GEMINI
utilização da GenAI (IA Generativa) do Google para interpretação de imagens com contexto estatístico
Evolução da IA
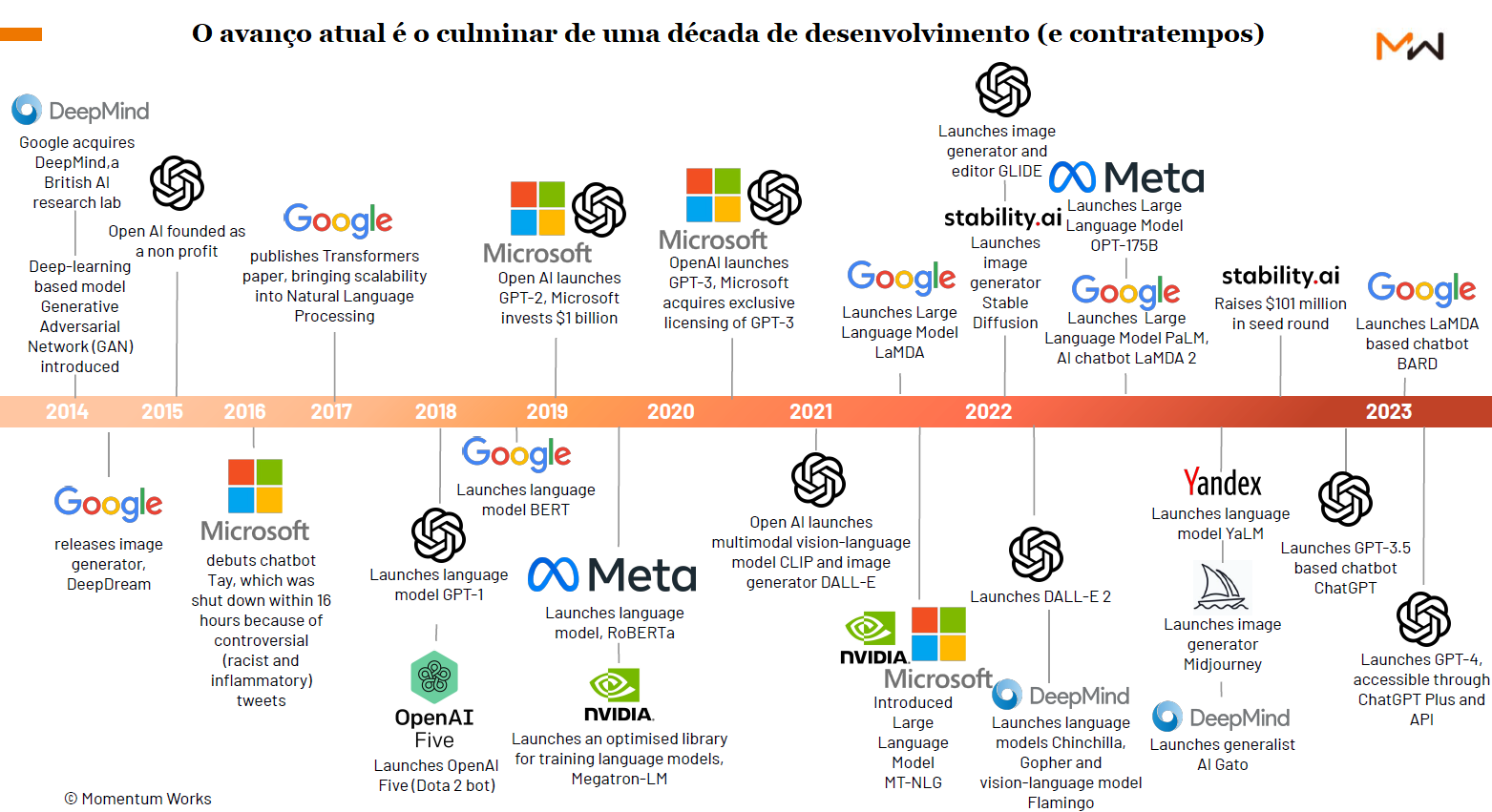
Inteligência Artificial
Exemplo de IA Simbólica:
- Sistemas Especialistas
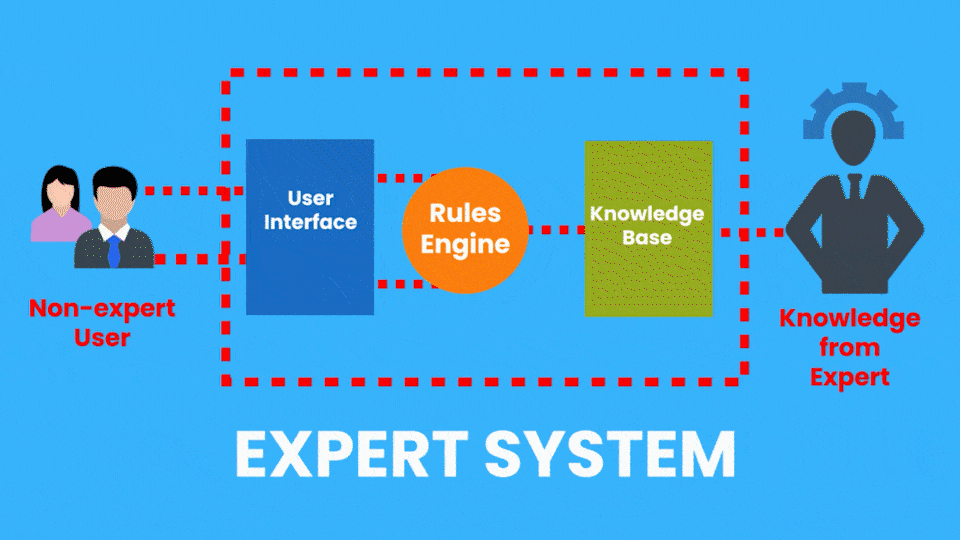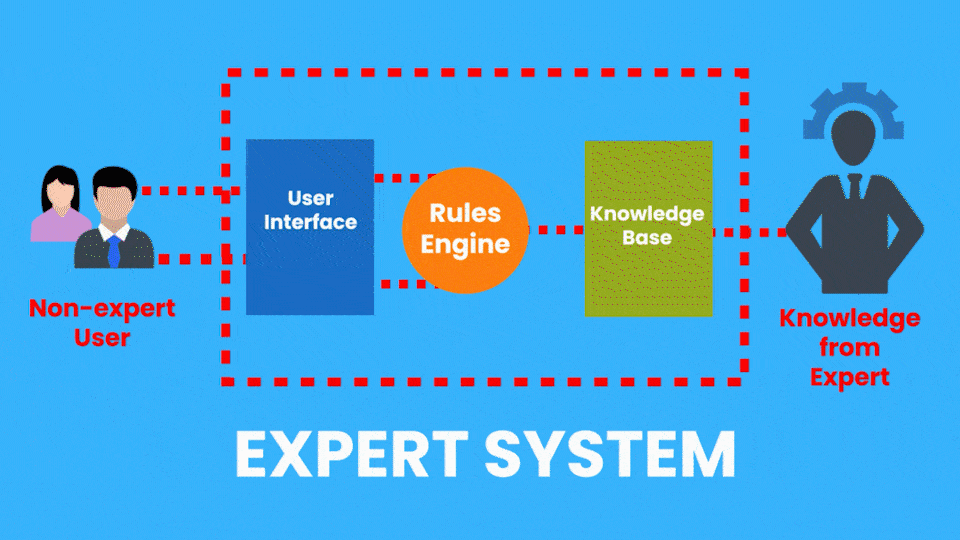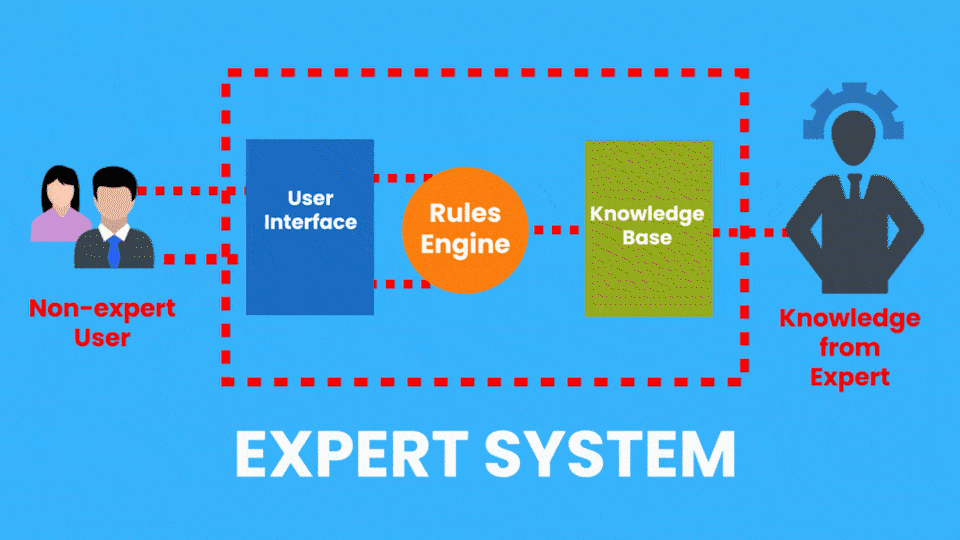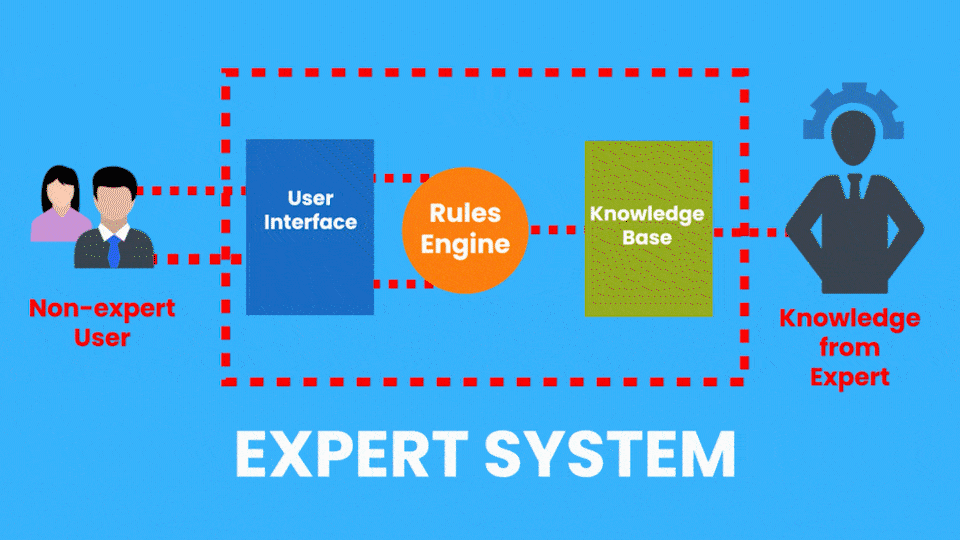
Exemplo de IA Conexionista
- Redes Neurais - CNN
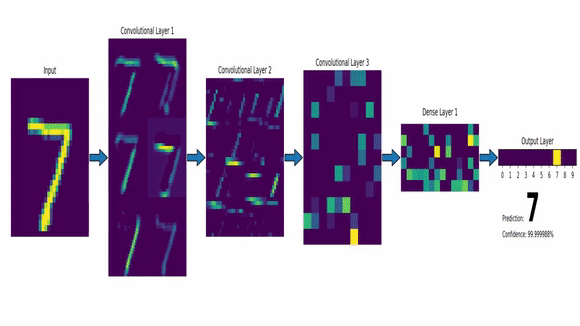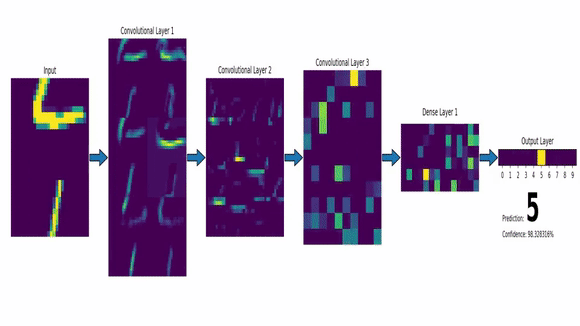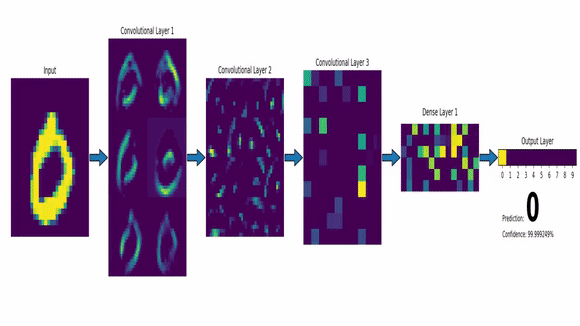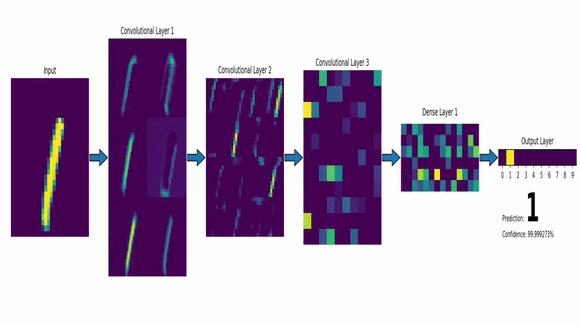
Inteligência Artificial
(fonte: AI Experience - Google)
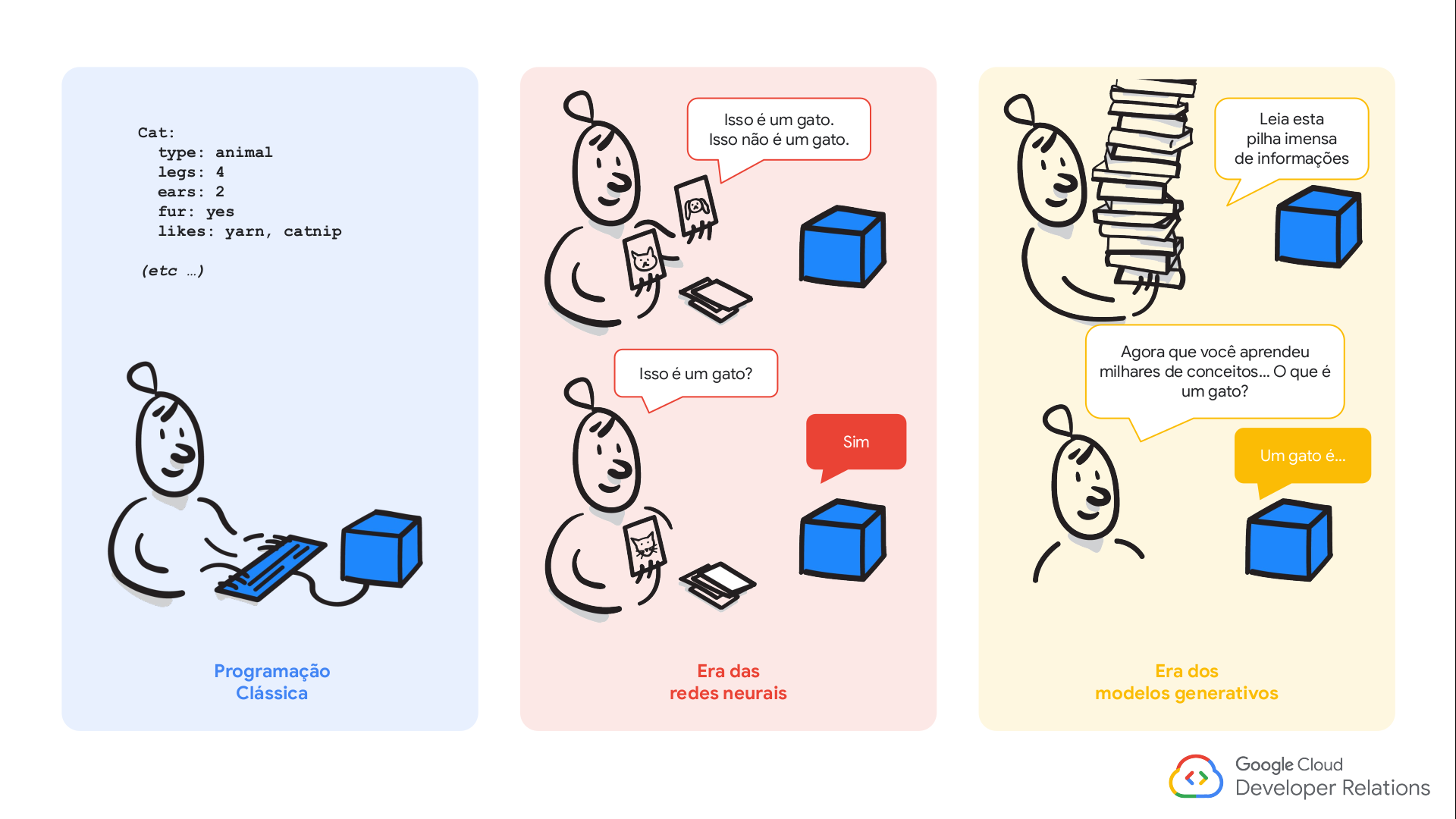
Introdução à Inteligência Artificial
Algunas informações sobre os modelos:

Legenda:

Os “dados de treinamento especial” são conjuntos de dados de alta qualidade, cuidadosamente selecionados e organizados. Eles podem incluir dados diversificados e representativos, dados enriquecidos com anotações ou metadados, dados sintéticos, e dados privados ou proprietários. Esses dados são valiosos para criar modelos mais precisos e especializados, capazes de entender nuances e aplicar conhecimento em contextos específicos, como saúde, direito, ou finanças.
Inteligência Artificial - GEMINI
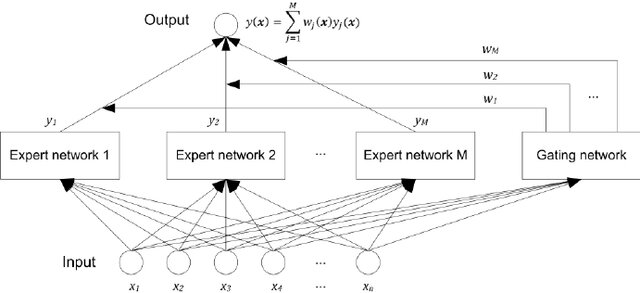
GEMINI assim como os modelos atuais, utilizam MoE - Mixtures of Experts, que são modelos que combinam várias redes neurais especializadas em tarefas específicas.
- Essas redes podem ser treinadas separadamente e depois combinadas para formar um modelo maior e mais poderoso.
- Assim, se cada modelo for treinado para uma especialidade diferente, o modelo combinado pode ser mais eficaz do que qualquer um dos modelos individuais e será considerado um modelo multimodal.
Inteligência Artificial - GEMINI
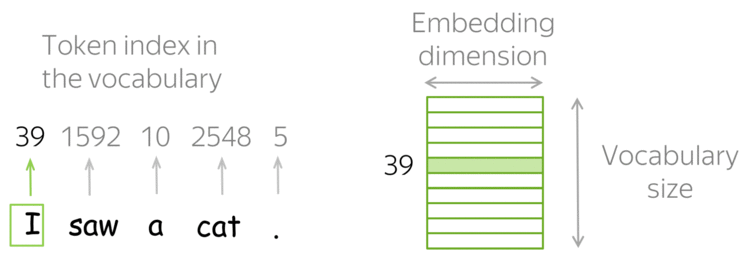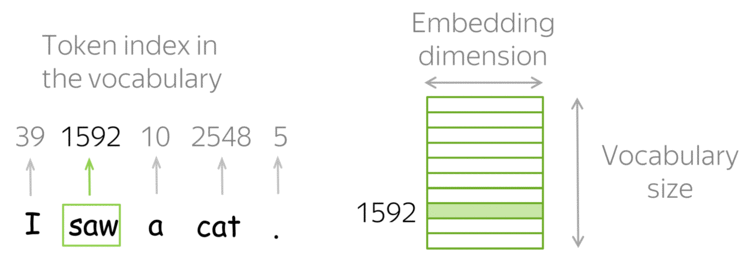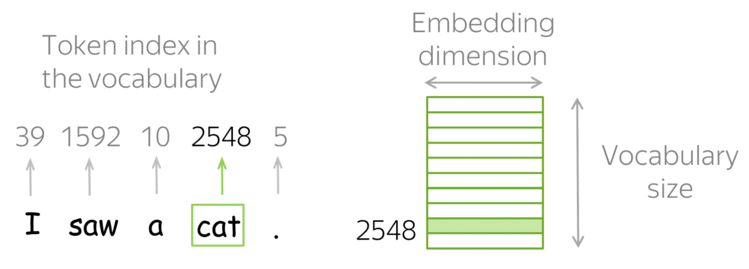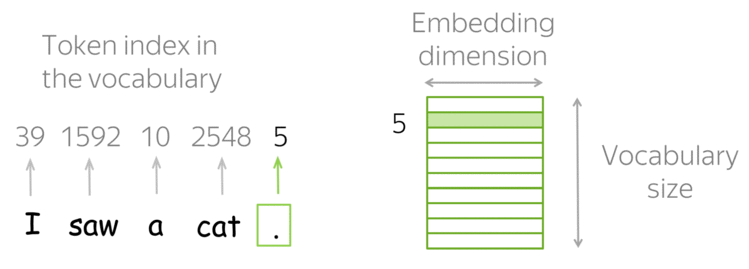
- Tokens e Embeddings são a base de qualquer modelo de IA, e o GEMINI não é diferente.
- Tokens são a menor unidade de texto que um modelo de IA pode processar.
- Embeddings são vetores numéricos que representam palavras, frases ou documentos.
Em 1.000 tokens de palavras em português correspondem aproximadamente a 700 a 750 palavras. Entretanto, a contagem de palavras em um texto pode variar bastante dependendo da linguagem, do tamanho das palavras e do uso de pontuações.
Inteligência Artificial - GEMINI
![]()
Inteligência Artificial - GEMINI
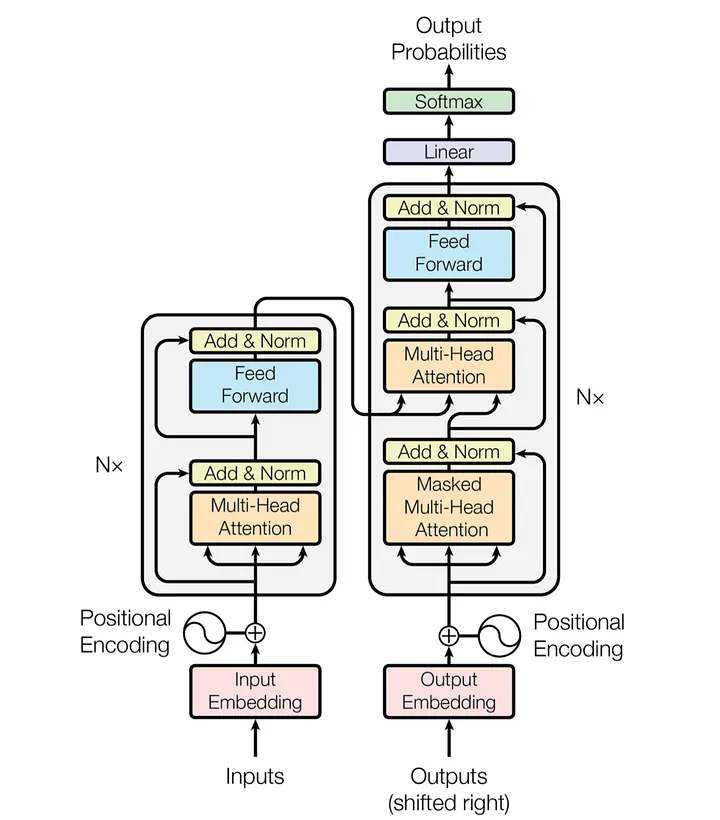
Alguns conceitos importantes quando se trabalha com algoritmos de LLMs, são:
Tokenização: Os dados de entrada são divididos em tokens, focando em texto, é a associação de número inteiro único para cada palavra ou sub-palavra;
Embedding: cada token é transformado em um vetor denso (embedding);
Camadas de Encoder: são responsáveis por processar e refinar os embeddings;
Self-Attention Mechanism: Cada token na sequência avalia a importância de todos os outros tokens, permitindo a incorporação de contexto global em cada embedding.
Saída do Encoder: O resultado das camadas de encoder é um conjunto de embeddings contextuais, onde cada token embedding contém informações sobre todo o contexto da sequência.
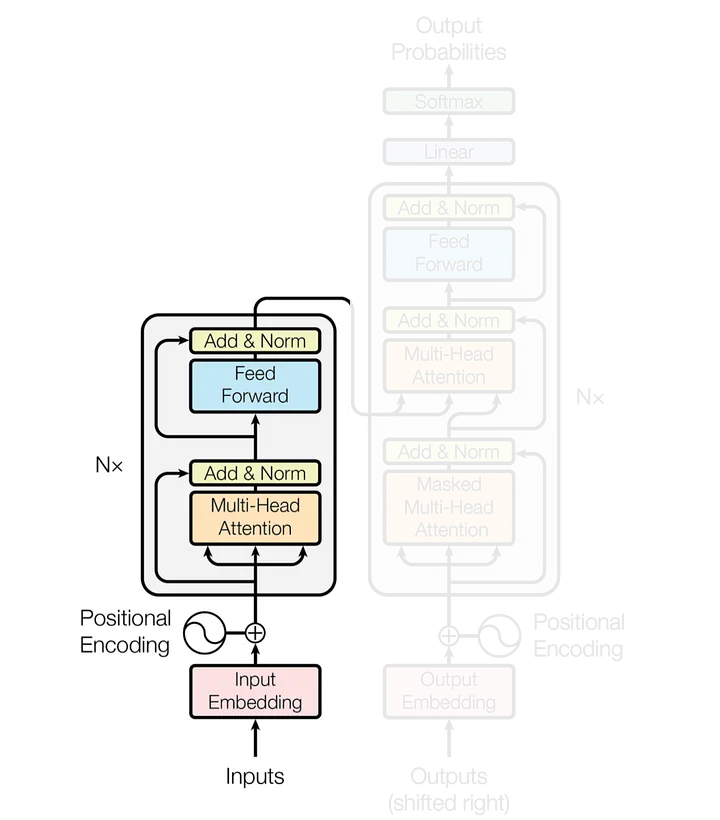
Inteligência Artificial - GEMINI
Alguns conceitos importantes quando se trabalha com algoritmos de LLMs, são:
Preparação da Entrada do Decoder: A entrada do decoder é preparada os embeddings contextuais do encoder;
Camada de Self-Attention do Decoder: Semelhante ao encoder, o decoder usa múltiplas cabeças de atenção para capturar diferentes aspectos da relação entre tokens, mas respeitando a ordem causal;
Camada de Atenção Encoder-Decoder: A camada de atenção encoder-decoder permite que o decoder se concentre em diferentes partes da entrada do encoder, dependendo do token que está sendo gerado.
Saída do Decoder: O resultado do decoder é um conjunto de embeddings contextuais finais, que são usados para prever o próximo token na sequência de saída.
Predição do Próximo Token: O modelo prediz o próximo token na sequência de saída com base nos embeddings contextuais finais.
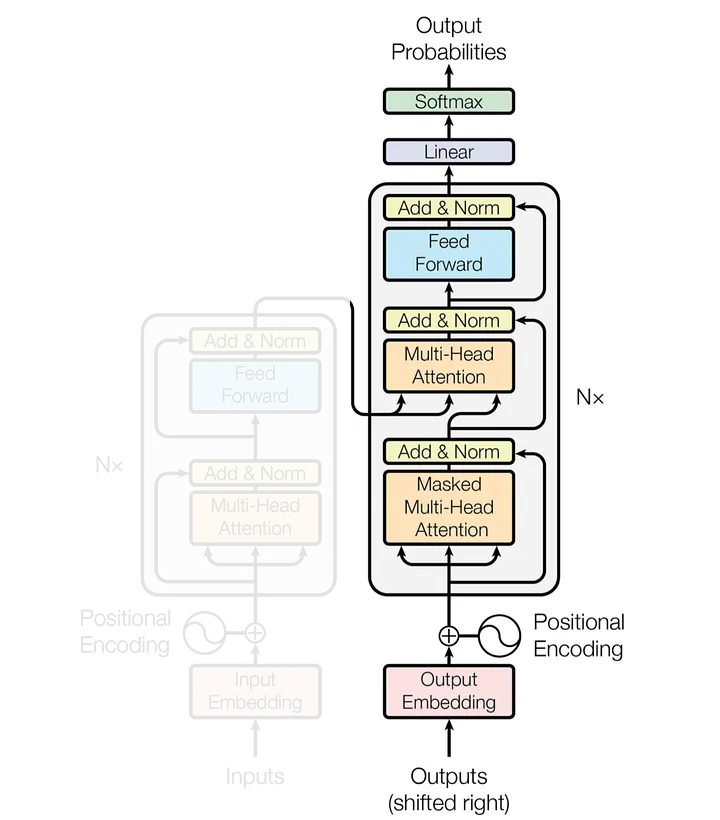
Inteligência Artificial - GEMINI

Inteligência Artificial - GEMINI
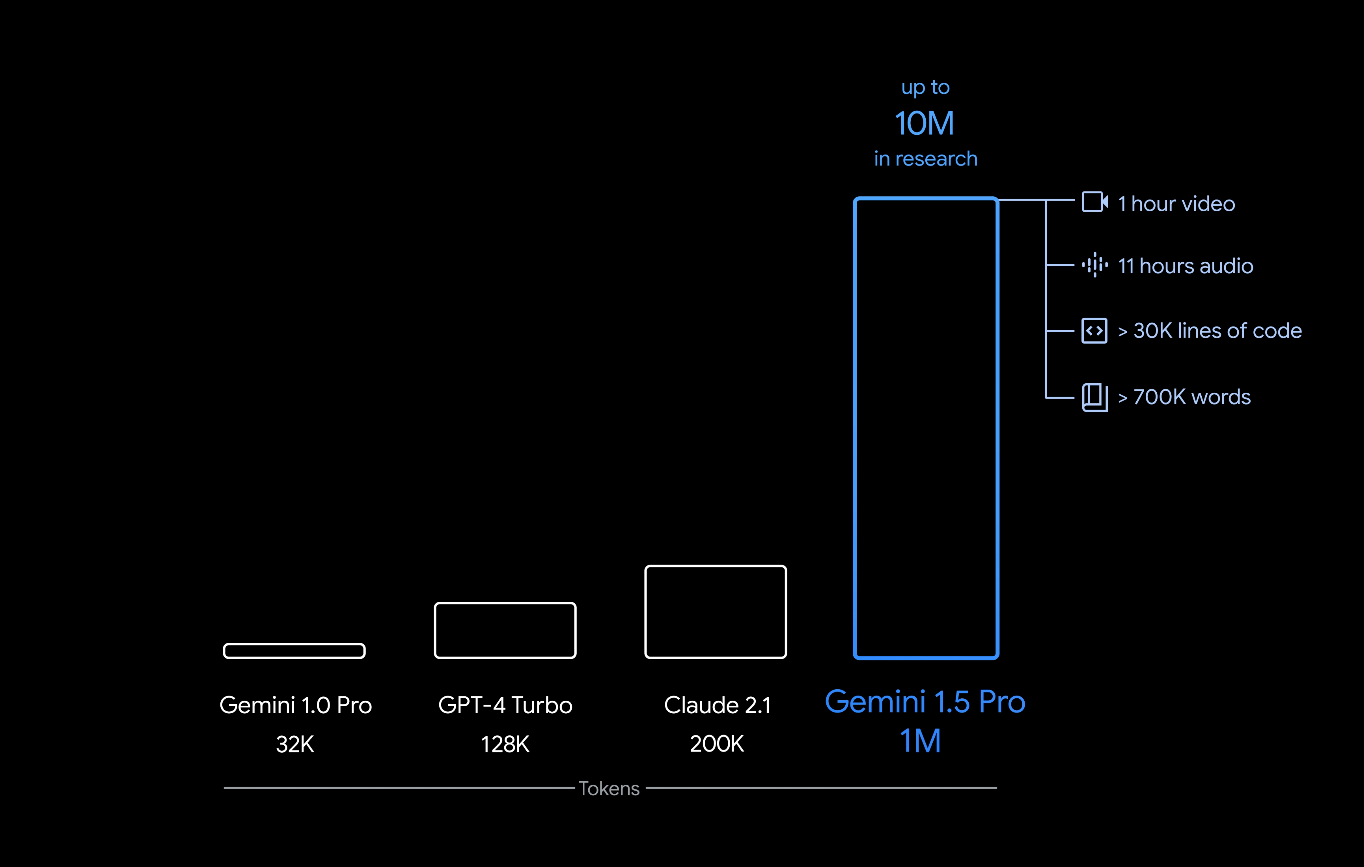
Inteligência Artificial - Aplicações
Aplicação 1 - Correlação
- prompt de entrada: “O que representa a imagem acima? Faça um resumo sobre a imagem com contexto estatístico.”
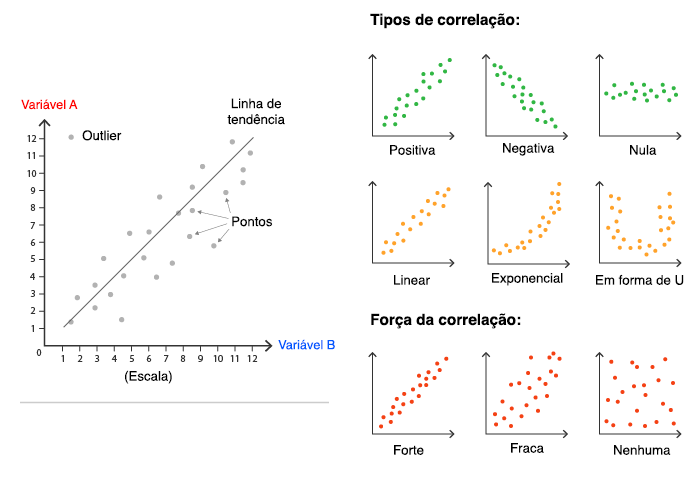
Inteligência Artificial
Aplicação 1 - Correlação
A imagem acima representa uma análise de correlação entre duas variáveis, A e B. A correlação é uma medida estatística que mostra a relação entre duas variáveis. Ela pode ser positiva, negativa ou nula. Uma correlação positiva significa que as duas variáveis estão relacionadas de forma direta, ou seja, quando uma variável aumenta, a outra também aumenta. Uma correlação negativa significa que as duas variáveis estão relacionadas de forma inversa, ou seja, quando uma variável aumenta, a outra diminui. Uma correlação nula significa que não há relação entre as duas variáveis.
A imagem também mostra os diferentes tipos de correlação. A correlação linear é uma relação linear entre duas variáveis, ou seja, os pontos no gráfico formam uma linha reta. A correlação exponencial é uma relação exponencial entre duas variáveis, ou seja, os pontos no gráfico formam uma curva exponencial. A correlação em forma de U é uma relação em forma de U entre duas variáveis, ou seja, os pontos no gráfico formam uma curva em forma de U.
A imagem também mostra a força da correlação. A força da correlação é medida pelo coeficiente de correlação, que pode variar de -1 a 1. Um coeficiente de correlação de 1 indica uma correlação positiva perfeita, um coeficiente de correlação de -1 indica uma correlação negativa perfeita e um coeficiente de correlação de 0 indica uma correlação nula.
A análise de correlação é uma ferramenta útil para entender a relação entre duas variáveis. Ela pode ser usada para identificar relações positivas, negativas ou nulas, bem como a força da correlação.
Inteligência Artificial
Aplicação 2 - Distribuição de Probabilidade Normal
- prompt de entrada:
- “O que você identifica na imagem acima?”
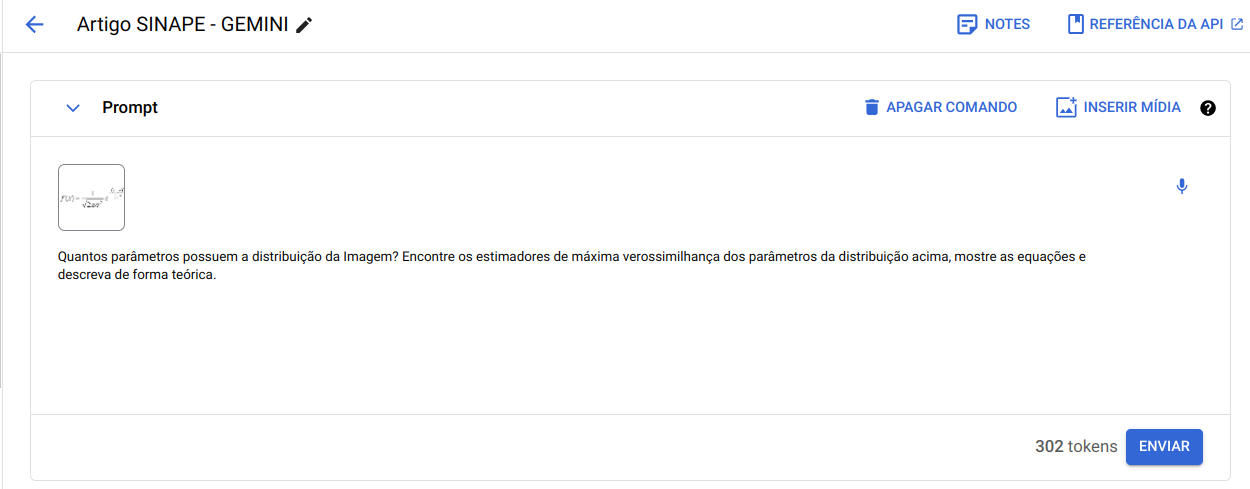
- “Quantos parâmetros possuem a distribuição da imagem? Encontre os estimadores de máxima verossimihança dos parâmetros da distribuição acima, mostre as equações e descreva de forma teórica.”
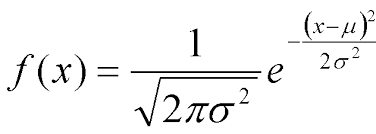
Inteligência Artificial
Aplicação 2 - Distribuição de Probabilidade Normal
Inteligência Artificial - LLMs
Duas alternativas para mitigar esses problemas são:
Fine-Tuning: ajustar o modelo para um conjunto de dados específico, para que ele possa aprender a tarefa desejada;
RAG (Retrieve and Generate): que é um modelo que combina a capacidade de recuperar informações de um grande banco de dados com a capacidade de gerar texto de um modelo de linguagem.
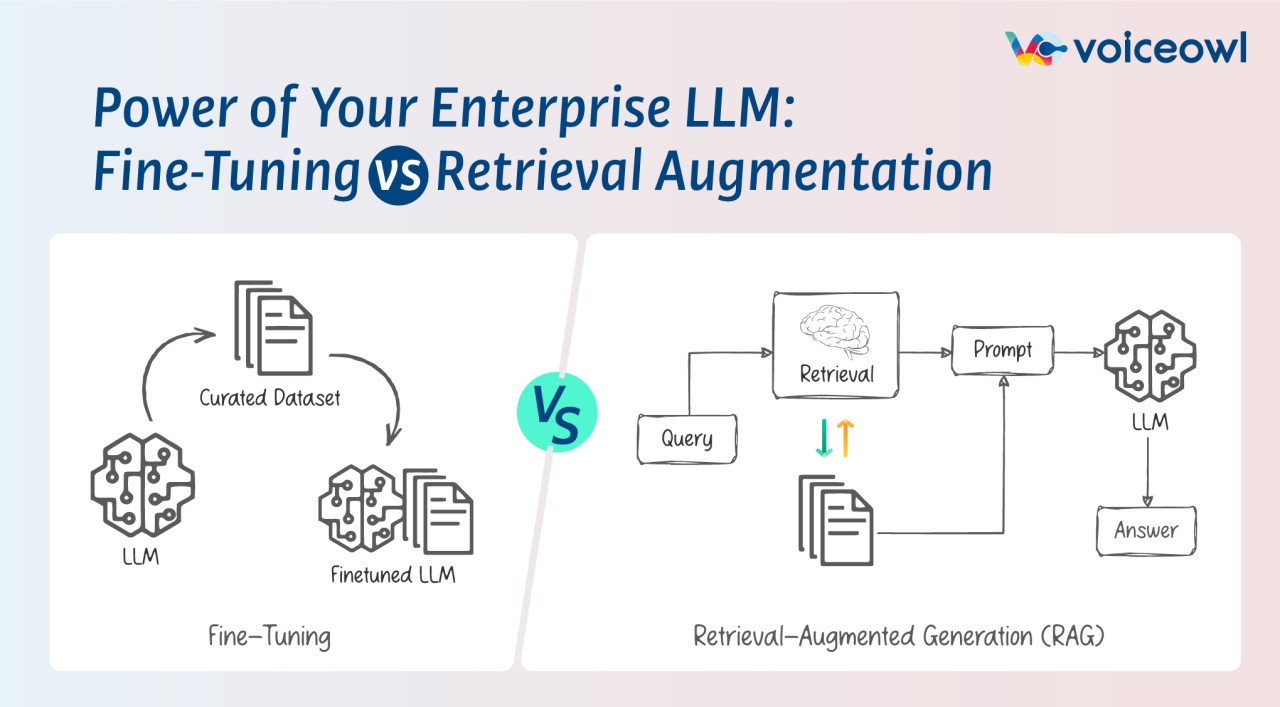
- A batalha de dados está sendo um desafio de desenvolvimento com IA Generativa:

Referências
Reid, Machel, et al. (2024). Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530 .
Vaswani, A., N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin (2017). Attention is all you need. Advances in neural information processing systems 30.
Devlin, J., M.-W. Chang, K. Lee, and K. Toutanova (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
Hirschberg, J. and C. D. Manning (2015). Advances in natural language processing. Sci- ence 349 (6245), 261–266.
OBRIGADO!
Slide produzido com quarto
Lattes: http://lattes.cnpq.br/4617170601890026
LinkedIn: jodavidferreira
Site Pessoal: https://jodavid.github.io/
e-mail: jodavid.ferreira@ufpe.br
![]()