_MICRO.y <chr>, cod <int>,
# UF.y <chr>, coordy <dbl>, coordx <dbl>, casos <int>, POP2017 <dbl>A partir de agora, vamos utilizar o dataframe dados_mapa para fazer o gráfico.
Criando mapas com shapefile
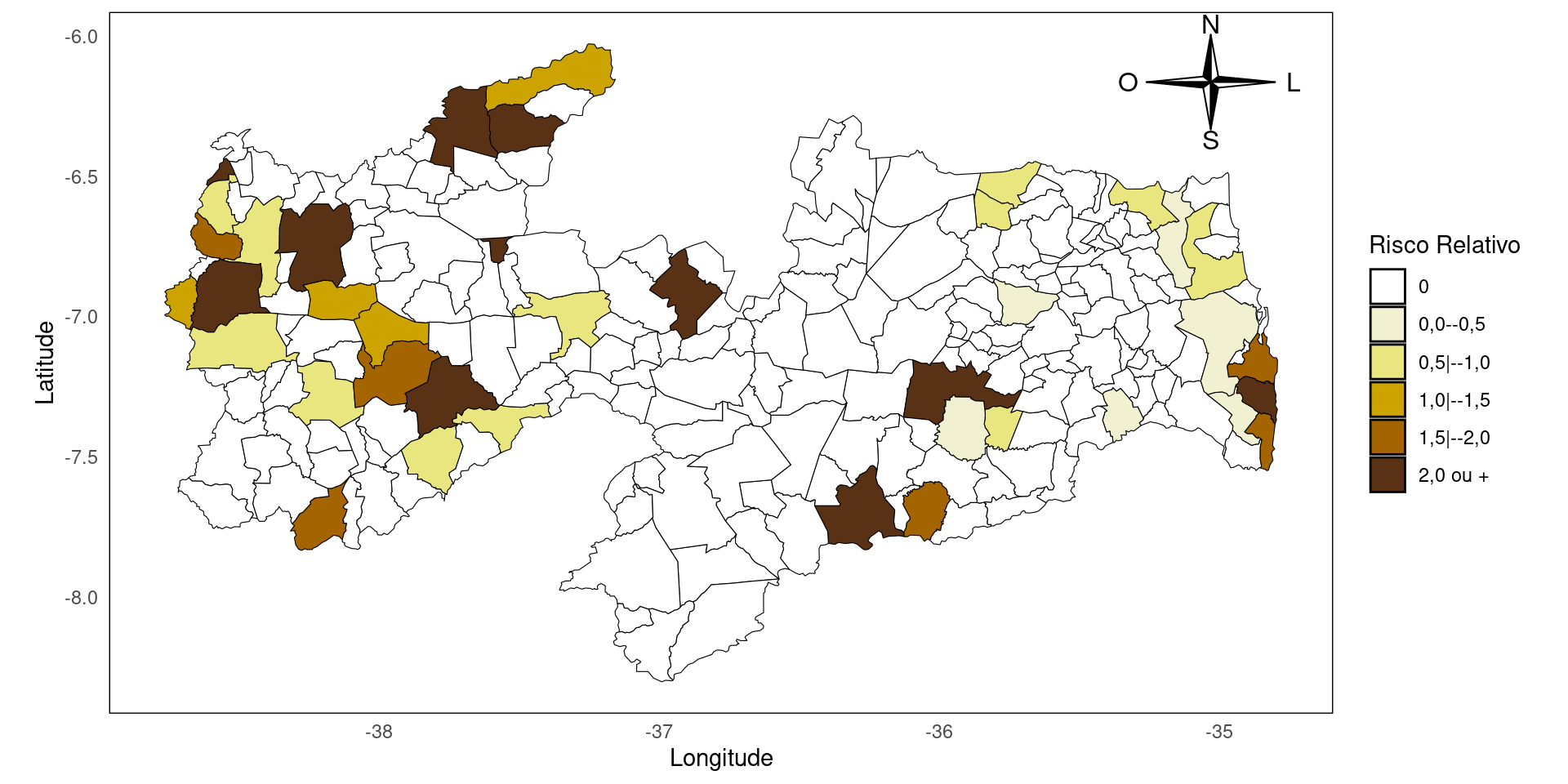
Em nosso dataframe, temos as informações de casos de uma doença X e também temos informações da população por município. Vamos encontrar uma taxa denominada Risco Relativo, que é a razão entre a incidência local (por município) pela incidência total (estado da PB).
# ---- Selecionar coluna de variáveis para gerar mapa
casos <- dados_mapa_shp$casos
pop <- dados_mapa_shp$POP2017
dadosT <- data.frame(Population = pop, CasosPop = casos / pop)
dadosT <- dadosT |>
mutate(
RIE = CasosPop / (sum(casos) / sum(pop)) # Calcula o RIE
)
dadosT |>
head(3) Population CasosPop RIE
1 10479.088 0 0
2 5469.505 0 0
3 25128.464 0 0Criando mapas com shapefile
Vamos agora criar classes para categorizar os valores do Risco Relativo e criar nosso mapa com as informações.
# ---- Criar intervalo de classes
classes <- c(-Inf, 0.00000000001, 0.49999999999, 0.99999999999, 1.49999999999, 1.99999999999, Inf)
# ---- Criar legenda
legenda = c('0','0,0--0,5','0,5|--1,0','1,0|--1,5','1,5|--2,0','2,0 ou +')
cores <- c("#ffffff", "#f1f1d1", "#e9e57f", "#cda300", "#a46500", "#593216")
# ---- Adicionando a variável Risco Relativo ao shapefile
dados_mapa_shp <- dados_mapa_shp |>
mutate(
RIE = dadosT$RIE, # Adiciona o cálculo ao shapefile
classe_var = cut(RIE, breaks = classes, include.lowest = TRUE) # Cria classes
)Criando mapas com shapefile
# ---- Plot com ggplot2
mapa_shp <- ggplot(data = dados_mapa_shp) +
geom_sf(aes(fill = classe_var), color = "black") + # Preenchimento e bordas
scale_fill_manual(values = cores, labels = legenda) + # Aplica cores e legenda
labs(
x = "Longitude",
y = "Latitude",
fill = "Risco Relativo" # Nome da legenda
) +
annotation_custom(
grob = compassRoseGrob(x = 0.9, y = 0.9, rot = 0, cex = 2, scale = 0.5),
xmin = -Inf, xmax = Inf, ymin = -Inf, ymax = Inf
)+
theme_minimal() +
theme(
panel.grid = element_blank(), # Remove grade
panel.border = element_rect(color = "black", fill = NA) # Adiciona borda
)Criando mapas com shapefile
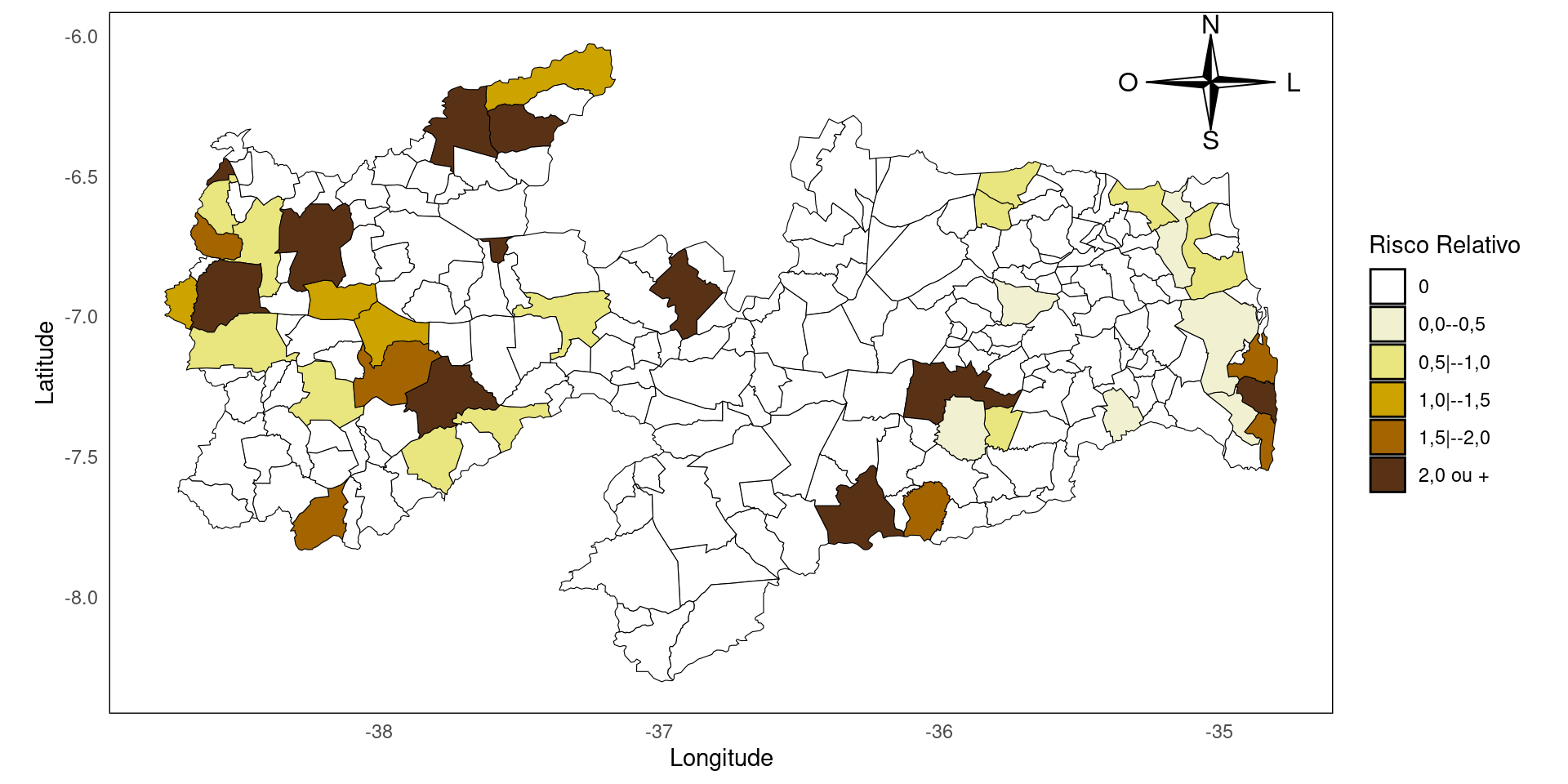
Criando mapas com leaflet
Vamos utilizar nesse caso dados de COVID–19, que vamos obter através do pacote coronabr. Instalando os pacotes necessários:
Lendo os pacotes para pegarmos os dados e gerar o mapa:
Vamos obter os dados pelo pacote
Criando mapas com leaflet
Agora, o próximo passo é agrupar por município, ler o shapefile e ordenar os municípios da mesma ordem do shapefile.
# Agrupando os dados por cidade
dados_pb2 <- dados_pb |>
select(c(city,new_confirmed )) |>
group_by(city) |>
summarise(n = sum(new_confirmed))
# ---- Load shapefile
shapename <- read_sf('dados/shape_estado_pb/Municipios.shp')
# Vamos associar os casos com convertendo 'nomes' para utilizar o left_join
nomes <- data.frame(city = toupper(shapename$NOME_MUNIC))
dados_grafico <- left_join(nomes,dados_pb2,by = "city")
dados_grafico |>
head(3) city n
1 ÁGUA BRANCA 1128
2 AGUIAR 528
3 ALAGOA GRANDE 4117Criando mapas com leaflet
Vamos criar intervalos para nosso iterpretar os resultados e fazer o plot do mapa
# Selecionando a variável de Interesse
casos_covid <- dados_grafico$n
# Substituindo os NA's
casos_covid[is.na(casos_covid)] <- 0
#Criando os Intervalos para a Legenda
classes = c(-Inf, 209, 414,619,819,1029, 1234, Inf)
classes_plot <- findInterval(casos_covid,classes)
# Criar legenda
legenda = c('0 |-- 210',
'210 |-- 415',
'415 |-- 620',
'620 |-- 820',
'820 |-- 1030',
'1030 |-- 1235',
'1235 ou mais')Criando mapas com leaflet
Vamos definir as cores e a função do leaflet
# Selecionando as cores de cada classe
cores = c("#ffffff",
"#f1f1d1",
"#e9e57f",
"#dcca03",
"#cda300",
"#a46500",
"#593216")
# Gerando o grafico
mapa_leaflet <- leaflet(shapename) |>
addTiles() |>
addPolygons(stroke = T,
smoothFactor = 0.3,
color = "black",opacity = 1,weight = 1,
fillOpacity = 1,
fillColor = cores[classes_plot],
label = ~paste0(shapename$NOME_MUNIC, ": ", format(casos_covid))) |>
addLegend(position = "topright",colors = cores, labels = legenda, title = "Quantidade de Casos" )Criando mapas com leaflet
Criando mapas com leaflet
Se desejar salvar seu gráfico gerado, isso pode ser feito de duas formas, ou salvar em .png ou salvar em .html, que fica mais interessante, pois possui interação com usuário como o gráfico mostrado no início deste post. A seguir é mostrado as duas formas de salvar:
relembrando os mapas…
Criando mapas com geobr
Criando mapas com shapefile
Criando mapas com leaflet
Referências
Burrough, Peter A. “Principles of geographical.” Information systems for land resource assessment. Clarendon Press, Oxford (1986).
Lovelace, Robin, Jakub Nowosad, and Jannes Muenchow. Geocomputation with R. Chapman and Hall/CRC, 2019.https://r.geocompx.org/
Livro: R for Data Science. Disponível em: https://r4ds.had.co.nz/
Livro: R for Data Science. Disponível em: https://ggplot2-book.org/
Repositório GitHub GGPLOT2: R for Data Science. Disponível em: https://github.com/tidyverse/ggplot2
Repositório GitHub elisangelalizzi: Apresentação visual de dados espaciais em saúde pública para vigilância epidemiológica. Disponível em: https://github.com/elisangelalizzi/Spatial-Visual/
Referências
Fontes das imagens utilizadas:
OBRIGADO!
Slide produzido com quarto
Lattes: http://lattes.cnpq.br/4617170601890026
LinkedIn: jodavidferreira
Site Pessoal: https://jodavid.github.io/
e-mail: jodavid.ferreira@ufpe.br
![]()
Introdução ao R aplicado ao Geoprocessamento - Jodavid Ferreira